
Algoritm de învățare profundă [Ghid cuprinzător cu exemple]
Publicat: 2020-10-28Cuprins
Introducere
Deep Learning este un subset al învățării automate, care implică algoritmi inspirați de aranjarea și funcționarea creierului. Pe măsură ce neuronii din creierul uman transmit informații și ajută la învățarea de la reactoarele din corpul nostru, în mod similar algoritmii de învățare profundă trec prin diferite straturi de algoritmi de rețele neuronale și învață din reacțiile lor.
Cu alte cuvinte, învățarea profundă utilizează straturi de algoritmi de rețea neuronală pentru a descoperi date de nivel mai semnificative, dependente de datele brute de intrare. Algoritmii rețelei neuronale descoperă tiparele de date printr-un proces care simulează într-un fel cum funcționează creierul uman.
Rețelele neuronale ajută la gruparea punctelor de date dintr-un set mare de puncte de date pe baza asemănărilor caracteristicilor. Aceste sisteme sunt cunoscute sub denumirea de rețele neuronale artificiale.
Pe măsură ce modelele au fost furnizate din ce în ce mai multe date, algoritmii de învățare profundă s-au dovedit a fi mai productivi și oferă rezultate mai bune decât restul algoritmilor. Algoritmii de învățare profundă sunt utilizați pentru diverse probleme, cum ar fi recunoașterea imaginilor, recunoașterea vorbirii, detectarea fraudelor, viziunea computerizată etc.
Componentele rețelei neuronale
1. Topologia rețelei – Topologia rețelei se referă la structura rețelei neuronale. Include numărul de straturi ascunse din rețea, numărul de neuroni din fiecare strat, inclusiv stratul de intrare și de ieșire etc.
2. Stratul de intrare – Stratul de intrare este punctul de intrare al rețelei neuronale. Numărul de neuroni din stratul de intrare ar trebui să fie egal cu numărul de atribute din datele de intrare.

3. Stratul de ieșire – Stratul de ieșire este punctul de ieșire al rețelei neuronale. Numărul de neuroni din stratul de ieșire ar trebui să fie egal cu numărul de clase din variabila țintă (Pentru problema de clasificare). Pentru problema de regresie, numărul de neuroni din stratul de ieșire va fi 1, deoarece rezultatul ar fi o variabilă numerică.
4. Funcții de activare – Funcțiile de activare sunt ecuații matematice care se aplică sumei intrărilor ponderate ale unui neuron. Ajută la determinarea dacă neuronul ar trebui să fie declanșat sau nu. Există multe funcții de activare, cum ar fi funcția sigmoidă, Unitatea liniară rectificată (ReLU), Leaky ReLU, Tangenta hiperbolică, funcția Softmax etc.
5. Greutăți – Fiecare interconexiune dintre neuronii din straturile consecutive are asociată o greutate. Indică semnificația conexiunii dintre neuroni în descoperirea unor modele de date care ajută la prezicerea rezultatului rețelei neuronale. Cu cât valorile greutății sunt mai mari, cu atât este mai mare semnificația. Este unul dintre parametrii pe care rețeaua îi învață în timpul fazei de antrenament.
6. Prejudecăți – Prejudecățile ajută la deplasarea funcției de activare la stânga sau la dreapta, ceea ce poate fi critic pentru o mai bună luare a deciziilor. Rolul său este analog cu rolul unei interceptări în ecuația liniară. Greutățile pot crește gradul de înclinare a funcției de activare, adică indică cât de repede se va declanșa funcția de activare, în timp ce părtinirea este utilizată pentru a întârzia declanșarea funcției de activare. Este al doilea parametru pe care îl învață rețeaua în timpul fazei de antrenament.
