
Algoritmo de aprendizaje profundo [Guía completa con ejemplos]
Publicado: 2020-10-28Tabla de contenido
Introducción
El aprendizaje profundo es un subconjunto del aprendizaje automático, que involucra algoritmos inspirados en la disposición y el funcionamiento del cerebro. Así como las neuronas del cerebro humano transmiten información y ayudan a aprender de los reactores de nuestro cuerpo, de manera similar, los algoritmos de aprendizaje profundo se ejecutan a través de varias capas de algoritmos de redes neuronales y aprenden de sus reacciones.
En otras palabras, el aprendizaje profundo utiliza capas de algoritmos de redes neuronales para descubrir datos de nivel más significativos que dependen de los datos de entrada sin procesar. Los algoritmos de redes neuronales descubren los patrones de datos a través de un proceso que simula cómo funciona un cerebro humano.
Las redes neuronales ayudan a agrupar los puntos de datos de un gran conjunto de puntos de datos en función de las similitudes de las características. Estos sistemas se conocen como Redes Neuronales Artificiales.
A medida que se introdujeron más y más datos en los modelos, los algoritmos de aprendizaje profundo demostraron ser más productivos y brindar mejores resultados que el resto de los algoritmos. Los algoritmos de aprendizaje profundo se utilizan para diversos problemas, como el reconocimiento de imágenes, el reconocimiento de voz, la detección de fraudes, la visión artificial, etc.
Componentes de la red neuronal
1. Topología de red: la topología de red hace referencia a la estructura de la red neuronal. Incluye la cantidad de capas ocultas en la red, la cantidad de neuronas en cada capa, incluida la capa de entrada y salida, etc.
2. Capa de entrada: la capa de entrada es el punto de entrada de la red neuronal. El número de neuronas en la capa de entrada debe ser igual al número de atributos en los datos de entrada.

3. Capa de salida: la capa de salida es el punto de salida de la red neuronal. La cantidad de neuronas en la capa de salida debe ser igual a la cantidad de clases en la variable objetivo (para problemas de clasificación). Para el problema de regresión, la cantidad de neuronas en la capa de salida será 1, ya que la salida sería una variable numérica.
4. Funciones de activación: las funciones de activación son ecuaciones matemáticas que se aplican a la suma de entradas ponderadas de una neurona. Ayuda a determinar si la neurona debe activarse o no. Hay muchas funciones de activación como la función sigmoidea, la unidad lineal rectificada (ReLU), Leaky ReLU, la tangente hiperbólica, la función Softmax, etc.
5. Pesos – Cada interconexión entre las neuronas de las capas consecutivas tiene un peso asociado. Indica la importancia de la conexión entre las neuronas para descubrir algún patrón de datos que ayude a predecir el resultado de la red neuronal. A mayor valor de peso, mayor significación. Es uno de los parámetros que la red aprende durante su fase de entrenamiento.
6. Sesgos : el sesgo ayuda a cambiar la función de activación hacia la izquierda o hacia la derecha, lo que puede ser fundamental para una mejor toma de decisiones. Su papel es análogo al papel de una intersección en la ecuación lineal. Los pesos pueden aumentar la inclinación de la función de activación, es decir, indican qué tan rápido se activará la función de activación, mientras que el sesgo se utiliza para retrasar la activación de la función de activación. Es el segundo parámetro que aprende la red durante su fase de entrenamiento.
Artículo relacionado: Principales técnicas de aprendizaje profundo
Funcionamiento general de una neurona
El aprendizaje profundo funciona con redes neuronales artificiales (ANN) para imitar el funcionamiento de los cerebros humanos y aprender de una manera humana. Las neuronas en las redes neuronales artificiales están dispuestas en capas. La primera y la última capa se denominan capas de entrada y salida. Las capas entre estas dos capas se denominan capas ocultas.
