
6 Jenis Fungsi Aktivasi di Jaringan Syaraf Tiruan Yang Perlu Anda Ketahui
Diterbitkan: 2020-02-13Dengan Deep Learning menjadi teknologi mainstream, akhir-akhir ini banyak dibicarakan tentang ANN atau Jaringan Syaraf Tiruan. Saat ini, ANN adalah komponen inti dalam beragam domain yang muncul seperti pengenalan tulisan tangan, kompresi gambar, prediksi bursa saham, dan banyak lagi. Baca lebih lanjut tentang jenis jaringan saraf tiruan dalam pembelajaran mesin.
Tapi apa itu Jaringan Syaraf Tiruan?
Jaringan Syaraf Tiruan adalah model Deep Learning yang mengambil inspirasi dari struktur syaraf otak manusia. JST telah dirancang untuk meniru fungsi otak manusia yang belajar dari pengalaman dan beradaptasi sesuai dengan situasi. Seperti halnya otak manusia yang memiliki struktur bertingkat yang mengandung miliaran neuron yang tersusun dalam suatu hierarki, JST juga memiliki jaringan neuron yang saling berhubungan satu sama lain melalui akson.
Neuron yang saling berhubungan ini meneruskan sinyal listrik (disebut sinapsis) dari satu lapisan ke lapisan lainnya. Peniruan pemodelan otak ini memungkinkan JST untuk belajar dari pengalaman tanpa memerlukan campur tangan manusia.
Baca: Jaringan Syaraf Tiruan di Data Mining
Dengan demikian, JST adalah struktur kompleks yang mengandung elemen adaptif yang saling berhubungan yang dikenal sebagai neuron buatan yang dapat melakukan komputasi besar untuk representasi pengetahuan. Mereka memiliki semua kualitas dasar dari sistem neuron biologis, termasuk kemampuan belajar, ketahanan, non-linier, paralelisme tinggi, toleransi kesalahan dan kegagalan, kemampuan untuk menangani informasi yang tidak tepat dan kabur, dan kemampuan menggeneralisasi.

Bergabunglah dengan Kursus Kecerdasan Buatan online dari Universitas top Dunia - Magister, Program Pascasarjana Eksekutif, dan Program Sertifikat Tingkat Lanjut di ML & AI untuk mempercepat karier Anda.
Daftar isi
Karakteristik Inti Jaringan Syaraf Tiruan
- Non-linearitas memberikan kecocokan yang lebih baik untuk data.
- Paralelisme tinggi mendorong pemrosesan cepat dan toleransi kegagalan perangkat keras.
- Generalisasi memungkinkan penerapan model pada data yang tidak dipelajari.
- Ketidakpekaan kebisingan yang memungkinkan prediksi akurat bahkan untuk data yang tidak pasti dan kesalahan pengukuran.
- Pembelajaran dan adaptasi memungkinkan model untuk memperbarui arsitektur internalnya sesuai dengan lingkungan yang berubah.
Komputasi berbasis JST terutama bertujuan untuk merancang algoritma matematika canggih yang memungkinkan Jaringan Syaraf Tiruan untuk belajar dengan meniru fungsi pemrosesan informasi dan akuisisi pengetahuan dari otak manusia.
Komponen Jaringan Syaraf Tiruan
JST terdiri dari tiga lapisan inti atau fase – lapisan input, lapisan tersembunyi, dan lapisan output.
- Input Layer: Lapisan pertama diumpankan dengan input, yaitu data mentah. Ini menyampaikan informasi dari dunia luar ke jaringan. Di lapisan ini, tidak ada perhitungan yang dilakukan - node hanya meneruskan informasi ke lapisan tersembunyi.
- Lapisan Tersembunyi: Di lapisan ini, node terletak tersembunyi di balik lapisan input – mereka terdiri dari bagian abstraksi di setiap jaringan saraf. Semua komputasi pada fitur yang dimasukkan melalui lapisan input terjadi di lapisan tersembunyi, dan kemudian, mentransfer hasilnya ke lapisan output.
- Output Layer: Lapisan ini menggambarkan hasil komputasi yang dilakukan oleh jaringan ke dunia luar.