Articol înrudit: Top tehnici de învățare profundă
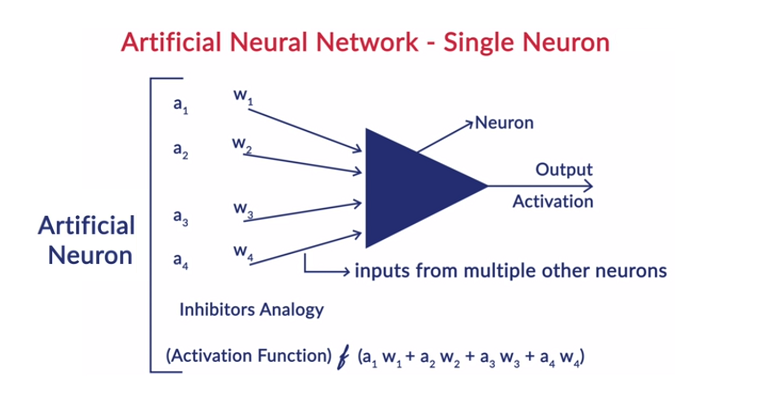
Funcționarea generală a unui neuron
Deep Learning funcționează cu rețelele neuronale artificiale (ANN-uri) pentru a imita funcționarea creierului uman și pentru a învăța într-un fel în care o face omul. Neuronii din rețelele neuronale artificiale sunt aranjați în straturi. Primul și ultimul strat se numesc straturile de intrare și de ieșire. Straturile dintre aceste două straturi sunt numite straturi ascunse.
Fiecare neuron din strat constă din propria sa părtinire și există o pondere asociată pentru fiecare interconexiune dintre neuronii din stratul anterior la stratul următor. Fiecare intrare este înmulțită cu greutatea asociată cu interconectarea.
Suma ponderată a intrărilor este calculată pentru fiecare neuron din straturi. O funcție de activare este aplicată acestei sume ponderate de intrare și adăugată cu părtinirea neuronului pentru a produce ieșirea neuronului. Această ieșire servește ca intrare la conexiunile acelui neuron din stratul următor și așa mai departe.
Acest proces este numit feedforwarding. Rezultatul stratului de ieșire servește drept decizie finală luată de model. Antrenamentul rețelelor neuronale se face pe baza ponderii fiecărei interconexiuni dintre neuroni și a părtinirii fiecărui neuron. După ce rezultatul final este prezis de model, acesta calculează pierderea totală, care este o funcție de ponderi și părtiniri.
Pierderea totală este practic suma pierderilor suferite de toți neuronii. Deoarece scopul final este de a minimiza funcția de cost, algoritmul dă înapoi și modifică ponderile și prejudecățile în consecință. Optimizarea funcției de cost se poate face folosind metoda de coborâre a gradientului. Acest proces este cunoscut sub numele de backpropagation.
Ipoteze în rețelele neuronale
- Neuronii sunt aranjați sub formă de straturi, iar aceste straturi sunt aranjate într-o manieră secvențială.
- Nu există nicio comunicare între neuronii care se află în același strat.
- Punctul de intrare al rețelelor neuronale este stratul de intrare (primul strat), iar punctul de ieșire al acestora este stratul de ieșire (ultimul strat).
- Fiecare interconexiune din rețeaua neuronală are o anumită pondere asociată cu ea și fiecare neuron are o părtinire asociată cu ea.
- Aceeași funcție de activare este aplicată tuturor neuronilor dintr-un anumit strat.
Citiți: Idei de proiecte de învățare profundă
Algoritmi diferiți de învățare profundă
1. Rețea neuronală complet conectată
În rețeaua neuronală complet conectată (FCNN), fiecare neuron dintr-un strat este conectat la fiecare alt neuron din stratul următor. Aceste straturi sunt denumite straturi dense din același motiv. Aceste straturi sunt foarte costisitoare din punct de vedere computațional, deoarece fiecare neuron se conectează cu toți ceilalți neuroni.
Este de preferat să se folosească acest algoritm atunci când numărul de neuroni din straturi este mai mic, altfel ar necesita multă putere de calcul și timp pentru a efectua operațiile. De asemenea, poate duce la supraadaptare datorită conectivității complete.
