
深度学习算法【带示例的综合指南】
已发表: 2020-10-28目录
介绍
深度学习是机器学习的一个子集,它涉及受大脑排列和功能启发的算法。 由于来自人类大脑的神经元传递信息并帮助从我们体内的反应器中学习,同样,深度学习算法贯穿神经网络算法的各个层并从它们的反应中学习。
换句话说,深度学习利用神经网络算法层来发现依赖于原始输入数据的更重要的级别数据。 神经网络算法通过模拟人脑工作方式的过程来发现数据模式。
神经网络有助于根据特征的相似性从大量数据点中对数据点进行聚类。 这些系统被称为人工神经网络。
随着越来越多的数据被输入到模型中,深度学习算法被证明比其他算法更有效率并提供更好的结果。 深度学习算法用于解决各种问题,如图像识别、语音识别、欺诈检测、计算机视觉等。
神经网络的组成部分
1.网络拓扑——网络拓扑是指神经网络的结构。 它包括网络中隐藏层的数量,包括输入和输出层在内的每层中的神经元数量等。
2.输入层——输入层是神经网络的入口点。 输入层的神经元数量应该等于输入数据中的属性数量。

3.输出层——输出层是神经网络的出口点。 输出层的神经元数量应该等于目标变量中的类数量(对于分类问题)。 对于回归问题,输出层中的神经元数量将为 1,因为输出将是一个数值变量。
4.激活函数——激活函数是适用于神经元加权输入总和的数学方程。 它有助于确定是否应该触发神经元。 有许多激活函数,如 sigmoid 函数、整流线性单元 (ReLU)、Leaky ReLU、双曲正切、Softmax 函数等。
5.权重——连续层中神经元之间的每个互连都有一个与之相关的权重。 它表明神经元之间的连接在发现一些有助于预测神经网络结果的数据模式中的重要性。 权重值越高,显着性越高。 它是网络在训练阶段学习的参数之一。
6.偏差——偏差有助于将激活函数向左或向右移动,这对于更好的决策至关重要。 它的作用类似于线性方程中截距的作用。 权重可以增加激活函数的陡度,即表明激活函数将触发多快,而偏差用于延迟激活函数的触发。 它是网络在训练阶段学习的第二个参数。
相关文章:顶级深度学习技术
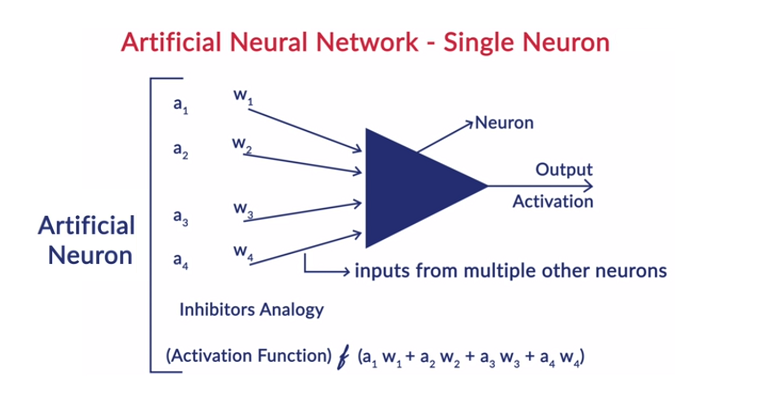
神经元的一般工作
