
データ構造のグラフ:タイプ、保存、トラバーサル
公開: 2020-10-07データ構造は、データサイエンスでデータを整理する効率的な方法であり、データに簡単にアクセスして効果的に使用できます。 データベースには多くの種類がありますが、この記事では、グラフがデータ管理で重要な役割を果たす理由について説明します。
ネタバレ注意:毎日データ構造のグラフを使用して、オフィスへの最適なルートを取得し、昼食や映画の提案を取得し、次の飛行ルートを最適化します。 興味深いですね! グラフのプロパティとそのアプリケーションについて見てみましょう。
まず、グラフとは何かを見てみましょう。 これは、ノード(または頂点)とエッジ(またはパス)で構成される非線形構造のデータの表現です。
データ構造内のグラフは、相互接続されたエッジ(パス)と頂点(ノード)の多くのグループ間で格納されたデータで構成されるデータ構造と呼ぶことができます。 グラフデータ構造(N、E)は、ノードとエッジのコレクションで構成されています。 ノードと頂点の両方が有限である必要があります。
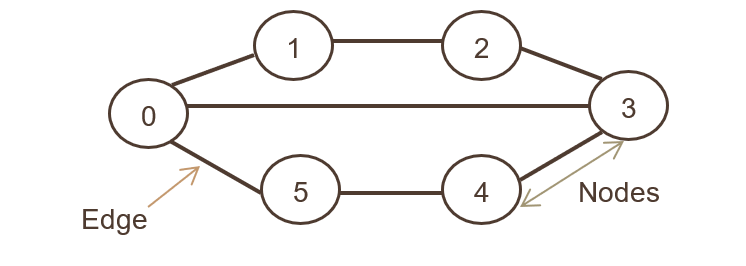
上記のグラフ表現では、ノードのセットはN = {0,1,2,3,4,5,6}であり、エッジのセットは
G = {01,12,23,34,45,05,03}
それでは、グラフの種類を調べてみましょう。
読む:トップ10のデータ視覚化技術
目次
グラフの種類
1.加重グラフ
エッジまたはパスに値があるグラフ。 エッジに関連付けられて表示されるすべての値は、重みと呼ばれます。 エッジ値は、重量/コスト/長さを表すことができます。
値または重みは、以下を表す場合もあります。
- 2点間の距離-例:オフィスまでの最短経路を探すために、オフィスネットワーク内の2台のワークステーション間の距離。
- ネットワークまたは帯域幅でのデータパケットの速度。
2.重み付けされていないグラフ
エッジに関連付けられた値または重みがない場合。 デフォルトでは、値が関連付けられていない限り、すべてのグラフは重み付けされていません。
3.無向グラフ
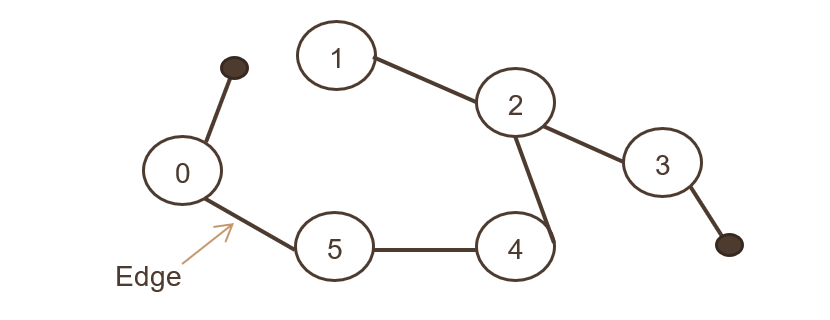
オブジェクトのセットが接続され、すべてのエッジが双方向である場合。 次の画像は、無向グラフを示しています。
これは、友達として接続した後の2人のFacebookユーザーの連想のようなものです。 両方のユーザーが写真を参照して共有したり、お互いにコメントしたりできます。
4.有向グラフ
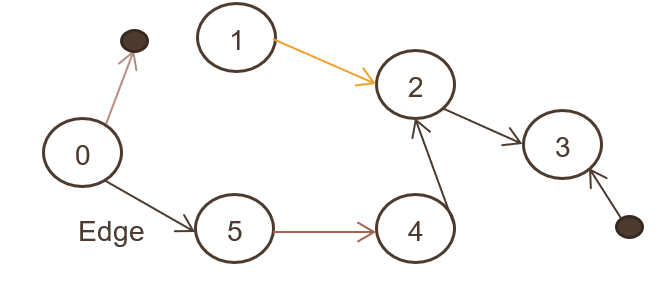
有向グラフとも呼ばれ、オブジェクトのセット(N、E)が接続され、すべてのエッジが1つのノードから別のノードに向けられます。 上の画像は有向グラフを示しています。
チェックアウト:複製できるデータ視覚化プロジェクト
グラフの保存
すべての保存方法には長所と短所があり、複雑さに基づいて適切な保存方法が選択されます。 グラフを格納するために最も一般的に使用される2つのデータ構造は次のとおりです。
1.隣接リスト
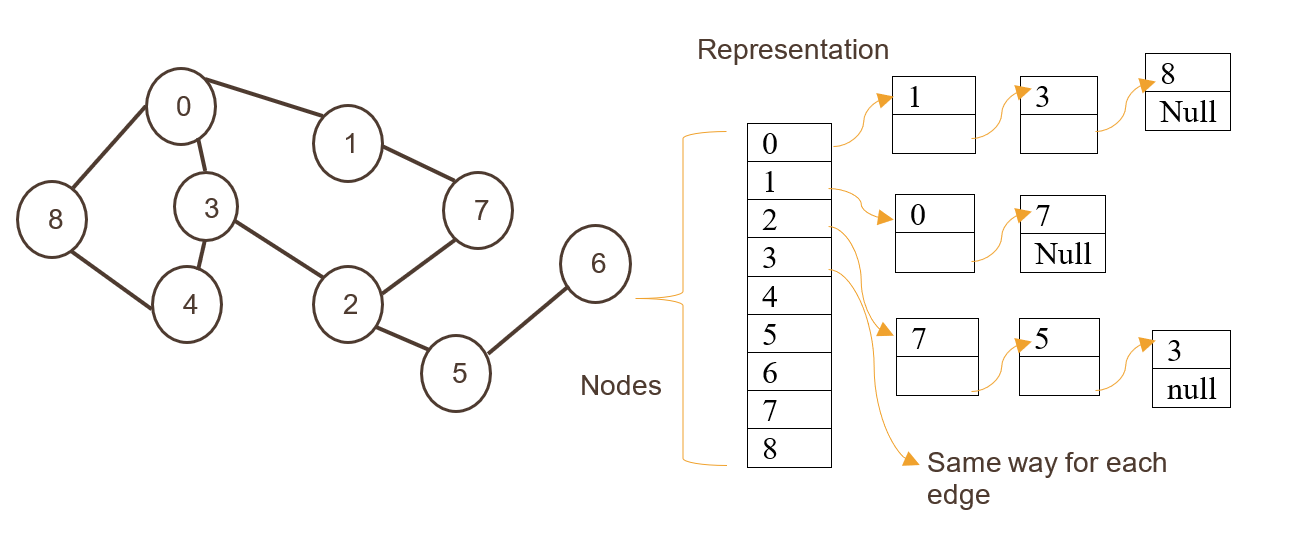
