
Una intuición detrás del análisis de sentimiento: ¿Cómo hacer un análisis de sentimiento desde cero?
Publicado: 2020-12-07Tabla de contenido
Introducción
El texto es el medio más importante de percepción de información para los seres humanos. La mayor parte de la inteligencia adquirida por los humanos es a través del aprendizaje y la comprensión del significado de los textos y las oraciones que los rodean.
Después de cierta edad, los humanos desarrollan un reflejo intrínseco para comprender la inferencia de cualquier palabra/texto sin siquiera saberlo. Para las máquinas, esta tarea es completamente diferente. Para asimilar los significados de textos y oraciones, las máquinas se basan en los fundamentos del procesamiento del lenguaje natural (NLP).
El aprendizaje profundo para el procesamiento del lenguaje natural es el reconocimiento de patrones aplicado a palabras, oraciones y párrafos, de la misma manera que la visión artificial es el reconocimiento de patrones aplicado a píxeles de imagen.
Ninguno de estos modelos de aprendizaje profundo comprende realmente el texto en un sentido humano; más bien, estos modelos pueden mapear la estructura estadística del lenguaje escrito, lo cual es suficiente para resolver muchas tareas textuales simples. El análisis de opinión es una de esas tareas, por ejemplo: clasificar la opinión de cadenas o reseñas de películas como positivas o negativas.
Estos también tienen aplicaciones a gran escala en la industria. Por ejemplo: a una empresa de bienes y servicios le gustaría recopilar los datos de la cantidad de críticas positivas y negativas que ha recibido para un producto en particular para trabajar en el ciclo de vida del producto y mejorar sus cifras de ventas y recopilar comentarios de los clientes.
preprocesamiento
La tarea de análisis de sentimientos se puede dividir en un simple algoritmo de aprendizaje automático supervisado, donde generalmente tenemos una entrada X , que se convierte en una función de predicción para obtener Luego comparamos nuestra predicción con el valor real Y. Esto nos da el costo que luego usamos para actualizar los parámetros Para abordar la tarea de extraer opiniones de un flujo de textos nunca antes visto, el primer paso es recopilar un conjunto de datos etiquetados con opiniones positivas y negativas separadas. Estos sentimientos pueden ser: buena crítica o mala crítica, comentario sarcástico o comentario no sarcástico, etc.
El siguiente paso es crear un vector de dimensión V , donde Este vector de vocabulario contendrá cada palabra (ninguna palabra se repite) que esté presente en nuestro conjunto de datos y actuará como un léxico para nuestra máquina al que puede referirse. Ahora preprocesamos el vector de vocabulario para eliminar las redundancias. Se realizan los siguientes pasos:
- Eliminar URL y otra información no trivial (que no ayuda a determinar el significado de una oración)
- Tokenización de la cadena en palabras: supongamos que tenemos la cadena "Me encanta el aprendizaje automático", ahora mediante la tokenización simplemente dividimos la oración en palabras individuales y la almacenamos en una lista como [I, love, machine, learning]
- Eliminar palabras vacías como “y”, “soy”, “o”, “yo”, etc.
- Stemming: transformamos cada palabra a su forma radical. Palabras como "tune", "tuning" y "tuned" tienen semánticamente el mismo significado, por lo que reducirlas a su forma radical que es "tun" reducirá el tamaño del vocabulario.
- Convertir todas las palabras a minúsculas
Para resumir el paso de preprocesamiento, echemos un vistazo a un ejemplo: digamos que tenemos una cadena positiva "Me encanta el nuevo producto en upGrad.com" . La cadena preprocesada final se obtiene eliminando la URL, tokenizando la oración en una sola lista de palabras, eliminando las palabras vacías como "I, am, the, at" y luego derivando las palabras "loving" a "lov" y "product". a "produ" y finalmente convirtiéndolo todo a minúsculas, lo que da como resultado la lista [lov, new, produ] .
Extracción de características
Después de preprocesar el corpus, el siguiente paso sería extraer características de la lista de oraciones. Como todas las demás redes neuronales, los modelos de aprendizaje profundo no toman como entrada texto sin procesar: solo funcionan con tensores numéricos. Por lo tanto, es necesario convertir la lista preprocesada de palabras en valores numéricos. Esto se puede hacer de la siguiente manera. Suponga que dada una compilación de cadenas con cadenas positivas y negativas como (suponga que esto es el conjunto de datos) :
| cadenas positivas | Cuerdas negativas |
|
|
Ahora, para convertir cada una de estas cadenas en un vector numérico de dimensión 3, creamos un diccionario para mapear la palabra y la clase en la que apareció (positiva o negativa) al número de veces que esa palabra apareció en su clase correspondiente.
| Vocabulario | Frecuencia positiva | frecuencia negativa |
| I | 3 | 3 |
| soy | 3 | 3 |
| contento | 2 | 0 |
| porque | 1 | 0 |
| aprendiendo | 1 | 1 |
| PNL | 1 | 1 |
| triste | 0 | 2 |
| no | 0 | 1 |
Después de generar el diccionario antes mencionado, miramos cada una de las cadenas individualmente, y luego sumamos el número de frecuencia positiva y negativa de las palabras que aparecen en la cadena, dejando las palabras que no aparecen en la cadena. Tomemos la cadena '"Estoy triste, no estoy aprendiendo PNL" y generemos el vector de dimensión 3.