深度学习与人工神经网络 (ANN) 一起工作,以模仿人类大脑的工作并以人类的方式进行学习。 人工神经网络中的神经元是分层排列的。 第一层和最后一层称为输入层和输出层。 这两层之间的层称为隐藏层。
该层中的每个神经元都包含其自身的偏差,并且从上一层到下一层的神经元之间的每个互连都有一个权重。 每个输入乘以与互连相关的权重。
为层中的每个神经元计算输入的加权和。 将激活函数应用于该输入的加权和,并与神经元的偏差相加以产生神经元的输出。 该输出用作下一层中该神经元连接的输入,依此类推。
这个过程称为前馈。 输出层的结果作为模型做出的最终决定。 神经网络的训练是基于神经元之间每个互连的权重和每个神经元的偏差来完成的。 在模型预测最终结果后,它会计算总损失,这是权重和偏差的函数。
Total Loss 基本上是所有神经元损失的总和。 由于最终目标是最小化成本函数,因此算法会回溯并相应地更改权重和偏差。 成本函数的优化可以使用梯度下降法来完成。 这个过程称为反向传播。
神经网络中的假设
- 神经元以层的形式排列,并且这些层以顺序的方式排列。
- 同一层内的神经元之间没有通信。
- 神经网络的入口点是输入层(第一层),出口点是输出层(最后一层)。
- 神经网络中的每个互连都有一些与之相关的权重,每个神经元都有与之相关的偏差。
- 相同的激活函数应用于某一层中的所有神经元。
阅读:深度学习项目理念
不同的深度学习算法
1. 全连接神经网络
在全连接神经网络 (FCNN) 中,一层中的每个神经元都连接到下一层中的每个其他神经元。 出于同样的原因,这些层被称为密集层。 这些层在计算上非常昂贵,因为每个神经元都与所有其他神经元相连。
当层中的神经元数量较少时,最好使用该算法,否则将需要大量的计算能力和时间来执行操作。 由于其完全连通性,它也可能导致过度拟合。
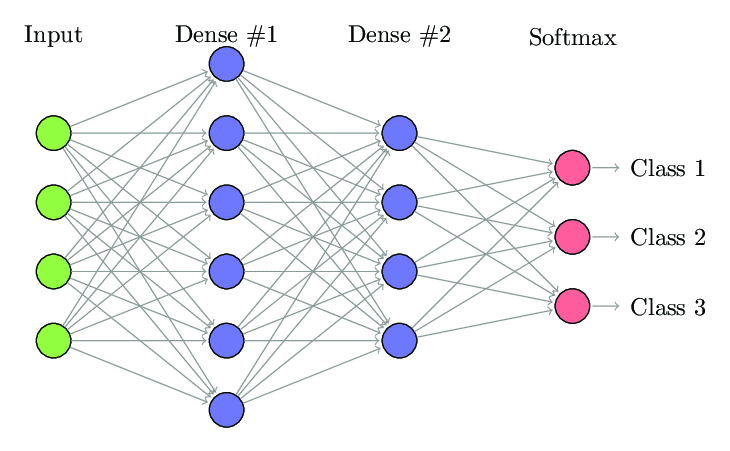
全连接神经网络(来源:Researchgate.net)
2. 卷积神经网络 (CNN)
卷积神经网络 (CNN) 是一类神经网络,旨在处理视觉数据。 即图像和视频。 因此,它用于许多图像处理任务,如光学字符识别 (OCR)、对象定位等。CNN 也可用于视频、文本和音频识别。