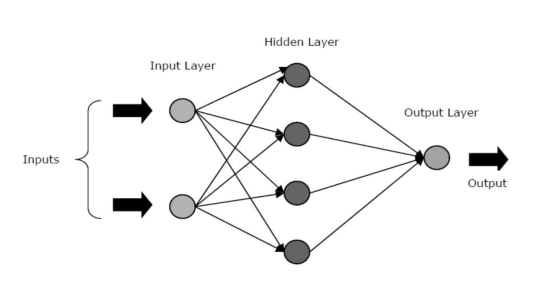
Sumber
Jaringan saraf dapat dikategorikan ke dalam jenis yang berbeda berdasarkan aktivitas lapisan tersembunyi. Misalnya, dalam jaringan saraf sederhana, unit tersembunyi dapat membangun representasi unik mereka dari input. Di sini, bobot antara unit tersembunyi dan unit input menentukan kapan setiap unit tersembunyi aktif.
Jadi, dengan menyesuaikan bobot ini, lapisan tersembunyi dapat memilih apa yang harus diwakilinya. Arsitektur lainnya termasuk model single layer dan multilayer. Dalam satu lapisan, biasanya hanya ada lapisan input dan output – tidak memiliki lapisan tersembunyi. Sedangkan pada model multilayer terdapat satu atau lebih dari satu hidden layer.
Apa Fungsi Aktivasi di Neural Network?
Seperti yang kami sebutkan sebelumnya, JST adalah komponen penting dari banyak struktur yang membantu merevolusi dunia di sekitar kita. Namun pernahkah Anda bertanya-tanya, bagaimana ANN memberikan kinerja mutakhir untuk menemukan solusi masalah dunia nyata?
Jawabannya adalah – Fungsi Aktivasi.
JST menggunakan fungsi aktivasi (AFs) untuk melakukan perhitungan kompleks di lapisan tersembunyi dan kemudian mentransfer hasilnya ke lapisan output. Tujuan utama AF adalah untuk memperkenalkan properti non-linier dalam jaringan saraf.
Mereka mengubah sinyal input linier dari sebuah node menjadi sinyal output non-linear untuk memfasilitasi pembelajaran polinomial orde tinggi yang melampaui satu derajat untuk jaringan yang dalam. Aspek unik dari AF adalah bahwa mereka dapat dibedakan – ini membantu mereka berfungsi selama backpropagation dari jaringan saraf.
Apa perlunya non-linier?
Jika fungsi aktivasi tidak diterapkan, sinyal keluaran akan menjadi fungsi linier, yang merupakan polinomial satu derajat. Meskipun mudah untuk menyelesaikan persamaan linier, persamaan tersebut memiliki hasil bagi kompleksitas yang terbatas dan karenanya, memiliki daya yang lebih kecil untuk mempelajari pemetaan fungsional yang kompleks dari data. Jadi, tanpa AF, jaringan saraf akan menjadi model regresi linier dengan kemampuan terbatas.
Ini tentu bukan yang kita inginkan dari jaringan saraf. Tugas jaringan saraf adalah untuk menghitung perhitungan yang sangat rumit. Selain itu, tanpa AF, jaringan saraf tidak dapat mempelajari dan memodelkan data rumit lainnya, termasuk gambar, ucapan, video, audio, dll.
AF membantu jaringan saraf untuk memahami kumpulan Data Besar yang rumit, berdimensi tinggi, dan non-linier yang memiliki arsitektur rumit – mereka berisi beberapa lapisan tersembunyi di antara lapisan input dan output.
Baca: Deep Learning Vs Neural Network
Sekarang, tanpa basa-basi lagi, mari selami berbagai jenis fungsi aktivasi yang digunakan di ANN.
Jenis Fungsi Aktivasi
1. Fungsi Sigmoid
Dalam JST, fungsi sigmoid adalah AF non-linear yang digunakan terutama dalam jaringan saraf feedforward. Ini adalah fungsi nyata yang dapat diturunkan, didefinisikan untuk nilai input nyata, dan mengandung turunan positif di mana-mana dengan tingkat kehalusan tertentu. Fungsi sigmoid muncul di lapisan keluaran model pembelajaran mendalam dan digunakan untuk memprediksi keluaran berbasis probabilitas. Fungsi sigmoid direpresentasikan sebagai:
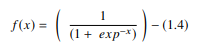
Sumber
Umumnya, turunan dari fungsi sigmoid diterapkan pada algoritma pembelajaran. Grafik fungsi sigmoid berbentuk 'S'.
Beberapa kelemahan utama dari fungsi sigmoid termasuk saturasi gradien, konvergensi lambat, gradien lembab yang tajam selama propagasi balik dari dalam lapisan tersembunyi yang lebih dalam ke lapisan input, dan output terpusat yang tidak nol yang menyebabkan pembaruan gradien menyebar ke berbagai arah.

