
Une intuition derrière l'analyse des sentiments : comment faire une analyse des sentiments à partir de zéro ?
Publié: 2020-12-07Table des matières
introduction
Le texte est le moyen le plus important de percevoir l'information pour les êtres humains. La majorité de l'intelligence acquise par les humains se fait par l'apprentissage et la compréhension du sens des textes et des phrases qui les entourent.
Après un certain âge, les humains développent un réflexe intrinsèque pour comprendre l'inférence de n'importe quel mot/texte sans même le savoir. Pour les machines, cette tâche est complètement différente. Pour assimiler le sens des textes et des phrases, les machines s'appuient sur les fondamentaux du traitement automatique du langage naturel (TAL).
L'apprentissage en profondeur pour le traitement du langage naturel est la reconnaissance de formes appliquée aux mots, aux phrases et aux paragraphes, de la même manière que la vision par ordinateur est la reconnaissance de formes appliquée aux pixels d'une image.
Aucun de ces modèles d'apprentissage en profondeur ne comprend vraiment le texte au sens humain ; au contraire, ces modèles peuvent cartographier la structure statistique du langage écrit, ce qui est suffisant pour résoudre de nombreuses tâches textuelles simples. L'analyse des sentiments est l'une de ces tâches, par exemple : classer le sentiment des chaînes ou des critiques de films comme positif ou négatif.
Ceux-ci ont également des applications à grande échelle dans l'industrie. Par exemple : une entreprise de biens et de services souhaite recueillir les données sur le nombre d'avis positifs et négatifs qu'elle a reçus pour un produit particulier afin de travailler sur le cycle de vie du produit, d'améliorer ses chiffres de vente et de recueillir les commentaires des clients.
Prétraitement
La tâche d'analyse des sentiments peut être décomposée en un simple algorithme d'apprentissage automatique supervisé, où nous avons généralement une entrée X , qui entre dans une fonction de prédiction pour obtenir Nous comparons ensuite notre prédiction avec la vraie valeur Y , Cela nous donne le coût que nous utilisons ensuite pour mettre à jour les paramètres Pour s'attaquer à la tâche d'extraire des sentiments d'un flux de textes inédits, l'étape primitive consiste à rassembler un ensemble de données étiqueté avec des sentiments positifs et négatifs séparés. Ces sentiments peuvent être : une bonne critique ou une mauvaise critique, une remarque sarcastique ou une remarque non sarcastique, etc.
L'étape suivante consiste à créer un vecteur de dimension V , où Ce vecteur de vocabulaire contiendra chaque mot (aucun mot n'est répété) présent dans notre ensemble de données et agira comme un lexique pour notre machine auquel il pourra se référer. Maintenant, nous prétraitons le vecteur de vocabulaire pour supprimer les redondances. Les étapes suivantes sont effectuées :
- Éliminer les URL et autres informations non triviales (qui n'aident pas à déterminer le sens d'une phrase)
- Tokenisation de la chaîne en mots : supposons que nous ayons la chaîne "J'aime l'apprentissage automatique", maintenant en tokenisant, nous décomposons simplement la phrase en mots simples et la stockons dans une liste sous la forme [I, love, machine, learning]
- Suppression des mots vides comme « et », « suis », « ou », « je », etc.
- Stemming : nous transformons chaque mot en sa forme radicale. Des mots comme «tune», «tuning» et «tuned» ont sémantiquement la même signification, donc les réduire à sa forme radicale qui est «tun» réduira la taille du vocabulaire
- Convertir tous les mots en minuscules
Pour résumer l'étape de prétraitement, examinons un exemple : disons que nous avons une chaîne positive « J'adore le nouveau produit sur upGrad.com » . La chaîne prétraitée finale est obtenue en supprimant l'URL, en segmentant la phrase en une seule liste de mots, en supprimant les mots vides tels que "je, suis, le, à", puis en radicalisant les mots "aimant" en "lov" et "produit" en "produ" et enfin en convertissant le tout en minuscules, ce qui donne la liste [lov, new, produ] .