ここでは、ノードは1次元配列のインデックスとして格納され、その後にエッジがリストとして格納されます。
2.隣接行列
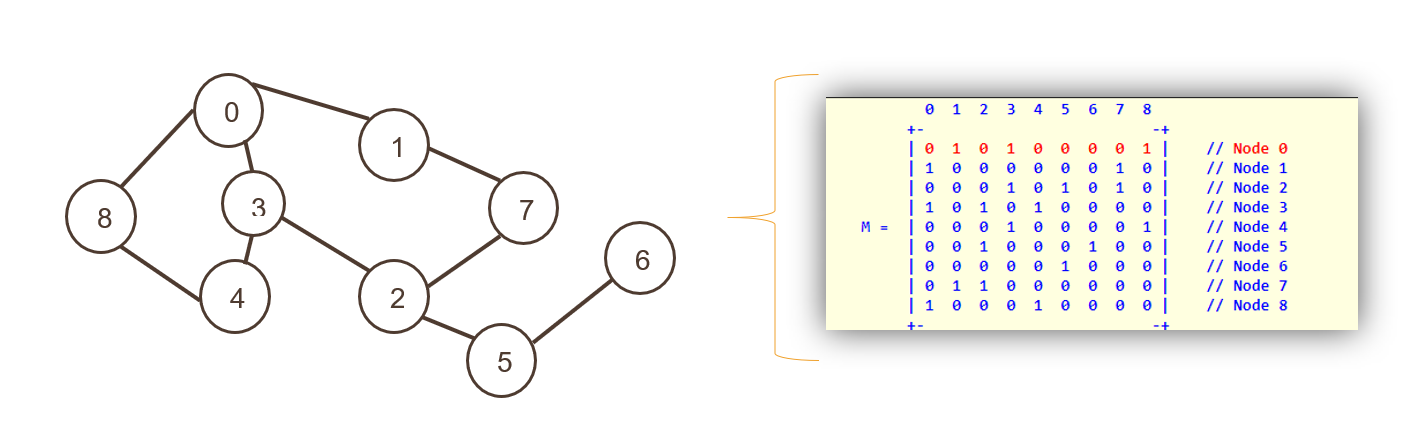
ここで、ノードは2次元配列のインデックスとして表され、その後に隣接行列の非ゼロ値として表されるエッジが続きます。
行と列の両方がノードを示しています。 行列全体が「0」または「1」で埋められ、真または偽を表します。 ゼロはパスがないことを表し、1はパスを表します。
グラフ走査
グラフ走査は、グラフ内のノードを検索するために使用される方法です。 グラフ走査は、ノードの配置に使用される順序を決定するために使用されます。 また、ループを作成せずにエッジを検索します。つまり、ループを作成せずにすべてのノードとエッジを検索できます。
2つのグラフ走査構造があります。
1. DFS(深さ優先探索):詳細な検索方法
DFS検索は、最初のノードから始まり、ターゲットノードが見つかるまでさらに深く探索していきます。 ターゲットキーが見つからない場合、検索パスは最初の検索中に探索を停止したパスに変更され、同じ手順がそのブランチに対して繰り返されます。
スパニングツリーは、この検索の結果から生成されます。 このツリーメソッドにはループがありません。 スタックデータ構造内のノードの総数は、DFSトラバーサルを実装するために使用されます。
DFS検索を実装するための手順:

ステップ1-ノードの総数に応じてスタックサイズを定義する必要があります。
ステップ2–横断する初期ノードを選択します。 そのノードにアクセスしてスタックにプッシュする必要があります。
ステップ3–ここで、以前にアクセスされていない隣接ノードにアクセスし、それをスタックにプッシュします。
ステップ4–アクセスされていない隣接ノードがなくなるまでステップ3を繰り返します。
ステップ5–訪問するノードが他にない場合は、バックトラッキングと1つのノードを使用します。
ステップ6–ステップ3、4、および5を繰り返して、スタックを空にします。
ステップ7–スタックが空の場合、未使用のエッジを削除して最終的なスパニングツリーが形成されます。
DFSのアプリケーションは次のとおりです。
- 1つの解決策だけでパズルを解きます。
- グラフが2部グラフであるかどうかをテストします。
- ジョブや他の多くのスケジュールを設定するためのトポロジカルソート。
2. BFS(幅優先探索):検索はキューイング方式を使用して実装されます
幅優先探索は、グラフを幅優先でナビゲートし、パスの終わりに遭遇した後、キューに基づいて1つのノードから別のノードにジャンプするために利用します。
BFS検索を実装するための手順
ステップ1-ノードの数に基づいて、キューが定義されます。
ステップ2–トラバーサルの任意のノードから開始します。 そのノードにアクセスして、キューに追加します。
ステップ3–ここで、キューの前にある未訪問の隣接ノードを確認し、それを開始ではなくキューに追加します。
ステップ4–ここで、訪問する必要のあるエッジがなく、キューにないノードの削除を開始します。
ステップ5–ステップ4と5を繰り返して、キューを空にします。
ステップ6–キューが空になった後でのみ、未使用のエッジを削除してスパニングツリーを形成します。