2. Fungsi Tangen Hiperbolik (Tanh)
Fungsi tangen hiperbolik, alias, fungsi tanh, adalah jenis lain dari AF. Ini adalah fungsi yang lebih halus dan berpusat pada nol yang memiliki rentang antara -1 hingga 1. Akibatnya, output dari fungsi tanh diwakili oleh:
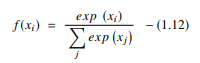
Sumber
Fungsi tanh jauh lebih banyak digunakan daripada fungsi sigmoid karena memberikan kinerja pelatihan yang lebih baik untuk jaringan saraf multilayer. Keuntungan terbesar dari fungsi tanh adalah menghasilkan keluaran yang berpusat pada nol, sehingga mendukung proses propagasi balik. Fungsi tanh telah banyak digunakan dalam jaringan saraf berulang untuk pemrosesan bahasa alami dan tugas pengenalan suara.
Namun, fungsi tanh juga memiliki keterbatasan – seperti fungsi sigmoid, ia tidak dapat menyelesaikan masalah gradien hilang. Juga, fungsi tanh hanya dapat mencapai gradien 1 ketika nilai inputnya adalah 0 (x adalah nol). Akibatnya, fungsi tersebut dapat menghasilkan beberapa neuron mati selama proses komputasi.
3. Fungsi Softmax
Fungsi softmax adalah jenis AF lain yang digunakan dalam jaringan saraf untuk menghitung distribusi probabilitas dari vektor bilangan real. Fungsi ini menghasilkan output yang berkisar antara nilai 0 dan 1 dan dengan jumlah probabilitas sama dengan 1. Fungsi softmax direpresentasikan sebagai berikut:
Sumber
Fungsi ini terutama digunakan dalam model multi-kelas di mana ia mengembalikan probabilitas setiap kelas, dengan kelas target memiliki probabilitas tertinggi. Itu muncul di hampir semua lapisan keluaran arsitektur DL di mana mereka digunakan. Perbedaan utama antara AF sigmoid dan softmax adalah bahwa sementara yang pertama digunakan dalam klasifikasi biner, yang terakhir digunakan untuk klasifikasi multivariat.
4. Fungsi Softsign
Fungsi softsign adalah AF lain yang digunakan dalam komputasi jaringan saraf. Meskipun terutama dalam masalah perhitungan regresi, saat ini juga digunakan dalam aplikasi text-to-speech berbasis DL. Ini adalah polinomial kuadrat, diwakili oleh:
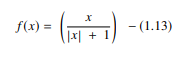
Sumber
Di sini "x" sama dengan nilai absolut dari input.
Perbedaan utama antara fungsi softsign dan fungsi tanh adalah bahwa tidak seperti fungsi tanh yang konvergen secara eksponensial, fungsi softsign konvergen dalam bentuk polinomial.
5. Fungsi Rectified Linear Unit (ReLU)
Salah satu AF paling populer dalam model DL, fungsi rectified linear unit (ReLU), adalah AF pembelajaran cepat yang menjanjikan kinerja mutakhir dengan hasil yang luar biasa. Dibandingkan dengan AF lain seperti fungsi sigmoid dan tanh, fungsi ReLU menawarkan kinerja dan generalisasi yang jauh lebih baik dalam pembelajaran mendalam. Fungsi tersebut adalah fungsi yang hampir linier yang mempertahankan properti model linier, yang membuatnya mudah untuk dioptimalkan dengan metode gradien-turunan.
Fungsi ReLU melakukan operasi ambang batas pada setiap elemen input di mana semua nilai kurang dari nol diatur ke nol. Dengan demikian, ReLU direpresentasikan sebagai:
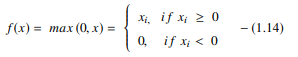
Sumber
Dengan memperbaiki nilai input kurang dari nol dan menyetelnya ke nol, fungsi ini menghilangkan masalah gradien hilang yang diamati pada jenis fungsi aktivasi sebelumnya (sigmoid dan tanh).
Keuntungan paling signifikan menggunakan fungsi ReLU dalam komputasi adalah menjamin komputasi yang lebih cepat – tidak menghitung eksponensial dan pembagian, sehingga meningkatkan kecepatan komputasi secara keseluruhan. Aspek penting lainnya dari fungsi ReLU adalah ia memperkenalkan sparity di unit tersembunyi dengan menekan nilai antara nol hingga maksimum.
