
حدس وراء تحليل المشاعر: كيف يتم تحليل المشاعر من نقطة الصفر؟
نشرت: 2020-12-07جدول المحتويات
مقدمة
النص هو أهم وسيلة لإدراك المعلومات للبشر. يتم الحصول على غالبية الذكاء المكتسب من قبل البشر من خلال التعلم وفهم معنى النصوص والجمل من حولهم.
بعد سن معينة ، يطور البشر رد فعل جوهري لفهم استنتاج أي كلمة / نص دون معرفة ذلك. بالنسبة للآلات ، هذه المهمة مختلفة تمامًا. لاستيعاب معاني النصوص والجمل ، تعتمد الآلات على أساسيات معالجة اللغة الطبيعية (NLP).
التعلم العميق لمعالجة اللغة الطبيعية هو التعرف على الأنماط المطبق على الكلمات والجمل والفقرات ، بنفس الطريقة التي يتم بها تطبيق رؤية الكمبيوتر على التعرف على الأنماط المطبقة على وحدات البكسل في الصورة.
لا أحد من نماذج التعلم العميق هذه يفهم حقًا النص بالمعنى الإنساني ؛ بدلاً من ذلك ، يمكن لهذه النماذج تعيين البنية الإحصائية للغة المكتوبة ، وهو ما يكفي لحل العديد من المهام النصية البسيطة. يعد تحليل المشاعر أحد هذه المهام ، على سبيل المثال: تصنيف مشاعر السلاسل أو مراجعات الأفلام على أنها إيجابية أو سلبية.
هذه لها تطبيقات واسعة النطاق في الصناعة أيضًا. على سبيل المثال: ترغب شركة السلع والخدمات في جمع بيانات عدد المراجعات الإيجابية والسلبية التي تلقتها لمنتج معين للعمل على دورة حياة المنتج وتحسين أرقام مبيعاتها وجمع آراء العملاء.
المعالجة
يمكن تقسيم مهمة تحليل المشاعر إلى خوارزمية بسيطة للتعلم الآلي تحت الإشراف ، حيث يكون لدينا عادةً إدخال X ، والذي يدخل في وظيفة توقع للحصول على ثم نقارن تنبؤنا بالقيمة الحقيقية Y ، وهذا يعطينا التكلفة التي نستخدمها بعد ذلك لتحديث المعلمات للتعامل مع مهمة استخلاص المشاعر من تدفق نصوص غير مرئي سابقًا ، فإن الخطوة البدائية هي جمع مجموعة بيانات مصنفة بمشاعر إيجابية وسلبية منفصلة. يمكن أن تكون هذه المشاعر: مراجعة جيدة أو مراجعة سيئة ، أو ملاحظة ساخرة أو ملاحظة غير ساخرة ، إلخ.
تتمثل الخطوة التالية في إنشاء متجه للبعد V ، حيث يتوافق سيحتوي متجه المفردات هذا على كل كلمة (لا توجد كلمة مكررة) الموجودة في مجموعة البيانات الخاصة بنا ، وسوف يعمل كمعجم لآلتنا يمكن أن يشير إليه. الآن نقوم بمعالجة متجه المفردات لإزالة التكرار. يتم تنفيذ الخطوات التالية:
- إزالة عناوين URL وغيرها من المعلومات غير التافهة (التي لا تساعد في تحديد معنى الجملة)
- تحويل السلسلة إلى كلمات: لنفترض أن لدينا السلسلة "أحب التعلم الآلي" ، والآن من خلال الترميز ، نقوم ببساطة بتقسيم الجملة إلى كلمات مفردة وتخزينها في قائمة مثل [أنا ، أحب ، آلة ، تعلم]
- إزالة كلمات التوقف مثل "و" ، "أنا" ، "أو" ، "أنا" ، إلخ.
- الاشتقاق: نقوم بتحويل كل كلمة إلى شكلها الجذعي. كلمات مثل "ضبط" و "ضبط" و "ضبط" لها نفس المعنى من الناحية اللغوية ، لذا فإن تقليلها إلى شكلها الجذعي الذي هو "ضبط" سيقلل من حجم المفردات
- تحويل كل الكلمات إلى أحرف صغيرة
لتلخيص خطوة المعالجة المسبقة ، دعنا نلقي نظرة على مثال: لنفترض أن لدينا سلسلة موجبة "أنا أحب المنتج الجديد في upGrad.com" . يتم الحصول على السلسلة النهائية المعالجة مسبقًا عن طريق إزالة عنوان URL ، وترميز الجملة في قائمة واحدة من الكلمات ، وإزالة كلمات التوقف مثل "أنا ، أنا ، في ،" ، ثم اشتقاق الكلمات "محب" إلى "أحب" و "منتج" إلى "produ" وأخيراً تحويل كل شيء إلى أحرف صغيرة مما ينتج عنه القائمة [lov ، new ، produ] .