BFSのアプリケーションは次のとおりです。
- ピアツーピアネットワーク-Bittorrentと同様に、隣接するすべてのノードを検索するために使用されます。
- 検索エンジンのクローラー。
- ソーシャルネットワーキングウェブサイトおよびその他多数。
データ構造におけるグラフの実際のアプリケーション
グラフは、ネットワーク表現(道路、光ファイバーマッピング、回路基板の設計など)などの多くの日常的なアプリケーションで使用されます。 例:Facebookデータネットワークでは、ノードはユーザーとその写真またはコメントを表し、エッジは写真と写真へのコメントを表します。
データ構造のグラフには、広範なアプリケーションがあります。 注目すべきもののいくつかは次のとおりです。
- ソーシャルグラフAPI–これはFacebookソーシャルメディアプラットフォームとの間でデータが通信される主要な方法です。 これはHTTPベースのAPIであり、プログラムでデータをクエリしたり、写真やビデオをアップロードしたり、新しいストーリーを作成したり、その他多くのタスクを実行したりするために使用されます。 これは、ノード、エッジ、およびフィールドで構成されています。 クエリには、特定のオブジェクトノードが使用されます。 単一のオブジェクトとフィールドの対象となるオブジェクトのグループのエッジは、グループ内の各オブジェクトに関するデータをフェッチするために使用されます。
- YelpのGraphQLAPI–これはYelpプラットフォームから特定のデータをフェッチするために使用されるレコメンデーションエンジンです。 ここでは、順序を使用してエッジを検索し、その後、特定のノードを照会して正確な結果をフェッチします。 これにより、取得プロセスが高速化されます。
Yelpプラットフォームでは、ノードはビジネスを表し、id、name、is_closed、およびその他の多くのグラフプロパティを含みます。
- パス最適化アルゴリズム-速度、安全性、燃料などの基準に適合する最適な接続を見つけるために使用されます。このアルゴリズムではBFSが使用されます。 最良の例は、Google Maps Platform(Maps、Routes API)です。
- フライトネットワーク-フライトネットワークでは、これはグラフデータ構造に適合する最適化されたパスを見つけるために使用されます。 これはモデルにも役立ち、空港の手続きを効率的に最適化します。
また読む:データ視覚化の利点
結論
この記事では、最初にデータ構造におけるグラフとグラフの定義について説明し、次にグラフのタイプとそのプロパティについて学習しました。 その後、グラフの保存に一般的に使用される方法と、それに続くグラフ、グラフ走査で使用される重要なトピック検索方法について学習しました。 最後に、グラフデータ構造の実際のアプリケーションについて説明しました。
この記事では、データ構造のグラフに関する洞察を提供しました。 これに関する知識は、グラフデータベース、検索アルゴリズムの実装、プログラミングなどの基本的な理解に不可欠です。 それは業界の専門家から学ぶ必要があります。
upGradでコースを選択する理由
