
Algoritma Pembelajaran Mendalam [Panduan Komprehensif Dengan Contoh]
Diterbitkan: 2020-10-28Daftar isi
pengantar
Deep Learning adalah bagian dari pembelajaran mesin, yang melibatkan algoritme yang terinspirasi oleh pengaturan dan fungsi otak. Saat neuron dari otak manusia mengirimkan informasi dan membantu dalam belajar dari reaktor di tubuh kita, begitu pula algoritma pembelajaran mendalam berjalan melalui berbagai lapisan algoritma jaringan saraf dan belajar dari reaksi mereka.
Dengan kata lain, Deep learning menggunakan lapisan algoritme jaringan saraf untuk menemukan data tingkat yang lebih signifikan bergantung pada data input mentah. Algoritme jaringan saraf menemukan pola data melalui proses yang mensimulasikan cara kerja otak manusia.
Jaringan saraf membantu dalam mengelompokkan titik data dari kumpulan besar titik data berdasarkan kesamaan fitur. Sistem ini dikenal sebagai Jaringan Syaraf Tiruan.
Karena semakin banyak data yang dimasukkan ke model, algoritme pembelajaran mendalam terbukti lebih produktif dan memberikan hasil yang lebih baik daripada algoritme lainnya. Algoritma Deep Learning digunakan untuk berbagai masalah seperti pengenalan gambar, pengenalan suara, deteksi penipuan, visi komputer, dll.
Komponen Jaringan Syaraf
1. Topologi Jaringan – Topologi Jaringan mengacu pada struktur jaringan saraf. Ini termasuk jumlah lapisan tersembunyi dalam jaringan, jumlah neuron di setiap lapisan termasuk lapisan input dan output dll.
2. Input Layer – Input Layer adalah titik masuk dari jaringan saraf. Jumlah neuron pada lapisan input harus sama dengan jumlah atribut pada data input.

3. Output Layer – Output Layer adalah titik keluar dari jaringan saraf. Jumlah neuron pada lapisan keluaran harus sama dengan jumlah kelas pada variabel target (Untuk masalah klasifikasi). Untuk masalah regresi, jumlah neuron pada lapisan keluaran akan menjadi 1 karena keluarannya akan berupa variabel numerik.
4. Fungsi aktivasi – Fungsi aktivasi adalah persamaan matematis yang berlaku untuk jumlah input berbobot neuron. Ini membantu dalam menentukan apakah neuron harus dipicu atau tidak. Ada banyak fungsi aktivasi seperti fungsi sigmoid, Rectified Linear Unit (ReLU), Leaky ReLU, Hyperbolic Tangent, fungsi Softmax dll.
5. Bobot – Setiap interkoneksi antara neuron di lapisan berurutan memiliki bobot yang terkait dengannya. Ini menunjukkan pentingnya hubungan antara neuron dalam menemukan beberapa pola data yang membantu dalam memprediksi hasil dari jaringan saraf. Semakin tinggi nilai bobot, semakin tinggi signifikansinya. Ini adalah salah satu parameter yang dipelajari jaringan selama fase pelatihannya.
6. Bias – Bias membantu dalam menggeser fungsi aktivasi ke kiri atau kanan yang dapat menjadi penting untuk pengambilan keputusan yang lebih baik. Perannya analog dengan peran intersep dalam persamaan linier. Bobot dapat meningkatkan kecuraman fungsi aktivasi yaitu menunjukkan seberapa cepat fungsi aktivasi akan memicu sedangkan bias digunakan untuk menunda pemicuan fungsi aktivasi. Ini adalah parameter kedua yang dipelajari jaringan selama fase pelatihannya.
Artikel Terkait: Teknik Pembelajaran Mendalam Teratas
Kerja Umum Neuron
Deep Learning bekerja dengan Jaringan Syaraf Tiruan (JST) untuk meniru kerja otak manusia dan belajar dengan cara yang dilakukan manusia. Neuron dalam jaringan syaraf tiruan tersusun berlapis-lapis. Lapisan pertama dan terakhir disebut lapisan input dan output. Lapisan di antara kedua lapisan ini disebut lapisan tersembunyi.
Setiap neuron pada lapisan tersebut terdiri dari biasnya sendiri dan ada bobot yang terkait untuk setiap interkoneksi antara neuron dari lapisan sebelumnya ke lapisan berikutnya. Setiap input dikalikan dengan bobot yang terkait dengan interkoneksi.
Jumlah bobot input dihitung untuk setiap neuron di lapisan. Fungsi aktivasi diterapkan pada jumlah input yang tertimbang ini dan ditambahkan dengan bias neuron untuk menghasilkan output neuron. Output ini berfungsi sebagai input ke koneksi neuron itu di lapisan berikutnya dan seterusnya.