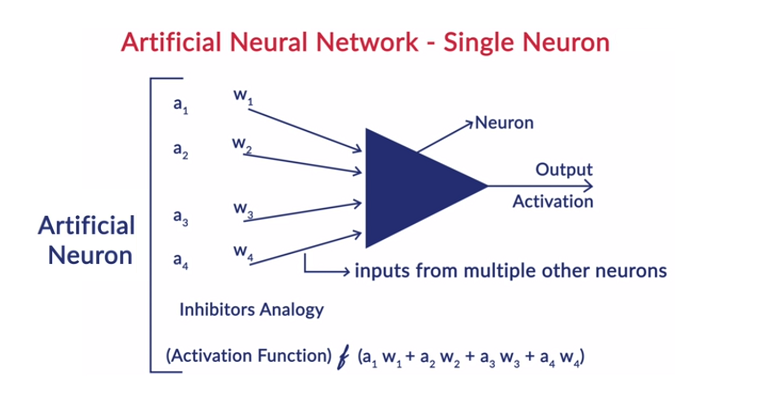
Cada neurona en la capa consta de su propio sesgo y hay un peso asociado para cada interconexión entre las neuronas de la capa anterior a la capa siguiente. Cada entrada se multiplica por el peso asociado a la interconexión.
La suma ponderada de entradas se calcula para cada una de las neuronas en las capas. Se aplica una función de activación a esta suma ponderada de entrada y se suma con polarización de la neurona para producir la salida de la neurona. Esta salida sirve como entrada a las conexiones de esa neurona en la siguiente capa y así sucesivamente.
Este proceso se llama feedforwarding. El resultado de la capa de salida sirve como la decisión final que toma el modelo. El entrenamiento de las redes neuronales se realiza sobre la base del peso de cada interconexión entre las neuronas y el sesgo de cada neurona. Una vez que el modelo predice el resultado final, calcula la pérdida total, que es una función de los pesos y sesgos.
La pérdida total es básicamente la suma de las pérdidas sufridas por todas las neuronas. Como el objetivo final es minimizar la función de costo, el algoritmo retrocede y cambia los pesos y los sesgos en consecuencia. La optimización de la función de costo se puede realizar utilizando el método de descenso de gradiente. Este proceso se conoce como retropropagación.
Supuestos en las Redes Neuronales
- Las neuronas están dispuestas en forma de capas y estas capas están dispuestas de manera secuencial.
- No hay comunicación entre las neuronas que están dentro en la misma capa.
- El punto de entrada de las redes neuronales es la capa de entrada (primera capa) y el punto de salida de las mismas es la capa de salida (última capa).
- Cada interconexión en la red neuronal tiene algún peso asociado y cada neurona tiene un sesgo asociado.
- La misma función de activación se aplica a todas las neuronas en una determinada capa.
Leer: Ideas de proyectos de aprendizaje profundo
Diferentes algoritmos de aprendizaje profundo
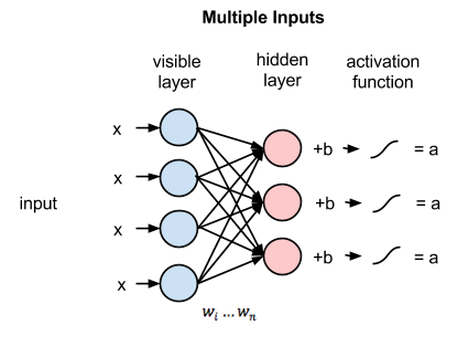
1. Red neuronal totalmente conectada
En la red neuronal totalmente conectada (FCNN), cada neurona de una capa está conectada con todas las demás neuronas de la siguiente capa. Estas capas se conocen como capas densas por la misma razón. Estas capas son muy costosas desde el punto de vista computacional, ya que cada neurona se conecta con todas las demás neuronas.
Se prefiere usar este algoritmo cuando el número de neuronas en las capas es menor, de lo contrario, se requeriría mucha potencia computacional y tiempo para realizar las operaciones. También puede dar lugar a un sobreajuste debido a su conectividad total.