upGradでホストされているIIITBangaloreが提供するデータサイエンスのエグゼクティブPGプログラムを選択することをお勧めします。ここでは、コースのインストラクターと1対1でクエリを取得できます。 理論的な学習に焦点を当てるだけでなく、実践的な知識を重要視します。これは、学習者が実際のプロジェクトに立ち向かう準備を整え、データサイエンスで高給の仕事を得るのに役立つインド初のNASSCOM証明書を提供するために不可欠です。
引用された作品
数学/CS学科–ホーム、www.mathcs.emory.edu /〜cheung / Courses / 171 / Syllabus / 11-Graph/data-stru.html。
「数学の洞察」。 有向グラフの定義– Math Insight 、mathinsight.org / defined/directed_graph。
シン、アムリトパル。 「グラフデータ構造」。 Medium 、Medium、2020年3月29日、medium.com / @ singhamritpal49/graph-data-structure-49427c81b3b3。
ソロ。 「知っておくべきグラフデータ構造の実際のアプリケーション。」 グラフデータとGraphQLAPIの開発-LeapGraph 、leapgraph.com/graph-data-structures-applications。
データ構造にグラフが必要なのはなぜですか?
多くの現実の問題は、グラフを使用して解決されます。 ネットワークはグラフを使用して表されます。 都市、電話網、または回線ネットワークのパスは、ネットワークの例です。 グラフは、LinkedInやFacebookなどのソーシャルネットワーキングサイトでも利用されています。 グラフは強力で適応性のあるデータ構造であり、多くの種類のデータ(ノード)間の実際の接続を簡単に表現できます。 グラフは、2つの主要なコンポーネント(頂点とエッジ)で構成されています。 データは頂点(ノード)に保存されます。頂点(ノード)は、左の図の番号で表されています。 写真のノードを結ぶエッジ(接続)、つまり数字を結ぶ線。
グラフを保存するために何種類のデータ構造が存在しますか?
グラフは、隣接行列、隣接リスト、または隣接セットの3つのデータ構造のいずれかで表すことができます。 隣接行列は、行と列を持つテーブルに似ています。 グラフのノードは、行と列のラベルで表されます。 グラフの隣接リスト内のすべての頂点は、ノードオブジェクトとして表されます。 隣接セットは、隣接リストによって発生する問題のいくつかを軽減します。 隣接セットは隣接リストにかなり似ていますが、リンクリストの代わりに、隣接する頂点のコレクションを提供します。
トラバーサルとは何ですか?
トラバーサルは、ツリー内のすべてのノードにアクセスし、それらの値を出力する手順です。 すべてのノードはエッジ(リンク)によってリンクされているため、常にルート(ヘッド)ノードから開始します。 つまり、ツリー内のノードにランダムにアクセスすることはできません。 インオーダートラバーサル、プレオーダートラバーサル、およびポストオーダートラバーサルは、ツリーをトラバースするための3つの方法です。