Proses ini disebut sebagai feedforwarding. Hasil dari lapisan keluaran berfungsi sebagai keputusan akhir yang dibuat oleh model. Pelatihan jaringan saraf dilakukan berdasarkan bobot setiap interkoneksi antara neuron dan bias setiap neuron. Setelah hasil akhir diprediksi oleh model, model menghitung total kerugian yang merupakan fungsi dari bobot dan bias.
Total Loss pada dasarnya adalah jumlah kerugian yang ditimbulkan oleh semua neuron. Karena tujuan utamanya adalah meminimalkan fungsi biaya, algoritme mundur dan mengubah bobot dan bias yang sesuai. Optimalisasi fungsi biaya dapat dilakukan dengan menggunakan metode gradient descent. Proses ini dikenal sebagai backpropagation.
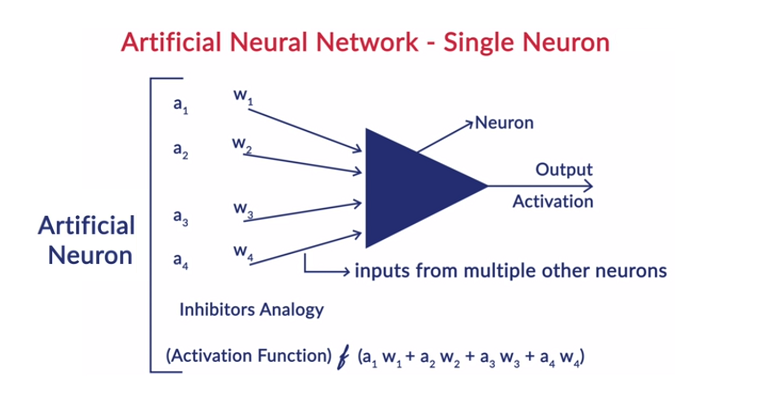
Asumsi di Neural Networks
- Neuron-neuron tersebut tersusun dalam bentuk lapisan-lapisan dan lapisan-lapisan tersebut tersusun secara berurutan.
- Tidak ada komunikasi antara neuron yang berada di dalam lapisan yang sama.
- Titik masuk jaringan syaraf tiruan adalah lapisan input (lapisan pertama) dan titik keluar yang sama adalah lapisan output (lapisan terakhir).
- Setiap interkoneksi dalam jaringan saraf memiliki beberapa bobot yang terkait dengannya dan setiap neuron memiliki bias yang terkait dengannya.
- Fungsi aktivasi yang sama diterapkan pada semua neuron pada lapisan tertentu.
Baca: Ide Proyek Pembelajaran Mendalam
Algoritma Pembelajaran Mendalam yang Berbeda
1. Jaringan Neural Terhubung Sepenuhnya
Dalam Fully Connected Neural Network (FCNNs), setiap neuron dalam satu lapisan terhubung ke setiap neuron lain di lapisan berikutnya. Lapisan ini disebut sebagai lapisan padat untuk alasan yang sama. Lapisan-lapisan ini sangat mahal secara komputasi karena setiap neuron terhubung dengan semua neuron lainnya.
Lebih disukai menggunakan algoritma ini ketika jumlah neuron pada lapisan lebih sedikit, jika tidak maka akan membutuhkan banyak daya komputasi dan waktu untuk melakukan operasi. Ini juga dapat menyebabkan overfitting karena konektivitas penuhnya.
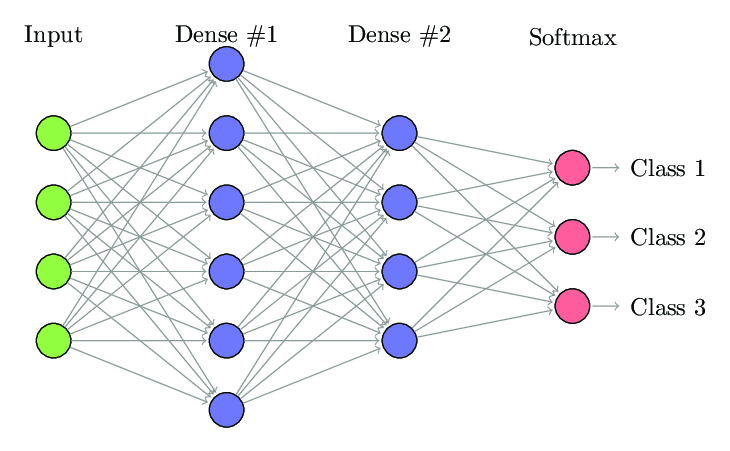
Jaringan Saraf Terhubung Sepenuhnya (Sumber: Researchgate.net)
2. Jaringan Saraf Konvolusi (CNN)
Convolutional Neural Network (CNNs) adalah kelas jaringan saraf yang dirancang untuk bekerja dengan data visual. yaitu gambar dan video. Dengan demikian, ini digunakan untuk banyak tugas pemrosesan gambar seperti Pengenalan Karakter Optik (OCR), Lokalisasi Objek, dll. CNN juga dapat digunakan untuk pengenalan video, teks, dan audio.