图像由确定图像中白度强度的像素组成。 图像的每个像素都是一个特征,将被馈送到神经网络。 例如,128×128 的图像表示该图像由 16384 个像素或特征组成。 它将作为大小为 16384 的向量馈送到神经网络。 对于彩色图像,有 3 个通道(每个通道一个 - 红、蓝、绿)。 在这种情况下,相同的彩色图像将由 128x128x3 像素组成。
CNN 的层中有层次结构。 第一层尝试提取图像的原始特征,如水平或垂直边缘。 第二层从第一层提取的特征中提取更多见解。 随后的层将深入研究细节以识别图像的某些部分,例如头发、皮肤、鼻子等。最后,最后一层将输入图像分类为人、猫、狗等。
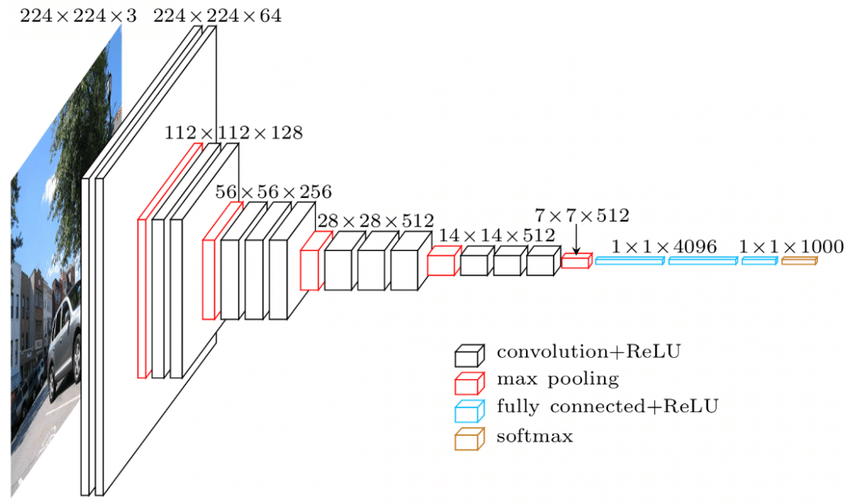
资源
VGGNet 架构——广泛使用的 CNN 之一
CNN 中有三个重要的术语:
- 卷积——卷积是两个矩阵的元素乘积的总和。 一个矩阵是输入数据的一部分,另一个矩阵是用于从图像中提取特征的滤波器。
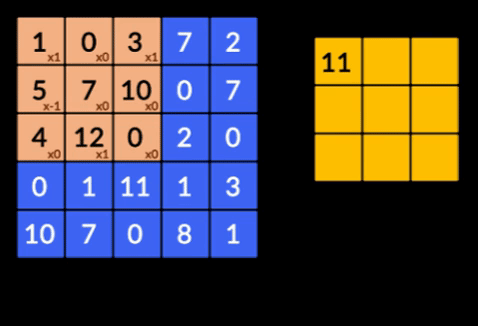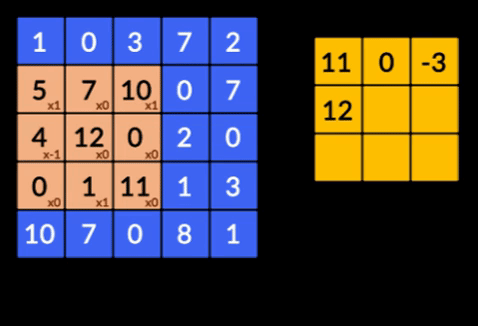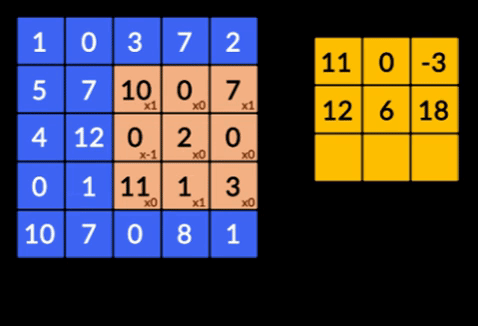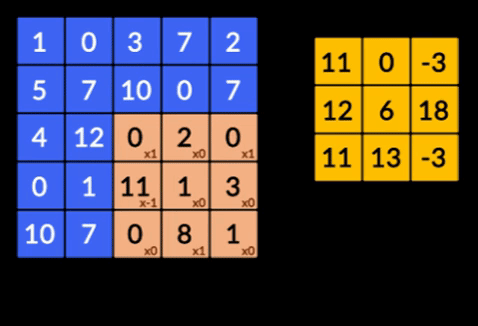

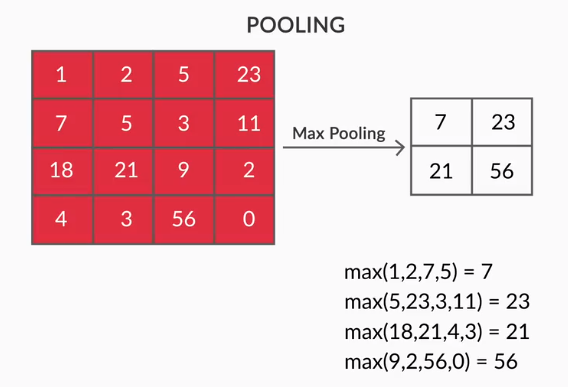
- 池化层——提取特征的聚合由池化层完成。 这些层通常计算聚合统计量(最大值、平均值等),并使网络对局部变换保持不变。
- 特征图——神经元是 CNN,基本上是一个过滤器,其权重是在训练期间学习的。 每个神经元查看输入中的特定区域,该区域称为其感受野。 特征图是这样的神经元的集合,它们以相同的权重查看图像的不同区域。 特征图中的所有神经元都尝试从图像的不同区域提取相同的特征。
3. 递归神经网络 (RNN)
循环神经网络旨在处理顺序数据。 序列数据是指与先前数据有某种联系的数据,例如文本(单词、句子等的序列)或视频(图像序列)、语音等。