Extraction de caractéristiques
Une fois le corpus prétraité, la prochaine étape consisterait à extraire les caractéristiques de la liste des phrases. Comme tous les autres réseaux de neurones, les modèles d'apprentissage en profondeur ne prennent pas de texte brut en entrée : ils fonctionnent uniquement avec des tenseurs numériques. La liste de mots prétraitée doit donc être convertie en valeurs numériques. Cela peut être fait de la manière suivante. Supposons que compte tenu d'une compilation de chaînes avec des chaînes positives et négatives telles que (supposons ceci comme jeu de données) :
| Chaînes positives | Chaînes négatives |
|
|
Maintenant, pour convertir chacune de ces chaînes en un vecteur numérique de dimension 3, nous créons un dictionnaire pour mapper le mot et la classe dans laquelle il est apparu (positif ou négatif) au nombre de fois que ce mot est apparu dans sa classe correspondante.
| Vocabulaire | Fréquence positive | Fréquence négative |
| je | 3 | 3 |
| un m | 3 | 3 |
| content | 2 | 0 |
| car | 1 | 0 |
| apprentissage | 1 | 1 |
| PNL | 1 | 1 |
| triste | 0 | 2 |
| ne pas | 0 | 1 |
Après avoir généré le dictionnaire susmentionné, nous examinons chacune des chaînes individuellement, puis additionnons le nombre de fréquences positives et négatives des mots qui apparaissent dans la chaîne en laissant les mots qui n'apparaissent pas dans la chaîne. Prenons la chaîne '"Je suis triste, je n'apprends pas la PNL" et générons le vecteur de dimension 3.

"Je suis triste, je n'apprends pas la PNL"
| Vocabulaire | Fréquence positive | Fréquence négative |
| je | 3 | 3 |
| un m | 3 | 3 |
| content | 2 | 0 |
| car | 1 | 0 |
| apprentissage | 1 | 1 |
| PNL | 1 | 1 |
| triste | 0 | 2 |
| ne pas | 0 | 1 |
| Somme = 8 | Somme = 11 |
On voit que pour la chaîne "je suis triste, je n'apprends pas la PNL", seuls deux mots "heureux, parce que" ne sont pas contenus dans le vocabulaire, maintenant pour extraire des traits et créer ledit vecteur, on somme la fréquence positive et négative colonnes séparément en omettant le nombre de fréquences des mots qui ne sont pas présents dans la chaîne, dans ce cas nous laissons "heureux, parce que". Nous obtenons la somme comme 8 pour la fréquence positive et 9 pour la fréquence négative.
Par conséquent, la chaîne "Je suis triste, je n'apprends pas la PNL" peut être représentée par un vecteur Le nombre « 1 » présent dans l'indice 0 est l'unité de biais qui restera « 1 » pour toutes les chaînes à venir et les nombres « 8 », « 11 » représentent respectivement la somme des fréquences positives et négatives.
De la même manière, toutes les chaînes de l'ensemble de données peuvent être converties confortablement en un vecteur de dimension 3.
Lire la suite : Analyse des sentiments à l'aide de Python : un guide pratique
Application de la régression logistique
L'extraction de caractéristiques facilite la compréhension de l'essence de la phrase, mais les machines ont toujours besoin d'un moyen plus précis pour signaler une chaîne invisible en positif ou en négatif. Ici, la régression logistique entre en jeu qui utilise la fonction sigmoïde qui génère une probabilité entre 0 et 1 pour chaque chaîne vectorisée.