“Estoy triste, no estoy aprendiendo PNL”
| Vocabulario | Frecuencia positiva | frecuencia negativa |
| I | 3 | 3 |
| soy | 3 | 3 |
| contento | 2 | 0 |
| porque | 1 | 0 |
| aprendiendo | 1 | 1 |
| PNL | 1 | 1 |
| triste | 0 | 2 |
| no | 0 | 1 |
| Suma = 8 | Suma = 11 |
Vemos que para la cadena "Estoy triste, no estoy aprendiendo PNL", solo dos palabras "feliz, porque" no están contenidas en el vocabulario, ahora para extraer características y crear dicho vector, sumamos la frecuencia positiva y negativa columnas por separado dejando fuera el número de frecuencia de las palabras que no están presentes en la cadena, en este caso dejamos “feliz, porque”. Obtenemos la suma como 8 para la frecuencia positiva y 9 para la frecuencia negativa.
Por lo tanto, la cadena "Estoy triste, no estoy aprendiendo PNL" se puede representar como un vector El número "1" presente en el índice 0 es la unidad de polarización que seguirá siendo "1" para todas las cadenas siguientes y los números "8", "11" representan la suma de frecuencias positivas y negativas respectivamente.
De manera similar, todas las cadenas del conjunto de datos se pueden convertir cómodamente en un vector de dimensión 3.
Leer más: Análisis de sentimiento usando Python: una guía práctica
Aplicación de regresión logística
La extracción de características facilita la comprensión de la esencia de la oración, pero las máquinas aún necesitan una forma más nítida de marcar una cadena invisible como positiva o negativa. Aquí entra en juego la regresión logística que hace uso de la función sigmoidea que genera una probabilidad entre 0 y 1 para cada cadena vectorizada.

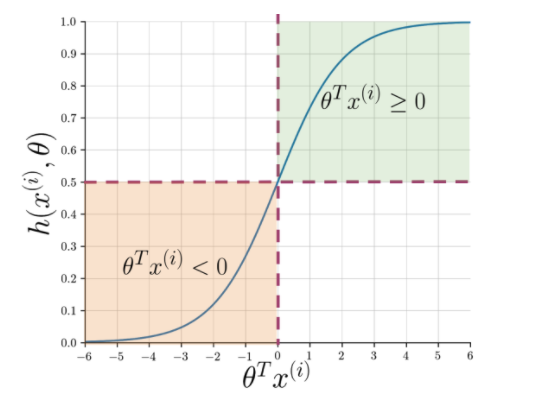
Figura 1: Notación gráfica de la función sigmoidea
La figura 1 muestra que siempre que el producto escalar de theta y Lea también: Las 4 mejores ideas de proyectos de análisis de datos: nivel de principiante a experto
¿Qué sigue?
El análisis de sentimientos es un tema esencial en el aprendizaje automático. Tiene numerosas aplicaciones en múltiples campos. Si desea obtener más información sobre este tema, puede dirigirse a nuestro blog y encontrar muchos recursos nuevos.
Por otro lado, si desea obtener una experiencia de aprendizaje integral y estructurada, también si está interesado en obtener más información sobre el aprendizaje automático, consulte el Diploma PG en Aprendizaje automático e IA de IIIT-B y upGrad, que está diseñado para profesionales que trabajan. y ofrece más de 450 horas de capacitación rigurosa, más de 30 estudios de casos y asignaciones, estado de ex alumno de IIIT-B, más de 5 proyectos prácticos finales y asistencia laboral con las mejores empresas.
Q1. ¿Por qué el algoritmo de bosque aleatorio es mejor para el aprendizaje automático?
El algoritmo Random Forest pertenece a la categoría de algoritmos de aprendizaje supervisado, que se utilizan ampliamente en el desarrollo de diferentes modelos de aprendizaje automático. El algoritmo de bosque aleatorio se puede aplicar tanto para modelos de clasificación como de regresión. Lo que hace que este algoritmo sea el más adecuado para el aprendizaje automático es el hecho de que funciona de manera brillante con información de alta dimensión, ya que el aprendizaje automático trata principalmente con subconjuntos de datos. Curiosamente, el algoritmo de bosque aleatorio se deriva del algoritmo de árboles de decisión. Sin embargo, puede entrenar con este algoritmo en un lapso de tiempo mucho más corto que con los árboles de decisión, ya que solo usa características específicas. Ofrece una mayor eficiencia en los modelos de aprendizaje automático y, por lo tanto, se prefiere más.
Q2. ¿En qué se diferencia el aprendizaje automático del aprendizaje profundo?
Tanto el aprendizaje profundo como el aprendizaje automático son subcampos de todo el paraguas que llamamos inteligencia artificial. Sin embargo, estos dos subcampos vienen con sus propias diferencias. El aprendizaje profundo es esencialmente un subconjunto del aprendizaje automático. Sin embargo, al usar el aprendizaje profundo, las máquinas pueden analizar videos, imágenes y otras formas de datos no estructurados, lo que puede ser difícil de lograr empleando solo el aprendizaje automático. El aprendizaje automático se trata de permitir que las computadoras piensen y actúen por sí mismas, con una mínima intervención humana. Por el contrario, el aprendizaje profundo se utiliza para ayudar a las máquinas a pensar basándose en estructuras que se asemejan al cerebro humano.
Q3. ¿Por qué los científicos de datos prefieren el algoritmo de bosque aleatorio?
Hay muchos beneficios de usar el algoritmo de bosque aleatorio, que lo convierten en la opción preferida entre los científicos de datos. En primer lugar, proporciona resultados muy precisos en comparación con otros algoritmos lineales como la regresión logística y lineal. Aunque este algoritmo puede ser difícil de explicar, es más fácil inspeccionar e interpretar los resultados en función de sus árboles de decisión subyacentes. Puede usar este algoritmo con la misma facilidad incluso cuando se le agregan nuevas muestras y características. Es fácil de usar incluso cuando faltan algunos datos.