
TensorFlowを使用したディープラーニングにおけるモデルの検証と正則化の実践的な紹介
公開: 2020-10-28目次
序章
教師あり学習アルゴリズムのパラダイムを介して情報を吸収するマシンの実践は、シーケンス生成、自然言語処理、さらにはコンピュータービジョンなどのいくつかのタスクに革命をもたらしました。 このアプローチは、一連の入力機能と対応する一連のラベルを持つデータセットを利用することに基づいています。 次に、マシンは、特徴とラベルの形式で存在するこの情報を使用して、データの分布とパターンを学習し、目に見えない入力の統計的予測を行います。
ディープラーニングモデルを設計する際の最も重要なステップは、特に新しいデータポイントと見えないデータポイントでモデルのパフォーマンスを評価することです。 主な目標は、トレーニングを受けたデータを超えて一般化するモデルを開発することです。 私たちは、現実の世界で信頼できる優れた予測を行うことができるモデルを求めています。 これを支援する重要な概念は、本日取り上げるモデルの検証と正則化です。
モデルの検証
機械学習モデルの構築は、常に、利用可能なデータをトレーニング、検証、テストセットの3つのセットに分割することになります。 トレーニングデータは、分布の癖と特性を学習するためにモデルによって使用されます。
ここで知っておくべき焦点は、トレーニングセットでのモデルの満足のいくパフォーマンスは、モデルが同様のパフォーマンスを持つ新しいデータでも一般化することを意味しないということです。これは、モデルがトレーニングセットにバイアスされているためです。 したがって、検証とテストセットの概念は、モデルが新しいデータポイントでどの程度一般化されているかを報告するために使用されます。
標準的な手順は、トレーニングデータを使用してモデルを適合させ、検証データを使用してモデルのパフォーマンスを評価し、最後にテストデータを使用して、まったく新しい例でモデルがどの程度うまく機能するかを通知します。
検証セットは、モデルが適切に一般化できるように、ハイパーパラメーター(隠れ層の数、学習率、ドロップアウト率など)を調整するために使用されます。 機械学習の初心者が直面する一般的な難問は、個別の検証セットとテストセットの必要性を理解することです。

2つの異なるセットの必要性は、次の直感によって理解できます。設計する必要のあるすべてのディープニューラルネットワークには、満足のいくパフォーマンスを得るために調整する必要のあるハイパーパラメータが複数存在します。
いずれかのハイパーパラメータを使用して複数のモデルをトレーニングし、検証セットでのそのモデルのパフォーマンスに基づいて、パフォーマンスメトリックが最も高いモデルを選択できます。 これで、検証セットのパフォーマンスを向上させるためにハイパーパラメータを調整するたびに、一部の情報がモデルにリーク/フィードされるため、ニューラルネットワークの最終的な重みが検証セットに偏る可能性があります。
ハイパーパラメータを調整するたびに、モデルは検証セットで引き続き良好に機能します。これは、モデルを最適化したためです。 これが、検証テストがモデルの一般化能力を正確に示すことができない理由です。 この欠点を克服するために、テストセットが機能します。
モデルの一般化能力の最も正確な表現は、テストセットのパフォーマンスによって与えられます。これは、このセットのパフォーマンスを向上させるためにモデルを最適化していないためです。したがって、これはモデルの能力の最も実用的な推定値を示します。
必読:知っておくべきトップディープラーニングテクニック
TensorFlow2.0を使用した検証戦略の実装
TensorFlow 2.0は、別の保留された検証テストでモデルのパフォーマンスを追跡するための非常に簡単なソリューションを提供します。 model.fit()メソッドでvalidation_splitキーワード引数を渡すことができます。
validate_splitキーワードは、検証データとして使用されるトレーニングデータの割合を表す0と1の間の浮動小数点数として入力を受け取ります。 したがって、キーワードに0.1の値を渡すことは、検証のためにトレーニングデータの10%を予約することを意味します。
検証分割の実際の実装は、sklearnの糖尿病データセットを使用して簡単に示すことができます。 データセットには、トレーニング機能として10個のベースライン変数(年齢、性別、BMIなど)があり、ラベルとして1年後の疾患進行の測定値を持つ442個のインスタンスがあります。
TensorFlowとsklearnを使用してデータセットをインポートします。

データ前処理後の基本的なステップは、密な層を持つシーケンシャルフィードフォワードニューラルネットワークを構築することです。

ここでは、 relu活性化を伴う6つの隠れ層と線形活性化を伴う1つの出力層を備えたニューラルネットワークがあります。
次に、 Adamオプティマイザーと平均二乗誤差損失関数を使用してモデルをコンパイルします。