6. Fungsi Unit Linear Eksponensial (ELUs)
Fungsi unit linier eksponensial (ELU) adalah AF yang juga digunakan untuk mempercepat pelatihan jaringan saraf (seperti fungsi ReLU). Keuntungan terbesar dari fungsi ELU adalah dapat menghilangkan masalah gradien hilang dengan menggunakan identitas untuk nilai-nilai positif dan dengan meningkatkan karakteristik pembelajaran model.
ELU memiliki nilai negatif yang mendorong aktivasi unit rata-rata mendekati nol, sehingga mengurangi kompleksitas komputasi dan meningkatkan kecepatan pembelajaran. ELU adalah alternatif yang sangat baik untuk ReLU – ini mengurangi pergeseran bias dengan mendorong aktivasi rata-rata menuju nol selama proses pelatihan.
Fungsi satuan linier eksponensial direpresentasikan sebagai:
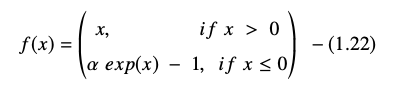
Turunan atau gradien persamaan ELU disajikan sebagai:
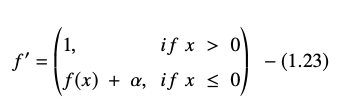
Sumber
Di sini “α” sama dengan hyperparameter ELU yang mengontrol titik jenuh untuk input bersih negatif, yang biasanya disetel ke 1,0. Namun, fungsi ELU memiliki keterbatasan – tidak terpusat pada nol.
Kesimpulan
Saat ini, AF seperti ReLU dan ELU telah mendapatkan perhatian maksimal karena membantu menghilangkan masalah gradien hilang yang menyebabkan masalah besar dalam proses pelatihan melatih dan menurunkan akurasi dan kinerja model jaringan saraf.
Lihat Program Sertifikasi Lanjutan dalam Pembelajaran Mesin & Cloud dengan IIT Madras, sekolah teknik terbaik di negara ini untuk membuat program yang mengajarkan Anda tidak hanya pembelajaran mesin tetapi juga penerapannya secara efektif menggunakan infrastruktur cloud. Tujuan kami dengan program ini adalah untuk membuka pintu institut paling selektif di negara ini dan memberi pelajar akses ke fakultas & sumber daya yang luar biasa untuk menguasai keterampilan yang tinggi & berkembang
Apa itu Jaringan Syaraf Tiruan?
ANN merupakan model Deep Learning yang terinspirasi dari struktur saraf otak manusia. JST diciptakan untuk meniru aktivitas otak manusia, yang belajar dari pengalaman mereka dan beradaptasi dengan lingkungan mereka. JST berisi jaringan neuron yang dihubungkan satu sama lain oleh akson, mirip dengan bagaimana pikiran manusia memiliki struktur multi-tier dengan miliaran neuron yang diatur dalam hierarki. Sinyal listrik (disebut sinapsis) dikirim dari satu lapisan ke lapisan berikutnya oleh neuron yang terhubung ini. JST dapat belajar dari pengalaman tanpa memerlukan keterlibatan manusia berkat pendekatan pemodelan otak ini.
Apa fungsi aktivasi dalam jaringan saraf?
JST menggunakan fungsi aktivasi (AFs) di lapisan tersembunyi untuk melakukan perhitungan kompleks dan kemudian mentransfer hasilnya ke lapisan output. Tujuan dasar AF adalah untuk memberikan kualitas jaringan saraf non-linear. Mereka mengubah sinyal input linier node menjadi sinyal output non-linear untuk membantu jaringan dalam mempelajari polinomial tingkat tinggi dengan lebih dari satu derajat. AF berbeda karena dapat dibedakan, yang membantu peran mereka selama backpropagation jaringan saraf.
Apa perlunya non-linier?
Jika tidak ada fungsi aktivasi yang digunakan, sinyal keluaran adalah transformasi linier, yang merupakan polinomial satu derajat. Meskipun persamaan linier mudah untuk dipecahkan, persamaan tersebut memiliki tingkat kompleksitas yang rendah, yang membatasi kemampuannya untuk mempelajari pemetaan yang rumit dari data. Jaringan saraf tanpa AF akan menjadi model linier umum dengan kemampuan terbatas. Ini bukan jenis kinerja yang kita inginkan dari jaringan saraf. Jaringan saraf digunakan untuk melakukan perhitungan yang sangat kompleks. Selain itu, jaringan saraf tidak dapat mempelajari dan mewakili data kompleks lainnya tanpa AF, seperti foto, suara, film, audio, dan sebagainya.