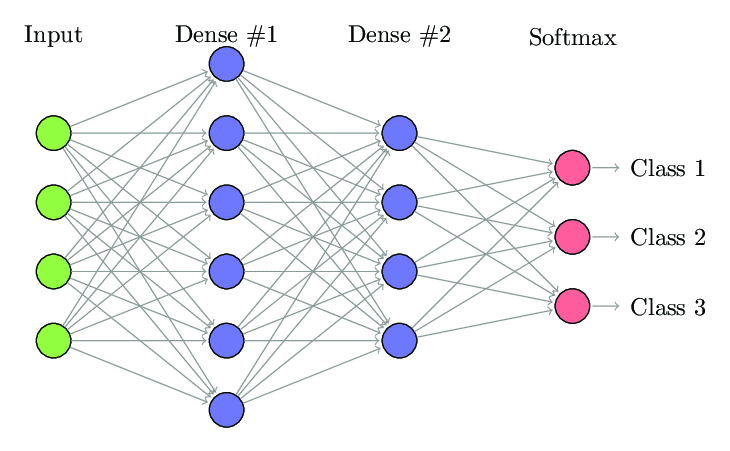
Red neuronal totalmente conectada (Fuente: Researchgate.net)
2. Red neuronal convolucional (CNN)
Las redes neuronales convolucionales (CNN) son una clase de redes neuronales que están diseñadas para trabajar con los datos visuales. es decir, imágenes y videos. Por lo tanto, se utiliza para muchas tareas de procesamiento de imágenes, como el reconocimiento óptico de caracteres (OCR), la localización de objetos, etc. Las CNN también se pueden utilizar para el reconocimiento de video, texto y audio.
Las imágenes están formadas por píxeles que determinan la intensidad de la blancura de la imagen. Cada píxel de una imagen es una característica que se alimentará a la red neuronal. Por ejemplo, una imagen de 128 × 128 indica que la imagen se compone de 16384 píxeles o características. Se alimentará como un vector de tamaño 16384 a la red neuronal. Para imágenes en color, hay 3 canales (uno para cada uno: rojo, azul, verde). En ese caso, la misma imagen en color estaría compuesta por 128x128x3 píxeles.
Hay jerarquía en las capas de la CNN. La primera capa trata de extraer las características sin procesar de las imágenes, como los bordes horizontales o verticales. Las segundas capas extraen más información de las características que extrae la primera capa. Las capas subsiguientes profundizarían más en los detalles para identificar ciertas partes de una imagen, como el cabello, la piel, la nariz, etc. Finalmente, la última capa clasificaría la imagen de entrada como humano, gato, perro, etc.
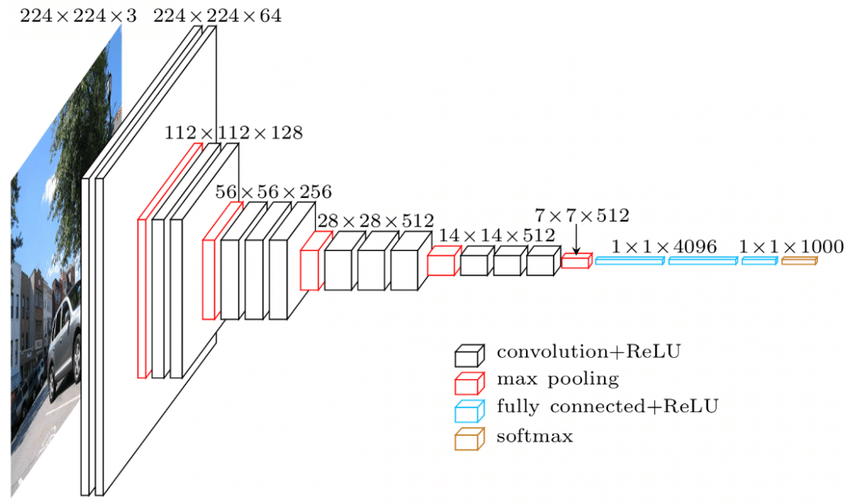
Fuente
Arquitectura VGGNet: una de las CNN más utilizadas
Hay tres terminologías importantes en las CNN:
- Convoluciones: las convoluciones son la suma del producto de elementos de las dos matrices. Una matriz es parte de los datos de entrada y la otra matriz es un filtro que se utiliza para extraer características de la imagen.