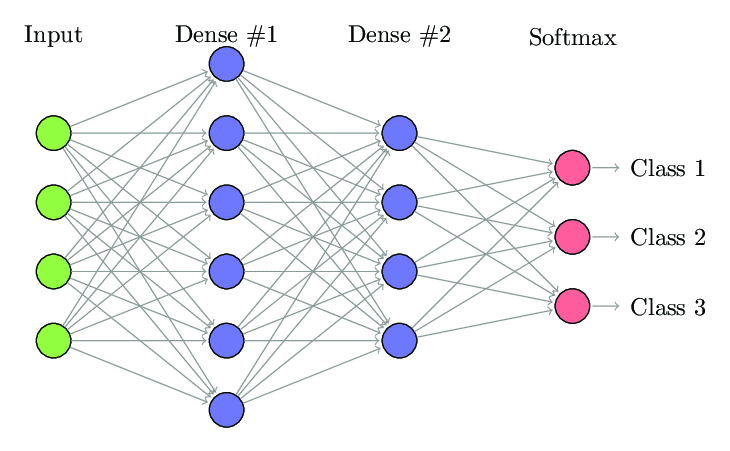
Rețea neuronală complet conectată (Sursa: Researchgate.net)
2. Rețeaua neuronală convoluțională (CNN)
Rețelele neuronale convoluționale (CNN) sunt o clasă de rețele neuronale care sunt concepute pentru a funcționa cu datele vizuale. adică imagini și videoclipuri. Astfel, este folosit pentru multe sarcini de procesare a imaginilor, cum ar fi recunoașterea optică a caracterelor (OCR), localizarea obiectelor etc. CNN-urile pot fi utilizate și pentru recunoașterea video, text și audio.
Imaginile sunt formate din pixeli care determină intensitatea albului din imagine. Fiecare pixel al unei imagini este o caracteristică care va fi transmisă rețelei neuronale. De exemplu, o imagine de 128×128 indică că imaginea este formată din 16384 pixeli sau caracteristici. Acesta va fi alimentat ca un vector de dimensiunea 16384 la rețeaua neuronală. Pentru imaginile color, există 3 canale (câte unul pentru fiecare – roșu, albastru, verde). În acest caz, aceeași imagine în culoare ar fi formată de 128x128x3 pixeli.
Există ierarhie în straturile CNN. Primul strat încearcă să extragă caracteristicile brute ale imaginilor, cum ar fi marginile orizontale sau verticale. Al doilea strat extrage mai multe informații din caracteristicile care sunt extrase de primul strat. Straturile ulterioare s-ar scufunda apoi mai adânc în specificul pentru a identifica anumite părți ale unei imagini, cum ar fi părul, pielea, nasul etc. În cele din urmă, ultimul strat ar clasifica imaginea de intrare ca uman, pisică, câine etc.
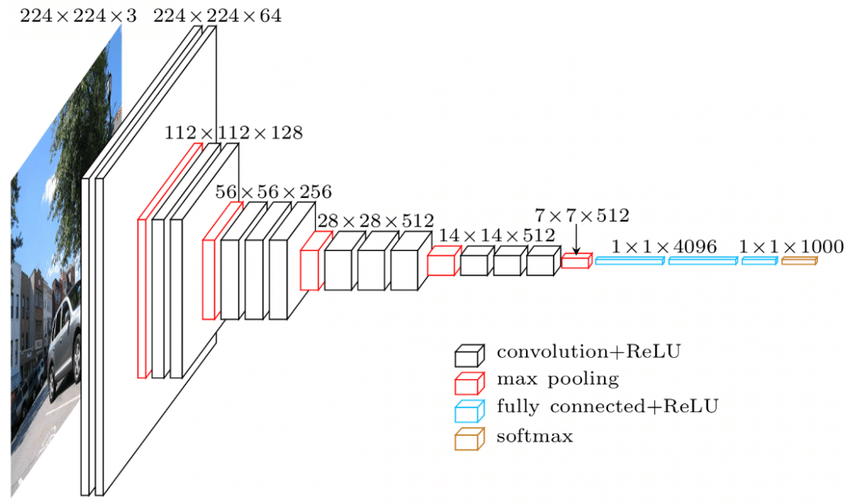
Sursă
Arhitectura VGGNet – Unul dintre CNN-urile utilizate pe scară largă
Există trei terminologii importante în CNN-uri:
- Convoluții – Convoluțiile este însumarea produsului în funcție de elemente a celor două matrici. O matrice este o parte a datelor de intrare, iar cealaltă matrice este un filtru care este folosit pentru a extrage caracteristici din imagine.