Gambar terdiri dari piksel yang menentukan intensitas putihnya gambar. Setiap piksel gambar adalah fitur yang akan diumpankan ke jaringan saraf. Misalnya, gambar 128x128 menunjukkan gambar terdiri dari 16384 piksel atau fitur. Ini akan diumpankan sebagai vektor ukuran 16384 ke jaringan saraf. Untuk gambar berwarna, ada 3 saluran (masing-masing satu – Merah, Biru, Hijau). Dalam hal ini, gambar berwarna yang sama akan dibuat menjadi 128x128x3 piksel.
Ada hierarki di lapisan CNN. Lapisan pertama mencoba mengekstrak fitur mentah dari gambar seperti tepi horizontal atau vertikal. Lapisan kedua mengekstrak lebih banyak wawasan dari fitur yang diekstraksi oleh lapisan pertama. Lapisan berikutnya kemudian akan menyelam lebih dalam ke spesifik untuk mengidentifikasi bagian-bagian tertentu dari suatu gambar seperti rambut, kulit, hidung dll Akhirnya, lapisan terakhir akan mengklasifikasikan gambar input sebagai manusia, kucing, anjing dll.
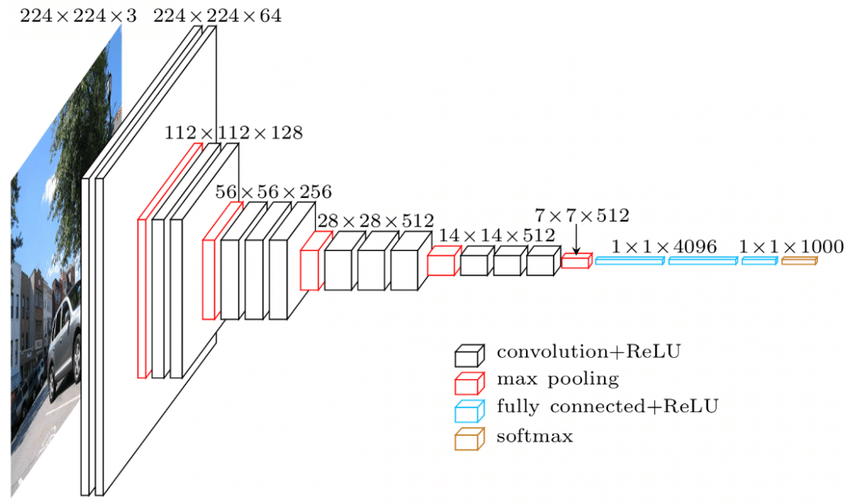
Sumber
Arsitektur VGGNet – Salah satu CNN yang banyak digunakan
Ada tiga terminologi penting dalam CNN:
- Konvolusi - Konvolusi adalah penjumlahan dari produk bijaksana elemen dari dua matriks. Satu matriks merupakan bagian dari input data dan matriks lainnya merupakan filter yang digunakan untuk mengekstrak fitur dari citra.