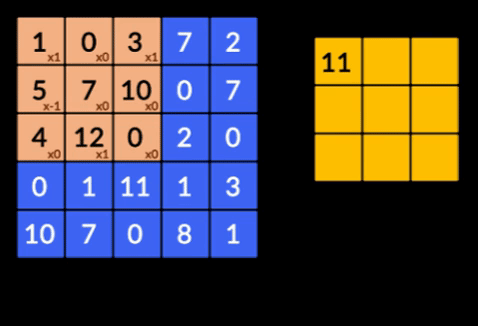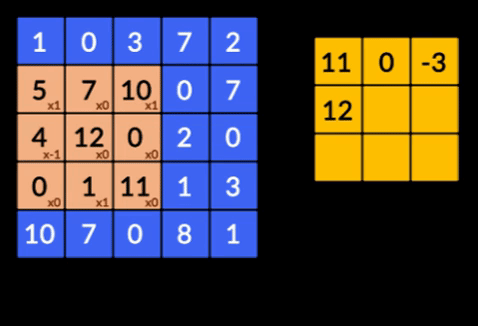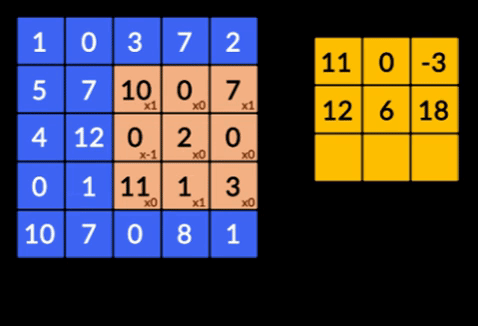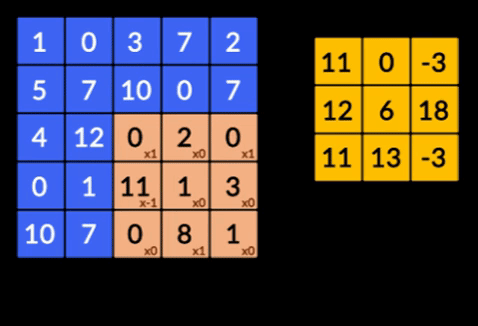
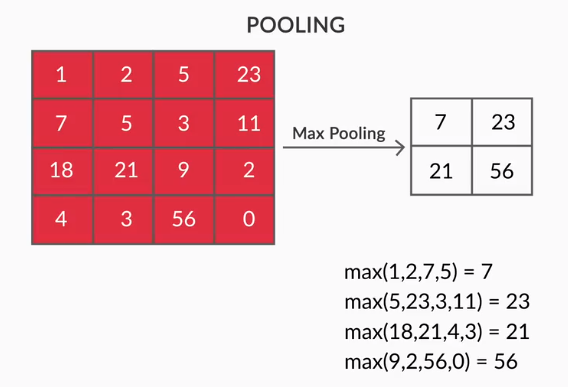
- Capas de agrupación: la agregación de las características extraídas se realiza mediante Capas de agrupación. Estas capas generalmente calculan una estadística agregada (máximo, promedio, etc.) y hacen que la red sea invariable a las transformaciones locales.
- Mapas de funciones: una neurona es CNN es básicamente un filtro cuyos pesos se aprenden durante su entrenamiento. Cada neurona mira una región particular en la entrada que se conoce como su campo receptivo. Un mapa de características es una colección de neuronas que miran diferentes regiones de la imagen con los mismos pesos. Todas las neuronas en un mapa de características intentan extraer la misma característica pero de diferentes regiones de la imagen.
3. Redes neuronales recurrentes (RNN)
Las Redes Neuronales Recurrentes están diseñadas para manejar datos secuenciales. Los datos secuenciales son datos que tienen alguna conexión con los datos anteriores, como texto (secuencia de palabras, oraciones, etc.) o videos (secuencia de imágenes), voz, etc.

Es muy importante comprender la conexión entre estas entidades secuenciales, de lo contrario no tendría sentido desordenar todo el párrafo y tratar de obtener algún significado de él. Los RNN fueron diseñados para procesar estas entidades secuenciales. Un buen ejemplo del uso de RNN es la generación automática de subtítulos en YouTube. No es más que el reconocimiento automático de voz implementado mediante RNN.
La principal diferencia entre las redes neuronales normales y las redes neuronales recurrentes es que los datos de entrada fluyen a lo largo de dos dimensiones: tiempo (a lo largo de la secuencia para extraer características de ella) y profundidad (capas neuronales normales). Hay diferentes tipos de RNN y su estructura cambia en consecuencia.
- Muchos a uno RNN: – En esta arquitectura, la entrada alimentada a la red es una secuencia y la salida es una sola entidad. Esta arquitectura se utiliza para abordar problemas como la clasificación de sentimientos o para predecir la puntuación de sentimiento de los datos de entrada (problema de regresión). También se puede usar para clasificar videos en ciertas categorías.
- Many to Many RNN: – Tanto la entrada como la salida son secuencias en esta arquitectura. Se puede clasificar además en función de la longitud de la entrada y la salida.