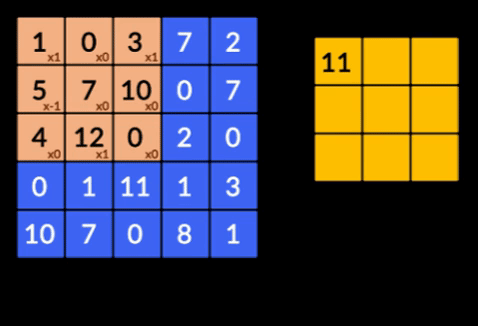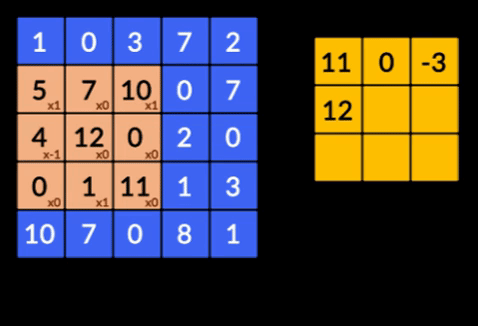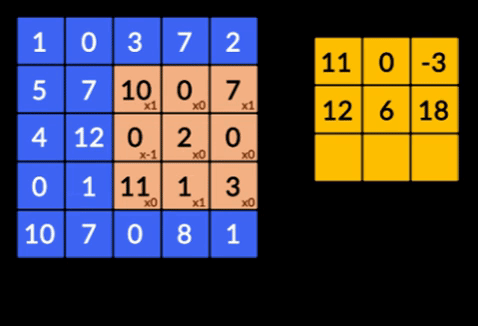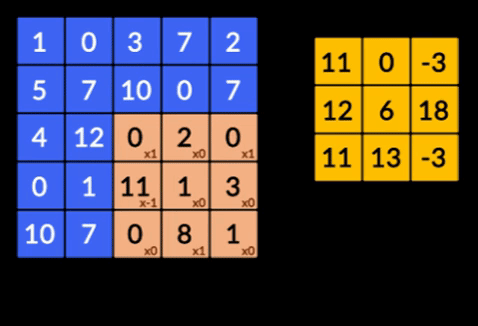
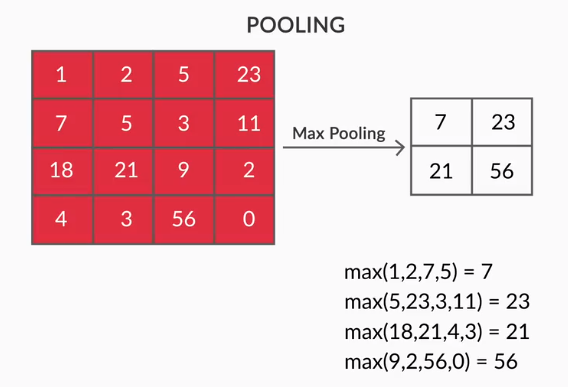
- Pooling Layers – Agregarea caracteristicilor extrase se face prin Pooling Layers. Aceste straturi calculează, în general, o statistică agregată (max, medie etc) și fac rețeaua invariabilă la transformările locale.