了解这些连续实体之间的联系非常重要,否则将整个段落弄乱并试图从中得出一些含义是没有意义的。 RNN 旨在处理这些顺序实体。 使用 RNN 的一个很好的例子是在 YouTube 中自动生成字幕。 它只不过是使用 RNN 实现的自动语音识别。
普通神经网络和循环神经网络之间的主要区别在于输入数据沿两个维度流动——时间(沿序列长度以从中提取特征)和深度(普通神经层)。 有不同类型的 RNN,它们的结构也相应发生变化。
- 多对一 RNN:——在这种架构中,输入网络是一个序列,输出是一个单一的实体。 该架构用于解决情感分类等问题或预测输入数据的情感分数(回归问题)。 它还可用于将视频分类为某些类别。
- 多对多 RNN: - 输入和输出都是此架构中的序列。 它可以根据输入和输出的长度进一步分类。
- 相同长度: – 网络在每个时间步产生一个输出。 每个时间步的输入和输出之间存在一一对应的关系。 这种架构可以用作词性标记器,其中输入序列中的每个单词都在每个时间步用其词性作为输出进行标记。
- 不同的长度: – 在这种情况下,输入的长度不等于输出的长度。 这种架构的用途之一是语言翻译。 英语句子的长度可能与相应的印地语句子不同。
- 一对多 RNN:——这里的输入是单个实体,而输出是一个序列。 这些类型的神经网络用于生成音乐、图像等任务。
- 一对一 RNN: - 它是一种传统的神经网络,其中输入和输出是单个实体。
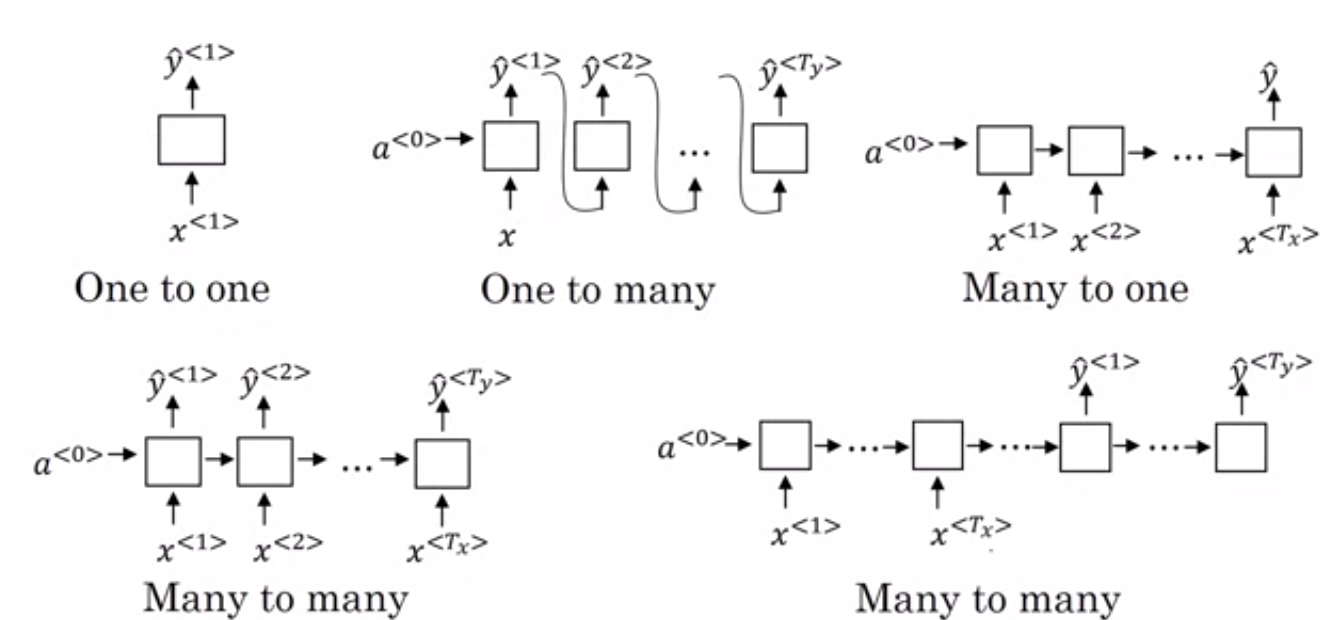
RNN 的类型(来源:iq.opengenus.org)
4. 长短期记忆网络(LSTM)
递归神经网络的缺点之一是梯度消失问题。 当我们使用随机梯度下降和反向传播等基于梯度的学习方法训练神经网络时会遇到这个问题。 激活函数的梯度负责更新网络的权重。
它们变得如此之小,以至于几乎不会影响神经网络的权重变化。 这可以防止神经网络训练。 当 RNN 在学习长期依赖方面遇到困难时,他们会面临这个问题。
长短期记忆网络 (LSTM) 旨在解决这个问题。 LSTM 由一个存储单元组成,它可以存储与先前信息相关的信息。 门控循环单元 (GRU) 也是 RNN 的一种变体,有助于消除梯度问题。