- Misma longitud: – La red produce una salida en cada paso de tiempo. Hay una correspondencia uno a uno entre la entrada y la salida en cada paso de tiempo. Esta arquitectura se puede utilizar como un etiquetador de parte del discurso donde cada palabra de la secuencia en la entrada se etiqueta con su parte del discurso como salida en cada paso de tiempo.
- Longitud diferente: – En este caso, la longitud de la entrada no es igual a la longitud de la salida. Uno de los usos de esta arquitectura es la traducción de idiomas. La longitud de una oración en inglés puede ser diferente de la correspondiente oración en hindi.
- Uno a muchos RNN: – La entrada aquí es una sola entidad, mientras que la salida es una secuencia. Este tipo de redes neuronales se utilizan para tareas como la generación de música, imágenes, etc.
- One to One RNN: – Es una red neuronal tradicional en la que la entrada y la salida son entidades únicas.
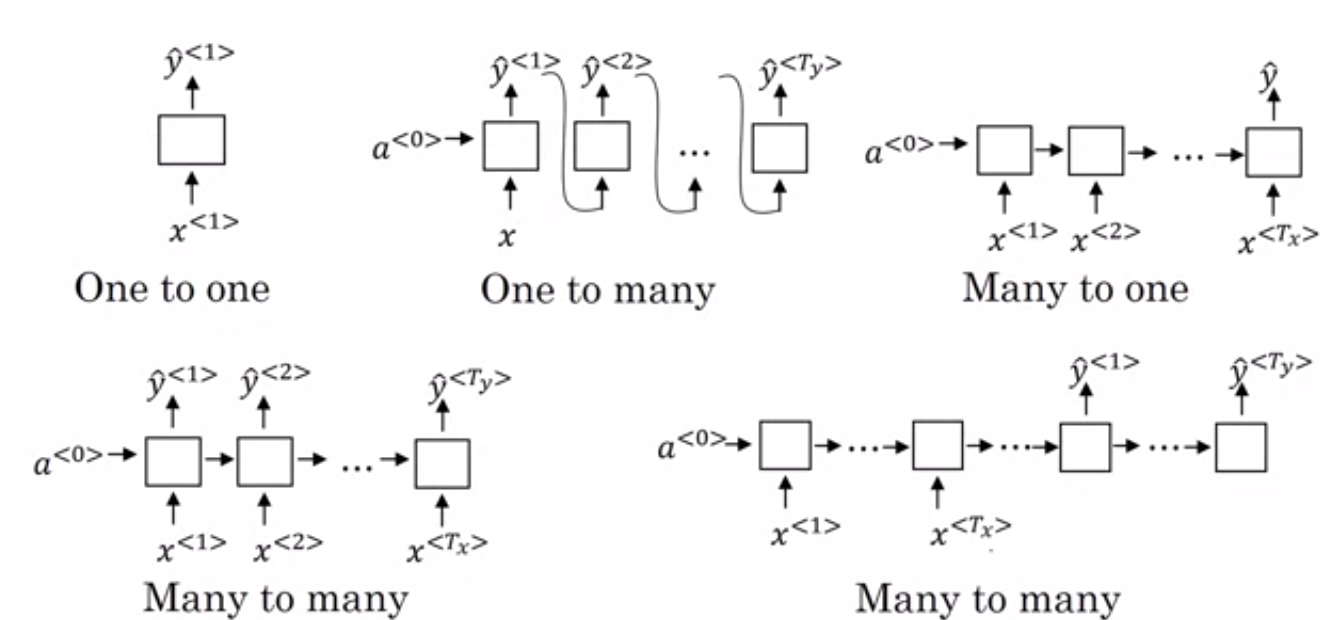
Tipos de RNN (Fuente: iq.opengenus.org)
4. Redes de memoria a largo y corto plazo (LSTM)
Uno de los inconvenientes de las redes neuronales recurrentes es el problema del gradiente de desaparición. Este problema se encuentra cuando estamos entrenando redes neuronales con métodos de aprendizaje basados en gradientes como el descenso de gradiente estocástico y la retropropagación. Los gradientes de la función de activación son los encargados de actualizar los pesos de las redes.