- Hărți de caracteristici – Un neuron este CNN este practic un filtru ale cărui greutăți sunt învățate în timpul antrenamentului. Fiecare neuron se uită la o anumită regiune din intrare care este cunoscută sub numele de câmpul său receptiv. O hartă caracteristică este o colecție de astfel de neuroni care privesc diferite regiuni ale imaginii cu aceleași greutăți. Toți neuronii dintr-o hartă de caracteristici încearcă să extragă aceeași caracteristică, dar din regiuni diferite ale imaginii.
3. Rețele neuronale recurente (RNN)
Rețelele neuronale recurente sunt concepute pentru a trata date secvențiale. Date secvențiale înseamnă date care au o anumită legătură cu datele anterioare, cum ar fi text (secvență de cuvinte, propoziții etc.) sau videoclipuri (secvență de imagini), vorbire etc.

Este foarte important să înțelegem legătura dintre aceste entități secvențiale, altfel nu ar avea sens să amestecăm întregul paragraf și să încercăm să obținem un sens din el. RNN-urile au fost concepute pentru a procesa aceste entități secvențiale. Un bun exemplu de utilizare a RNN-urilor este generarea automată de subtitrări pe YouTube. Nu este altceva decât Recunoașterea automată a vorbirii implementată folosind RNN-uri.
Principala diferență dintre rețelele neuronale normale și rețelele neuronale recurente este că datele de intrare circulă de-a lungul a două dimensiuni - timp (de-a lungul lungimii secvenței pentru a extrage caracteristicile din ea) și adâncime (straturi neuronale normale). Există diferite tipuri de RNN și structura lor se modifică în consecință.
- Many to One RNN: – În această arhitectură, intrarea alimentată în rețea este o secvență, iar ieșirea este o singură entitate. Această arhitectură este utilizată pentru a rezolva probleme precum clasificarea sentimentelor sau pentru a prezice scorul de sentiment al datelor de intrare (problema de regresie). Poate fi folosit și pentru a clasifica videoclipurile în anumite categorii.
- Many to Many RNN: – Ambele, intrarea și ieșirea sunt secvențe în această arhitectură. Poate fi clasificat în continuare pe baza lungimii intrării și ieșirii.
- Aceeași lungime: – Rețeaua produce o ieșire la fiecare pas de timp. Există o corespondență unu la unu între intrare și ieșire la fiecare pas de timp. Această arhitectură poate fi utilizată ca o parte a etichetării vorbirii în care fiecare cuvânt al secvenței din intrare este etichetat cu partea sa de vorbire ca ieșire la fiecare pas de timp.
- Lungime diferită: – În acest caz, lungimea intrării nu este egală cu lungimea ieșirii. Una dintre utilizările acestei arhitecturi este traducerea limbilor. Lungimea unei propoziții în engleză poate fi diferită de propoziția corespunzătoare în hindi.
- One to Many RNN: – Intrarea aici este o singură entitate, în timp ce ieșirea este o secvență. Aceste tipuri de rețele neuronale sunt folosite pentru sarcini precum generarea de muzică, imagini etc.
- One to One RNN: – Este o rețea neuronală tradițională în care intrarea și ieșirea sunt entități unice.