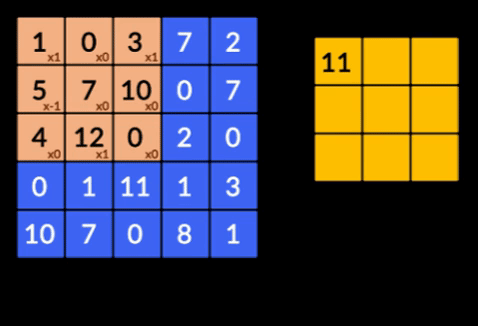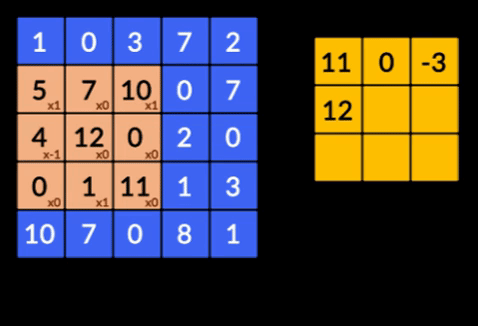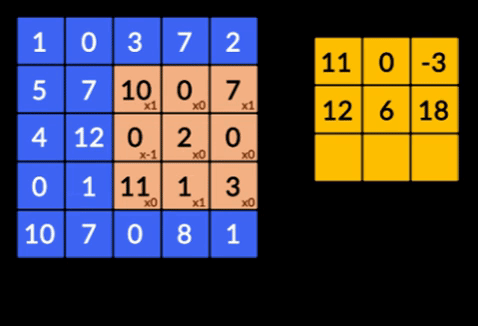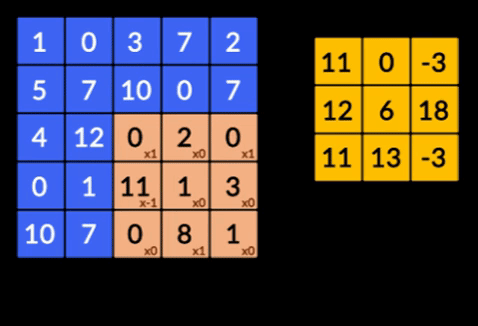
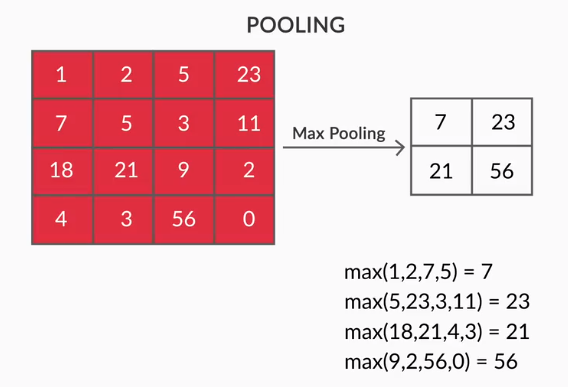
- Pooling Layers – Agregasi fitur yang diekstraksi dilakukan oleh Pooling Layers. Lapisan ini umumnya menghitung statistik agregat (maks, rata-rata dll) dan membuat jaringan tidak berubah terhadap transformasi lokal.
- Feature Maps – Neuron adalah CNN pada dasarnya adalah filter yang bobotnya dipelajari selama pelatihannya. Setiap neuron melihat wilayah tertentu di input yang dikenal sebagai bidang reseptifnya. Sebuah Feature Map adalah kumpulan dari neuron-neuron tersebut yang melihat daerah yang berbeda dari gambar dengan bobot yang sama. Semua neuron dalam peta fitur mencoba mengekstrak fitur yang sama tetapi dari wilayah gambar yang berbeda.
3. Jaringan Saraf Berulang (RNNs)
Jaringan Saraf Berulang dirancang untuk menangani data sekuensial. Data sekuensial adalah data yang memiliki hubungan dengan data sebelumnya seperti teks (urutan kata, kalimat, dll) atau video (urutan gambar), ucapan, dll.

Sangat penting untuk memahami hubungan antara entitas berurutan ini, jika tidak, tidak masuk akal untuk mencampuradukkan seluruh paragraf dan mencoba untuk mendapatkan beberapa makna darinya. RNN dirancang untuk memproses entitas sekuensial ini. Contoh bagus dari RNN yang digunakan adalah pembuatan subtitle otomatis di YouTube. Tidak lain adalah Pengenalan Ucapan Otomatis yang diimplementasikan menggunakan RNN.
Perbedaan utama antara jaringan saraf normal dan jaringan saraf berulang adalah bahwa data input mengalir sepanjang dua dimensi – waktu (sepanjang urutan untuk mengekstrak fitur darinya) dan kedalaman (lapisan saraf normal). Ada berbagai jenis RNN dan strukturnya berubah.
- Banyak ke Satu RNN: – Dalam arsitektur ini, input yang diumpankan ke jaringan adalah urutan dan outputnya adalah satu entitas. Arsitektur ini digunakan dalam mengatasi masalah seperti klasifikasi sentimen atau untuk memprediksi skor sentimen dari data input (masalah regresi). Ini juga dapat digunakan untuk mengklasifikasikan video ke dalam kategori tertentu.
- Banyak ke Banyak RNN: – Keduanya, input dan output adalah urutan dalam arsitektur ini. Ini dapat diklasifikasikan lebih lanjut berdasarkan panjang input dan output.
- Panjang yang sama: – Jaringan menghasilkan output pada setiap langkah waktu. Ada korespondensi satu-ke-satu antara input dan output pada setiap timestep. Arsitektur ini dapat digunakan sebagai part of speech tagger dimana setiap kata dari urutan input ditandai dengan part of speech-nya sebagai output pada setiap timestep.