Se vuelven tan pequeños que apenas afecta el peso de las redes neuronales para cambiar. Esto evita que las redes neuronales se entrenen. Los RNN enfrentan este problema cuando tienen dificultades para aprender dependencias a largo plazo.
Las redes de memoria a largo y corto plazo (LSTM) se diseñaron para encontrar este mismo problema. LSTM consta de una unidad de memoria que puede almacenar la información que es relevante para la información anterior. Las unidades recurrentes cerradas (GRU) también son una variante de las RNN que ayudan a desaparecer los problemas de gradiente.
Ambos utilizan un mecanismo de activación para resolver este problema. GRU usa menos parámetros de entrenamiento y, por lo tanto, usa menos memoria que LSTM. Esto permite que las GRU entrenen más rápido, pero LSTM proporciona resultados más precisos cuando las secuencias de entrada son largas.
5. Redes adversarias generativas (GAN)
Generative Adversarial Networks (GAN) es un algoritmo de aprendizaje no supervisado que descubre y aprende automáticamente los patrones de los datos. Después de aprender estos patrones, genera nuevos datos como salida que tienen las mismas características que la entrada. Crea un modelo que se divide en dos submodelos: generador y discriminador.
El modelo generador intenta generar nuevas imágenes a partir de la entrada, mientras que el papel del modelo discriminador es clasificar si los datos son una imagen real del conjunto de datos o de las imágenes generadas artificialmente (imágenes del modelo generado).
El modelo discriminador generalmente actúa como un clasificador binario en forma de red neuronal convolucional. Con cada iteración, ambos modelos intentan mejorar sus resultados, ya que el objetivo del modelo generador es engañar al modelo discriminador para identificar la imagen y el objetivo del discriminador es identificar correctamente las imágenes falsas.
6. Máquina de Boltzmann restringida (RBM)
Las máquinas restringidas de Boltzmann (RBM) son redes neuronales no deterministas con capacidades generativas y aprenden la distribución de probabilidad sobre la entrada. Son una forma restringida de Boltzmann Machine, restringida en términos de las interconexiones entre los nodos en la capa.
Estos involucran solo dos capas, es decir, la capa visible y la capa oculta. No hay una capa de salida en el RBM y las capas están completamente conectadas entre sí. Los RBM ahora se utilizan solemnemente, ya que han sido reemplazados por los GAN. También se pueden unir varios RBM para crear una nueva red que se puede ajustar mediante descenso de gradiente y propagación hacia atrás como las otras redes neuronales. Estas redes se denominan redes de creencias profundas.
Máquina Boltzmann restringida (Fuente: Medio)
7. Transformadores
Los transformadores son un tipo de arquitectura de red neuronal que se diseñó para la traducción automática neuronal. Implican un mecanismo de atención que se centra en una parte de la información que se proporciona a la red. Consta de dos partes: Codificadores y Decodificadores.
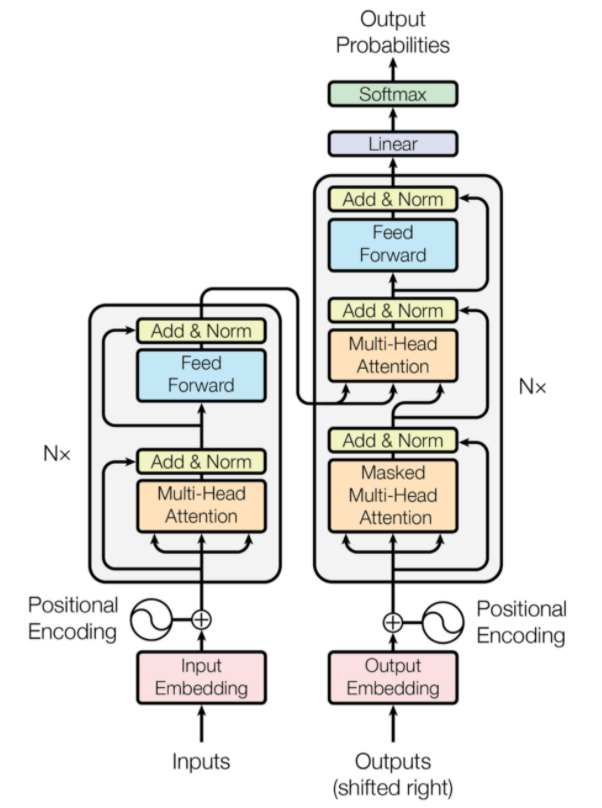
Transformador Arquitectura (Fuente: arxiv.org)
La parte izquierda de la figura es el codificador y la parte derecha es el decodificador. El codificador y el decodificador pueden constar de varios módulos que se pueden apilar uno encima del otro. Lo mismo es transmitido por Nx en la figura. La función de cada capa de codificador es averiguar qué partes de la entrada son relevantes entre sí, lo que se denomina codificaciones.