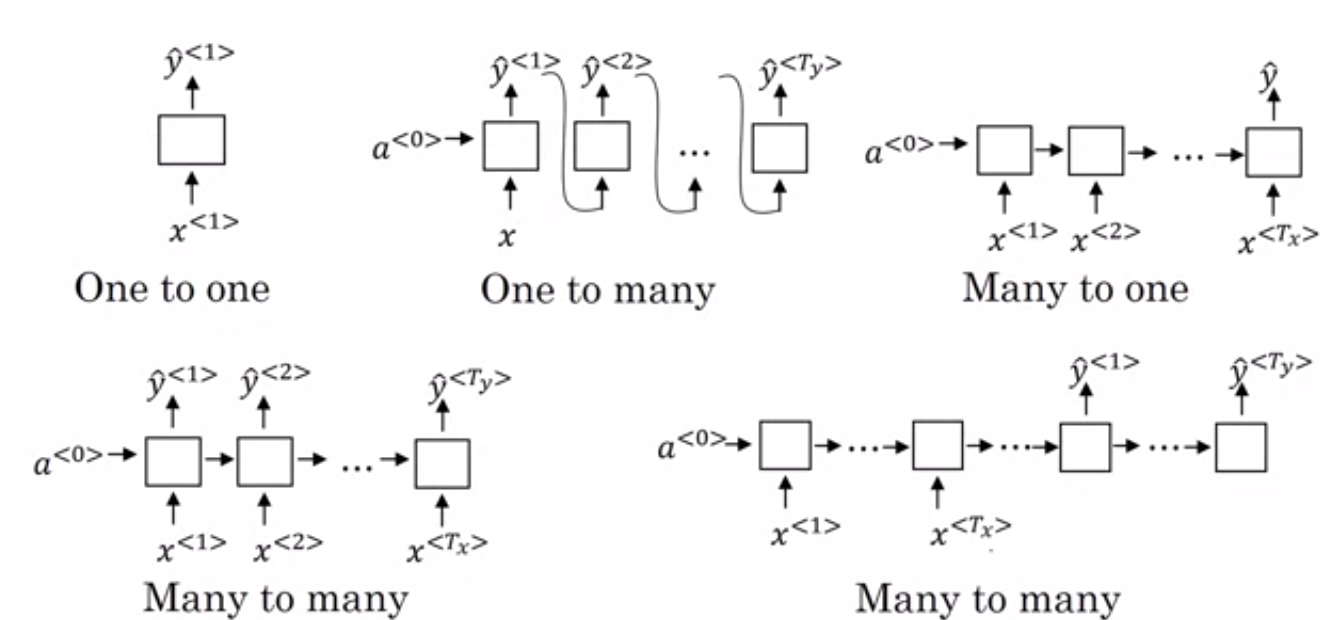
Tipuri de RNN (Sursa: iq.opengenus.org)
4. Rețele de memorie pe termen lung și scurt (LSTM)
Unul dintre dezavantajele rețelelor neuronale recurente este problema gradientului de dispariție. Această problemă se întâlnește atunci când antrenăm rețele neuronale cu metode de învățare bazate pe gradient, cum ar fi coborârea gradientului stocastic și propagarea inversă. Gradienții funcției de activare sunt responsabili pentru actualizarea greutăților rețelelor.
Ele devin atât de mici încât cu greu afectează modificarea greutăților rețelelor neuronale. Acest lucru împiedică antrenamentul rețelelor neuronale. RNN-urile se confruntă cu această problemă atunci când întâmpină dificultăți în a învăța dependențe pe termen lung.
Rețelele de memorie pe termen lung și scurt (LSTM) au fost concepute pentru a întâmpina tocmai această problemă. LSTM constă dintr-o unitate de memorie care poate stoca informațiile care sunt relevante pentru informațiile anterioare. Gated Recurrent Units (GRU) sunt, de asemenea, o variantă a RNN-urilor care ajută la dispariția problemelor de gradient.
Ambele folosesc un mecanism de deschidere pentru a rezolva această problemă. GRU folosește mai puțini parametri de antrenament și astfel utilizează mai puțină memorie decât LSTM. Acest lucru permite GRU-urilor să se antreneze mai rapid, dar LSTM oferă rezultate mai precise acolo unde secvențele de intrare sunt lungi.
5. Rețele generative adversare (GAN)
Generative Adversarial Networks (GAN) este un algoritm de învățare nesupravegheat care descoperă și învață automat tiparele din date. După învățarea acestor modele, generează date noi ca ieșire, care au aceleași caracteristici ca și intrarea. Acesta creează un model care este împărțit în două submodele – generator și discriminator.