两者都使用门控机制来解决这个问题。 GRU 使用更少的训练参数,因此比 LSTM 使用更少的内存。 这使 GRU 能够更快地训练,但 LSTM 在输入序列较长的情况下提供更准确的结果。
5. 生成对抗网络(GAN)
生成对抗网络 (GAN) 是一种无监督学习算法,可自动从数据中发现和学习模式。 在学习了这些模式之后,它会生成与输入具有相同特征的新数据作为输出。 它创建了一个模型,该模型分为两个子模型——生成器和鉴别器。
生成器模型尝试从输入生成新图像,而判别器模型的作用是分类数据是来自数据集的真实图像还是来自人工生成的图像(来自生成模型的图像)。
鉴别器模型通常充当卷积神经网络形式的二元分类器。 在每次迭代中,两个模型都试图改进其结果,因为生成器模型的目标是在识别图像时欺骗判别器模型,而判别器的目标是正确识别假图像。
6. 受限玻尔兹曼机(RBM)
受限玻尔兹曼机 (RBM) 是具有生成能力的非确定性神经网络,可以学习输入的概率分布。 它们是玻尔兹曼机的受限形式,受限于层中节点之间的互连。
这些只涉及两层,即可见层和隐藏层。 RBM 中没有输出层,并且层之间是完全连接的。 RBM 现在被郑重地使用,因为它们已被 GAN 取代。 也可以将多个 RBM 组合在一起以创建一个新网络,该网络可以像其他神经网络一样使用梯度下降和反向传播进行调整。 这样的网络被称为深度信念网络。
受限玻尔兹曼机(来源:Medium)
7. 变形金刚
Transformer 是一种神经网络架构,专为神经机器翻译而设计。 它们涉及一种注意力机制,该机制专注于提供给网络的部分信息。 它涉及两个部分:编码器和解码器。
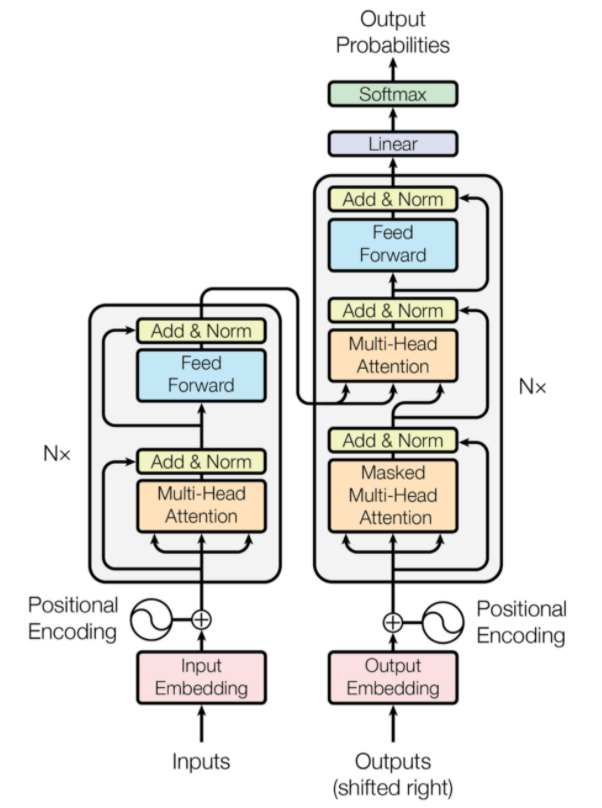
变压器架构(来源:arxiv.org)
图中左边是Encoder,右边是Decoder。 编码器和解码器可以由多个模块组成,这些模块可以相互堆叠。 图中的Nx也是如此。 每个编码器层的功能是找出输入的哪些部分彼此相关,这些部分称为编码。
然后将这些编码作为输入传递到下一个编码器层。 解码器层采用这些编码并对其进行处理以生成输出序列。 注意力机制权衡每个其他输入的重要性并从这些关系中提取信息以预测输出序列。 编码器和解码器层还包括用于进一步处理输出的前馈层。