Estas codificaciones luego se pasan a la siguiente capa de codificador como entradas. La capa del decodificador toma estas codificaciones y las procesa para generar la secuencia de salida. El mecanismo atento sopesa la importancia de cualquier otra entrada y extrae información de estas relaciones para predecir la secuencia de salida. Las capas de codificador y decodificador también consisten en capas de avance que se utilizan para el procesamiento posterior de las salidas.
Lea también: Aprendizaje profundo frente a redes neuronales
Conclusión
El artículo brindó una breve introducción al dominio de aprendizaje profundo, los componentes utilizados en las redes neuronales, la idea de los algoritmos de aprendizaje profundo, las suposiciones hechas para simplificar las redes neuronales, etc. Este artículo proporciona una lista restringida de algoritmos de aprendizaje profundo, ya que hay una gran cantidad de algoritmos diferentes que se crean constantemente para superar las limitaciones de los algoritmos existentes.
Los algoritmos de aprendizaje profundo han revolucionado la forma de procesar videos, imágenes, texto, etc. y se pueden implementar fácilmente importando los paquetes necesarios. Por último, para todos los Deep Learners, Infinity es el límite.
Si está interesado en obtener más información sobre técnicas de aprendizaje profundo , aprendizaje automático, consulte la certificación PG de IIIT-B y upGrad en aprendizaje automático y aprendizaje profundo, que está diseñada para profesionales que trabajan y ofrece más de 240 horas de capacitación rigurosa, más de 5 estudios de casos y asignaciones, estado de ex alumnos de IIIT-B y asistencia laboral con las mejores empresas.
¿Diferencia entre CNN y ANN?
Las redes neuronales artificiales (ANN) construyen capas de red paralelas a las capas neuronales humanas: capas de decisión de entrada, ocultas y de salida. Las ANN son perceptivas de las fallas y se actualizan reestructurándose después de una falla. Las redes neuronales convolucionales (CNN) se centran principalmente en la entrada de imágenes. En las CNN, la primera capa extrae la imagen en bruto. La siguiente capa examina la información que se encuentra en la capa anterior. La tercera capa identifica las características de la imagen y la capa final reconoce la imagen. Las CNN no requieren descripciones de entrada explícitas; Reconocen datos usando características espaciales. Son muy preferidos para tareas de reconocimiento visual.
¿El aprendizaje profundo proporciona una ventaja en inteligencia artificial?
La Inteligencia Artificial (IA) ha hecho que la tecnología sea más precisa y representativa del mundo. Como parte del aprendizaje automático en IA, el aprendizaje profundo puede procesar de manera eficiente grandes cantidades de datos. Tiene un enfoque de punto a punto para resolver problemas. Deep Learning ha creado sistemas eficientes y rápidos, mientras que los sistemas de Machine Learning tienen varios pasos para comenzar. Aunque Deep Learning necesita mucho tiempo de entrenamiento, su reciprocidad de prueba es instantánea. El aprendizaje profundo es sin duda una parte integral de la inteligencia artificial y ha contribuido a detectar datos auditivos y visuales. Ha hecho posibles los dispositivos de asistente de voz automatizados, los vehículos y muchas otras tecnologías.
¿Cuáles son las limitaciones del aprendizaje profundo?
Deep Learning ha hecho grandes avances en la interacción máquina-humano y ha hecho que la tecnología sea útil para la humanidad de muchas maneras. Tiene obstáculos de capacitación extensa, requisitos de equipos costosos y requisitos previos de datos grandes. Proporciona soluciones automatizadas, pero toma decisiones que no quedan claras hasta que se realiza el cómputo de numerosos algoritmos y redes neuronales. El camino se remonta a los nodos específicos, lo cual es casi imposible; Machine Learning tiene un camino directo de seguimiento de procesos y es preferible. Deep Learning tiene muchas limitaciones, pero sus ventajas las superan todas.