Modelul generator încearcă să genereze noi imagini din intrare, în timp ce rolul modelului discriminator este de a clasifica dacă datele sunt o imagine reală din setul de date sau din imaginile generate artificial (imaginile din modelul generat).
Modelul discriminator acționează în general ca un clasificator binar sub formă de rețea neuronală convoluțională. Cu fiecare iterație, ambele modele încearcă să-și îmbunătățească rezultatele, deoarece scopul modelului generator este să păcălească modelul discriminator în identificarea imaginii, iar scopul discriminatorului este să identifice corect imaginile false.
6. Masina Boltzmann restricționată (RBM)
Restricted Boltzmann Machine (RBM) sunt rețele neuronale nedeterministe cu capacități generative și învață distribuția probabilității pe intrare. Sunt o formă restrânsă de mașină Boltzmann, restricționată în termenii interconexiunilor dintre nodurile din strat.
Acestea implică doar două straturi, adică strat vizibil și strat ascuns. Nu există un strat de ieșire în RBM și straturile sunt complet conectate între ele. RBM-urile sunt acum utilizate solemn, deoarece au fost înlocuite de GAN-urile. Mai multe RBM-uri pot fi, de asemenea, adunate pentru a crea o nouă rețea care poate fi reglată folosind coborârea gradientului și propagarea inversă, ca și celelalte rețele neuronale. Astfel de rețele sunt numite rețele de credință profundă.
Masina Boltzmann restrictionata (Sursa: Medie)
7. Transformatoare
Transformatoarele sunt un tip de arhitectură de rețea neuronală care au fost concepute pentru traducerea automată neuronală. Ele implică un mecanism de atenție care se concentrează pe o parte din informațiile furnizate rețelei. Acesta implică două părți: codificatoare și decodificatoare.
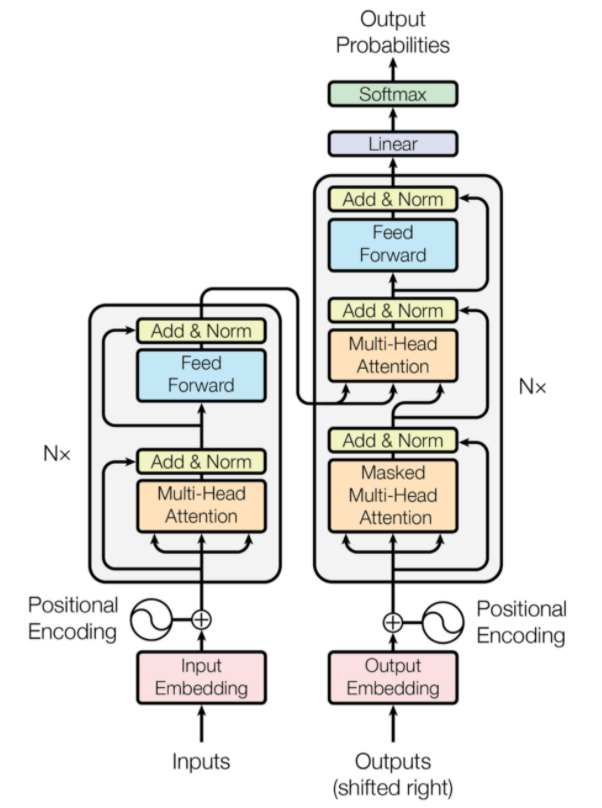
Arhitectura transformatoarelor (Sursa: arxiv.org)
Partea din stânga a figurii este Encoder, iar partea dreaptă este Decoder. Codificatorul și decodorul pot consta din mai multe module care pot fi stivuite unul peste celălalt. Același lucru este transmis de Nx în figură. Funcția fiecărui strat de codificator este de a afla care părți ale intrării sunt relevante unele pentru altele, care sunt denumite codificări.