次に、 model.fit()メソッドを使用して、 validation_splitが15%の100エポックのモデルをトレーニングします。

トレーニングデータと検証データの両方で観察されたモデルの損失をプロットすることもできます。
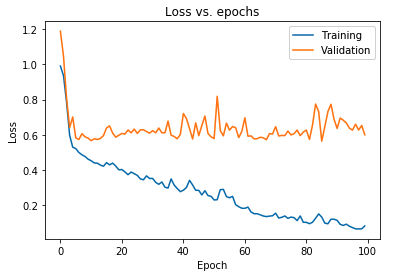
上に表示されたプロットは、トレーニング損失が減少し続けている間、検証損失が10エポック後に継続的に急増していることを示しています。 この傾向は、過剰適合と呼ばれる機械学習における非常に重要な問題の教科書の例です。
この問題を克服するために多くの独創的な研究が行われ、これらの解決策はまとめて正則化手法と呼ばれています。 次のセクションでは、正則化の側面と、深層学習モデルを正則化する手順について説明します。
モデルの正則化
前のセクションでは、トレーニングセットと検証セットの損失プロットで逆の傾向が見られました。後者のセットのコスト関数プロットは上昇しているように見え、前者のセットのコスト関数プロットは減少し続けているため、ギャップ(一般化ギャップ)が作成されます。 機械学習の正則化の詳細をご覧ください。
2つの損失プロットの間にそのようなギャップが存在するという事実は、モデルが検証セット(見えないデータ)でうまく一般化できないことを象徴し、したがって、そのデータセットで発生するコスト/損失値も必然的に高くなります。
この特異性は、トレーニングされたモデルの重みとバイアスがトレーニングデータの分布を学習するために共適応され、新しい特徴や見えない特徴のラベルを予測できず、検証損失が増加するために発生します。
理論的根拠は、モデルのパラメータがトレーニングデータに対して非常に堅牢になるため、複雑なモデルを構成するとそのような異常が発生することです。 したがって、モデルの容量/複雑さを単純化または削減すると、過剰適合の影響が減少します。 これを実現する1つの方法は、次のセクションで説明する深層学習モデルでドロップアウトを使用することです。
TensorFlowでのドロップアウトの理解と実装
ドロップアウトの使用の背後にある重要な認識は、モデルのパラメーターの増加を制限する複雑さの少ないモデルを取得するために、非表示のユニットと表示のユニットをランダムにドロップすることです。これにより、モデルは一般化されたデータセットでのパフォーマンスに対してより堅牢になります。
この最近受け入れられた実践は、機械学習の実践者が深層学習モデルで正則化効果を誘発するために使用する強力なアプローチです。 ドロップアウトレイヤーをインポートし、その中にレート引数を渡してドロップする必要のあるユニットの割合を指定することにより、TensorFlowを介してKerasAPIを使用してドロップアウトを簡単に実装できます。
これらのドロップアウトレイヤーは、通常、各高密度レイヤーの直後にスタックされ、高密度ドロップアウトレイヤーアーキテクチャの交互の潮流を生成します。
以前に定義したフィードフォワードニューラルネットワークを変更して、隠れ層ごとに1つずつ、 6つのドロップアウト層を含めることができます。


ここでは、 dropout _ rateが0.2に設定されています。これは、モデルのトレーニング中にノードの20%がドロップされることを意味します。 公正な比較を行うために、同じオプティマイザー、損失関数、メトリック、およびエポック数を使用してモデルをコンパイルおよびトレーニングします。
ドロップアウトを使用してモデルを正則化することの主な影響は、トレーニングセットと検証セットで取得されたモデルの損失曲線を再度プロットすることで解釈できます。
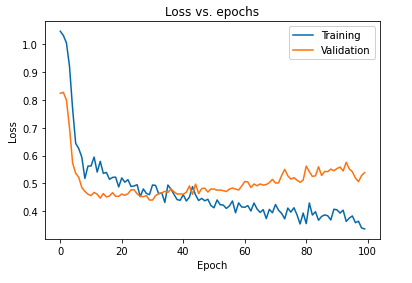
上記のプロットから、モデルを正則化した後に得られる一般化ギャップがはるかに小さく、モデルがトレーニングデータに過剰適合しにくいことが明らかです。
また読む:ディープラーニングプロジェクトのアイデア
結論
モデルの検証と正則化の側面は、機械学習ソリューションを構築するワークフローを設計する上で不可欠な部分です。 教師あり学習を即興で行うために多くの研究が行われています。このハンズオンチュートリアルでは、学習アルゴリズムを組み立てる際に、最も受け入れられている実践と手法のいくつかについて簡単に説明します。
深層学習技術、機械学習について詳しく知りたい場合は、機械学習と深層学習におけるIIIT-BとupGradのPG認定を確認してください。これは、働く専門家向けに設計されており、240時間以上の厳格なトレーニング、5つ以上のケーススタディを提供します。 &アサインメント、IIIT-B同窓生のステータスとトップ企業との仕事の支援。