ميزة استخراج
بعد معالجة المدونة مسبقًا ، ستكون الخطوة التالية هي استخراج الميزات من قائمة الجمل. مثل جميع الشبكات العصبية الأخرى ، لا تأخذ نماذج التعلم العميق كمدخلات للنص الخام: فهي تعمل فقط مع الموترات الرقمية. ومن ثم فإن قائمة الكلمات المجهزة مسبقًا تحتاج إلى تحويلها إلى قيم عددية. ويمكن القيام بذلك على النحو التالي. افترض أنه تم تقديم مجموعة من السلاسل ذات السلاسل الإيجابية والسلبية مثل (افترض أن هذا هو مجموعة البيانات) :
| السلاسل الإيجابية | السلاسل السلبية |
|
|
الآن لتحويل كل من هذه السلاسل إلى متجه عددي للبعد 3 ، نقوم بإنشاء قاموس لتعيين الكلمة ، والفئة التي ظهرت فيها (موجبة أو سالبة) إلى عدد المرات التي ظهرت فيها تلك الكلمة في فئتها المقابلة.
| كلمات | التردد الإيجابي | التردد السلبي |
| أنا | 3 | 3 |
| صباحا | 3 | 3 |
| سعيدة | 2 | 0 |
| لأن | 1 | 0 |
| التعلم | 1 | 1 |
| البرمجة اللغوية العصبية | 1 | 1 |
| حزين | 0 | 2 |
| ليس | 0 | 1 |
بعد إنشاء القاموس المذكور أعلاه ، ننظر إلى كل سلسلة على حدة ، ثم نجمع عدد التردد الموجب والسالب للكلمات التي تظهر في السلسلة مع ترك الكلمات التي لا تظهر في السلسلة. لنأخذ السلسلة "أنا حزين ، أنا لا أتعلم البرمجة اللغوية العصبية" ونولد متجه البعد 3.

"أنا حزين ، لا أتعلم البرمجة اللغوية العصبية"
| كلمات | التردد الإيجابي | التردد السلبي |
| أنا | 3 | 3 |
| صباحا | 3 | 3 |
| سعيدة | 2 | 0 |
| لأن | 1 | 0 |
| التعلم | 1 | 1 |
| البرمجة اللغوية العصبية | 1 | 1 |
| حزين | 0 | 2 |
| ليس | 0 | 1 |
| المجموع = 8 | المجموع = 11 |
نرى أنه بالنسبة للسلسلة "أنا حزين ، أنا لا أتعلم البرمجة اللغوية العصبية" ، كلمتان فقط "سعيد ، لأن" ليست مضمنة في المفردات ، الآن لاستخراج الميزات وإنشاء المتجه المذكور ، نقوم بتلخيص التردد الموجب والسالب بشكل منفصل مع استبعاد عدد تكرار الكلمات غير الموجودة في السلسلة ، في هذه الحالة نترك "سعيد ، لأن". نحصل على مجموع 8 للتردد الموجب و 9 للتردد السالب.
ومن ثم ، فإن الجملة "أنا حزين ، لا أتعلم البرمجة اللغوية العصبية" يمكن تمثيلها على أنها متجه الرقم "1" الموجود في الفهرس 0 هو وحدة التحيز التي ستبقى "1" لجميع السلاسل التالية والأرقام "8" ، "11" تمثل مجموع الترددات الموجبة والسالبة على التوالي.
بطريقة مماثلة ، يمكن تحويل جميع السلاسل في مجموعة البيانات إلى متجه ذي بُعد 3 بشكل مريح.
اقرأ المزيد: تحليل المشاعر باستخدام Python: دليل عملي
تطبيق الانحدار اللوجستي
يجعل استخراج الميزة من السهل فهم جوهر الجملة ولكن الآلات لا تزال بحاجة إلى طريقة أكثر وضوحًا للإشارة إلى سلسلة غير مرئية إلى إيجابية أو سلبية. هنا يتم تشغيل الانحدار اللوجستي الذي يستخدم الدالة السينية التي تنتج احتمالًا بين 0 و 1 لكل سلسلة متجهة.