Aceste codificări sunt apoi transmise următorului strat de codificator ca intrări. Stratul de decodor preia aceste codificări și le procesează pentru a genera secvența de ieșire. Mecanismul atent cântărește semnificația oricărei alte intrări și extrage informații din aceste relații pentru a prezice secvența de ieșire. Straturile de codificator și decodor constau, de asemenea, din straturi de feed forward care sunt utilizate pentru procesarea ulterioară a ieșirilor.
Citește și: Deep Learning vs Neural Networks
Concluzie
Articolul a oferit o scurtă introducere în domeniul Deep Learning, componentele utilizate în rețelele neuronale, ideea algoritmilor de deep learning, ipotezele făcute pentru simplificarea rețelelor neuronale etc. Acest articol oferă o listă restrânsă de algoritmi de deep learning, deoarece există o mulțime de algoritmi diferiți care sunt în mod constant creați pentru a depăși limitările algoritmilor existenți.
Algoritmii de Deep Learning au revoluționat modul de procesare a videoclipurilor, imaginilor, textului etc. și pot fi implementați cu ușurință prin importul pachetelor necesare. În cele din urmă, pentru toți cei care învață profund, infinitul este limita.
Dacă sunteți interesat să aflați mai multe despre tehnicile de învățare profundă , învățarea automată, consultați Certificarea PG de la IIIT-B și upGrad în învățare automată și învățare profundă, care este concepută pentru profesioniști care lucrează și oferă peste 240 de ore de formare riguroasă, peste 5 studii de caz & misiuni, statutul de absolvenți IIIT-B și asistență la locul de muncă cu firme de top.
Diferența dintre CNN și ANN?
Rețelele neuronale artificiale (ANN) construiesc straturi de rețea paralele cu straturile neuronale umane: straturi de decizie de intrare, ascunse și de ieșire. ANN-urile sunt perceptive cu privire la defecțiuni și se actualizează prin restructurare după un neajuns. Rețelele neuronale convoluționale (CNN) sunt concentrate în principal pe intrarea imaginii. În CNN-urile, primul strat extrage imaginea brută. Următorul strat analizează informațiile găsite în stratul anterior. Al treilea strat identifică caracteristicile imaginii, iar stratul final recunoaște imaginea. CNN-urile nu necesită descrieri explicite de intrare; Ei recunosc datele folosind caracteristici spațiale. Sunt foarte preferați pentru sarcinile de recunoaștere vizuală.
Deep Learning oferă un avantaj în inteligența artificială?
Inteligența artificială (AI) a făcut tehnologia mai precisă și mai reprezentativă pentru lume. Ca parte a Machine Learning în AI, Deep Learning poate procesa eficient cantități mari de date. Are o abordare punct la punct pentru rezolvarea problemelor. Deep Learning a creat sisteme eficiente și rapide, în timp ce sistemele de învățare automată au câțiva pași pentru a începe. Deși Deep Learning necesită mult timp de antrenament, reciprocitatea sa de testare este instantanee. Deep Learning este, fără îndoială, o parte integrantă a inteligenței artificiale și a contribuit la detectarea datelor auditive și vizuale. A făcut posibile dispozitive automate de asistență vocală, vehicule și multe alte tehnologii.
Care sunt limitările Deep Learning?
Deep Learning a făcut progrese în interacțiunea mașină-om și a făcut tehnologia utilă pentru omenire în multe feluri. Are obstacole de pregătire extinsă, cerințe de echipamente costisitoare și cerințe preliminare mari de date. Oferă soluții automate, dar ia decizii care nu sunt clare până când nu se realizează calculul a numeroși algoritmi și rețele neuronale. Calea este urmărită înapoi la nodurile specifice, ceea ce este aproape imposibil; Învățarea automată are o cale dreaptă a proceselor de urmărire și este de preferat. Deep Learning are multe limitări, dar avantajele sale le depășesc pe toate.