另请阅读:深度学习与神经网络
结论
本文简要介绍了深度学习领域、神经网络中使用的组件、深度学习算法的思想、简化神经网络的假设等。本文提供了深度学习算法的限制列表,因为有许多不同的算法不断被创造出来,以克服现有算法的局限性。
深度学习算法彻底改变了处理视频、图像、文本等的方式,并且可以通过导入所需的包轻松实现。 最后,对于所有深度学习者来说,无限是极限。
如果您有兴趣了解有关深度学习技术、机器学习的更多信息,请查看 IIIT-B 和 upGrad 的机器学习和深度学习 PG 认证,该认证专为在职专业人士设计,提供 240 多个小时的严格培训、5 个以上的案例研究和分配,IIIT-B 校友身份和顶级公司的工作协助。
CNN和ANN的区别?
人工神经网络 (ANN) 构建与人类神经层平行的网络层:输入、隐藏和输出决策层。 人工神经网络能够感知错误并在出现缺陷后通过自我重组来更新自己。 卷积神经网络 (CNN) 主要关注图像输入。 在 CNN 中,第一层提取原始图像。 下一层对等到上一层中找到的信息。 第三层识别图像的特征,最后一层识别图像。 CNN 不需要明确的输入描述; 他们使用空间特征识别数据。 它们非常适合视觉识别任务。
深度学习是否提供了人工智能的优势?
人工智能 (AI) 使技术更加准确和具有世界代表性。 作为人工智能机器学习的一部分,深度学习可以有效地处理大量数据。 它具有解决问题的点对点方法。 深度学习创建了高效快速的系统,而机器学习系统需要几个步骤才能开始。 尽管深度学习需要大量的训练时间,但它的测试互惠是瞬时的。 不可否认,深度学习是人工智能不可或缺的一部分,并有助于检测听觉和视觉数据。 它使自动语音助手设备、车辆和许多其他技术成为可能。
深度学习的局限性是什么?
深度学习在人机交互方面取得了长足进步,并使技术在许多方面为人类服务。 它具有广泛的培训、昂贵的设备要求和大数据先决条件等障碍。 它提供了自动化的解决方案,但在执行大量算法和神经网络的计算之前,它做出的决策并不明确。 路径追溯到特定节点,这几乎是不可能的; 机器学习具有跟踪过程的直接路径,并且是可取的。 深度学习确实有很多局限性,但它的优势超过了所有这些。