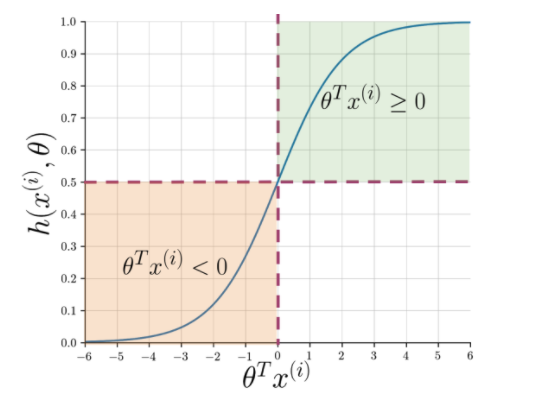
الشكل 1: تدوين رسومي للدالة السينية
يوضح الشكل 1 أنه عندما يكون حاصل الضرب النقطي لـ theta و اقرأ أيضًا: أفضل 4 أفكار لمشروع تحليل البيانات: مبتدئ إلى مستوى خبير
ماذا بعد؟
يعد تحليل المشاعر موضوعًا أساسيًا في التعلم الآلي. لها تطبيقات عديدة في مجالات متعددة. إذا كنت تريد معرفة المزيد حول هذا الموضوع ، فيمكنك التوجه إلى مدونتنا والعثور على العديد من الموارد الجديدة.
من ناحية أخرى ، إذا كنت ترغب في الحصول على تجربة تعليمية شاملة ومنظمة ، وأيضًا إذا كنت مهتمًا بمعرفة المزيد عن التعلم الآلي ، فراجع IIIT-B & upGrad's دبلوم PG في التعلم الآلي والذكاء الاصطناعي المصمم للمهنيين العاملين ويقدم أكثر من 450 ساعة من التدريب الصارم ، وأكثر من 30 دراسة حالة ومهمة ، وحالة خريجي IIIT-B ، وأكثر من 5 مشاريع عملية عملية ومساعدة وظيفية مع كبرى الشركات.
س 1. لماذا تعد خوارزمية Random Forest الأفضل للتعلم الآلي؟
تنتمي خوارزمية Random Forest إلى فئة خوارزميات التعلم الخاضع للإشراف ، والتي تُستخدم على نطاق واسع في تطوير نماذج مختلفة للتعلم الآلي. يمكن تطبيق خوارزمية الغابة العشوائية لكل من نماذج التصنيف والانحدار. ما يجعل هذه الخوارزمية الأكثر ملاءمة للتعلم الآلي هو حقيقة أنها تعمل ببراعة مع المعلومات عالية الأبعاد نظرًا لأن التعلم الآلي يتعامل في الغالب مع مجموعات فرعية من البيانات. ومن المثير للاهتمام أن خوارزمية الغابة العشوائية مشتقة من خوارزمية أشجار القرار. ولكن ، يمكنك التدرب على استخدام هذه الخوارزمية في فترة زمنية أقصر بكثير من استخدام أشجار القرار لأنها تستخدم ميزات محددة فقط. إنه يوفر كفاءة أكبر في نماذج التعلم الآلي ولذا فهو مفضل أكثر.
س 2. كيف يختلف التعلم الآلي عن التعلم العميق؟
يعتبر كل من التعلم العميق والتعلم الآلي مجالين فرعيين للمظلة بأكملها التي نطلق عليها الذكاء الاصطناعي. ومع ذلك ، فإن هذين الحقلين الفرعيين يأتيان مع اختلافاتهما الخاصة. التعلم العميق هو في الأساس مجموعة فرعية من التعلم الآلي. ومع ذلك ، باستخدام التعلم العميق ، يمكن للآلات تحليل مقاطع الفيديو والصور والأشكال الأخرى من البيانات غير المهيكلة ، والتي قد يكون من الصعب تحقيقها من خلال استخدام التعلم الآلي فقط. يدور التعلم الآلي حول تمكين أجهزة الكمبيوتر من التفكير والتصرف من تلقاء نفسها ، مع الحد الأدنى من التدخل البشري. في المقابل ، يتم استخدام التعلم العميق لمساعدة الآلات على التفكير بناءً على هياكل تشبه الدماغ البشري.
س 3. لماذا يفضل علماء البيانات خوارزمية الغابة العشوائية؟
هناك العديد من الفوائد لاستخدام خوارزمية الغابة العشوائية ، مما يجعلها الخيار المفضل بين علماء البيانات. أولاً ، يوفر نتائج دقيقة للغاية عند مقارنتها بالخوارزميات الخطية الأخرى مثل الانحدار اللوجستي والخطي. على الرغم من صعوبة شرح هذه الخوارزمية ، إلا أنه من الأسهل فحص وتفسير النتائج بناءً على أشجار القرار الأساسية الخاصة بها. يمكنك استخدام هذه الخوارزمية بنفس السهولة حتى عند إضافة عينات وميزات جديدة إليها. إنه سهل الاستخدام حتى في حالة فقدان بعض البيانات.