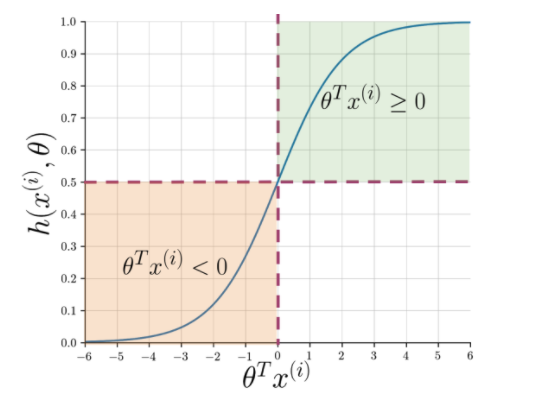
Figure 1 : Notation graphique de la fonction sigmoïde
La figure 1 montre que chaque fois que le produit scalaire de thêta et A lire également : Top 4 des idées de projets d'analyse de données : niveau débutant à expert
Et ensuite ?
L'analyse des sentiments est un sujet essentiel dans l'apprentissage automatique. Il a de nombreuses applications dans de multiples domaines. Si vous souhaitez en savoir plus sur ce sujet, vous pouvez vous diriger vers notre blog et trouver de nombreuses nouvelles ressources.
D'autre part, si vous souhaitez obtenir une expérience d'apprentissage complète et structurée, également si vous souhaitez en savoir plus sur l'apprentissage automatique, consultez le diplôme PG en apprentissage automatique et IA de IIIT-B & upGrad, conçu pour les professionnels en activité. et offre plus de 450 heures de formation rigoureuse, plus de 30 études de cas et missions, le statut d'ancien IIIT-B, plus de 5 projets de synthèse pratiques et une assistance à l'emploi avec les meilleures entreprises.
Q1. Pourquoi l'algorithme de forêt aléatoire est-il le meilleur pour l'apprentissage automatique ?
L'algorithme Random Forest appartient à la catégorie des algorithmes d'apprentissage supervisé, qui sont largement utilisés dans le développement de différents modèles d'apprentissage automatique. L'algorithme de forêt aléatoire peut être appliqué à la fois aux modèles de classification et de régression. Ce qui rend cet algorithme le plus adapté à l'apprentissage automatique est le fait qu'il fonctionne brillamment avec des informations de grande dimension puisque l'apprentissage automatique traite principalement des sous-ensembles de données. Fait intéressant, l'algorithme de forêt aléatoire est dérivé de l'algorithme des arbres de décision. Mais, vous pouvez vous entraîner à l'aide de cet algorithme dans un laps de temps beaucoup plus court qu'en utilisant des arbres de décision car il n'utilise que des fonctionnalités spécifiques. Il offre une plus grande efficacité dans les modèles d'apprentissage automatique et il est donc davantage préféré.
Q2. En quoi le machine learning est-il différent du deep learning ?
L'apprentissage en profondeur et l'apprentissage automatique sont des sous-domaines de l'ensemble que nous appelons l'intelligence artificielle. Cependant, ces deux sous-domaines présentent leurs propres différences. L'apprentissage en profondeur est essentiellement un sous-ensemble de l'apprentissage automatique. Cependant, en utilisant l'apprentissage en profondeur, les machines peuvent analyser des vidéos, des images et d'autres formes de données non structurées, ce qui peut être difficile à réaliser en utilisant uniquement l'apprentissage automatique. L'apprentissage automatique consiste à permettre aux ordinateurs de penser et d'agir par eux-mêmes, avec une intervention humaine minimale. En revanche, l'apprentissage en profondeur est utilisé pour aider les machines à penser sur la base de structures ressemblant au cerveau humain.
Q3. Pourquoi les data scientists préfèrent-ils l'algorithme de forêt aléatoire ?
L'utilisation de l'algorithme de forêt aléatoire présente de nombreux avantages, ce qui en fait le choix préféré des data scientists. Premièrement, il fournit des résultats très précis par rapport à d'autres algorithmes linéaires tels que la régression logistique et linéaire. Même si cet algorithme peut être difficile à expliquer, il est plus facile d'inspecter et d'interpréter les résultats en fonction de ses arbres de décision sous-jacents. Vous pouvez utiliser cet algorithme avec la même facilité même lorsque de nouveaux échantillons et fonctionnalités y sont ajoutés. Il est facile à utiliser même lorsque certaines données sont manquantes.