- Panjang berbeda: – Dalam hal ini, panjang input tidak sama dengan panjang output. Salah satu kegunaan arsitektur ini adalah penerjemahan bahasa. Panjang kalimat dalam bahasa Inggris bisa berbeda dari kalimat bahasa Hindi yang sesuai.
- One to Many RNN: – Input di sini adalah satu entitas sedangkan outputnya adalah urutan. Jenis jaringan saraf ini digunakan untuk tugas-tugas seperti pembuatan musik, gambar, dll.
- One to One RNN: – Ini adalah jaringan saraf tradisional di mana input dan output adalah entitas tunggal.
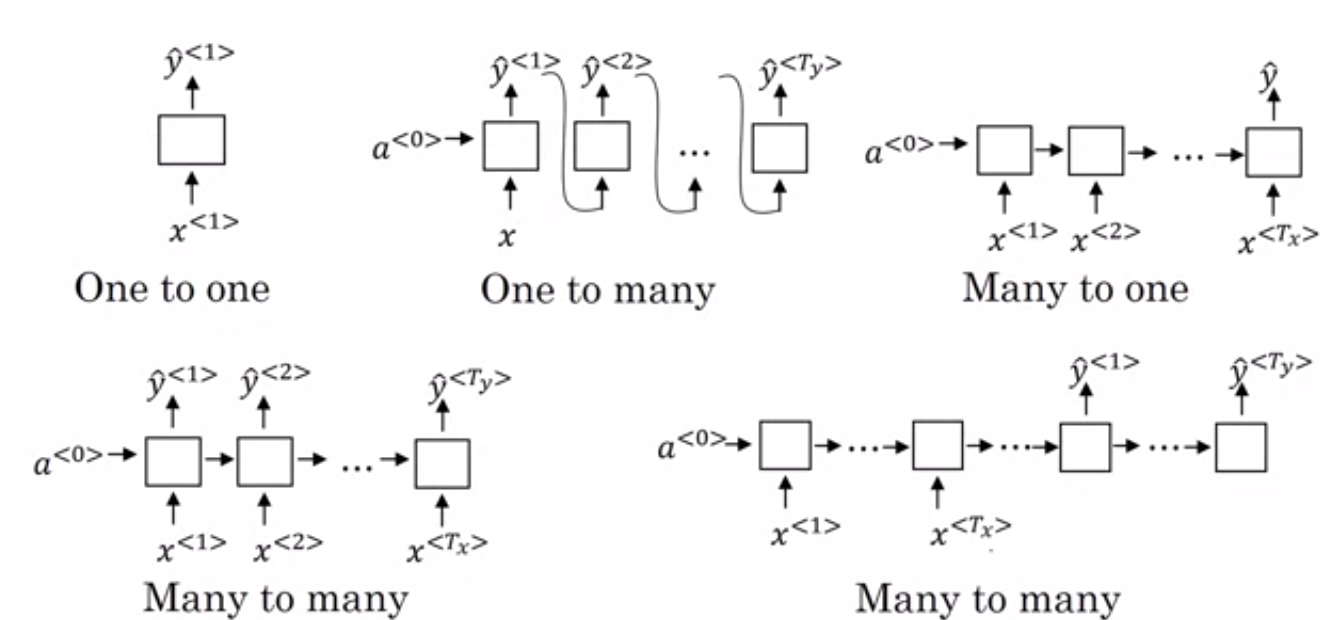
Jenis RNN (Sumber: iq.opengenus.org)
4. Jaringan Memori Jangka Panjang – Pendek (LSTM)
Salah satu kelemahan Recurrent Neural Networks adalah masalah gradien menghilang. Masalah ini ditemui ketika kami melatih jaringan saraf dengan metode pembelajaran berbasis gradien seperti penurunan gradien stokastik dan propagasi balik. Gradien fungsi aktivasi bertanggung jawab untuk memperbarui bobot jaringan.
Mereka menjadi sangat kecil sehingga hampir tidak mempengaruhi bobot jaringan saraf untuk berubah. Ini mencegah jaringan saraf dari pelatihan. RNN menghadapi masalah ini ketika mereka mengalami kesulitan dalam mempelajari ketergantungan jangka panjang.
Long - Short Term Memory Networks (LSTM) dirancang untuk menghadapi masalah ini. LSTM terdiri dari unit memori yang dapat menyimpan informasi yang relevan dengan informasi sebelumnya. Gated Recurrent Units (GRUs) juga merupakan varian dari RNN yang membantu dalam menghilangkan masalah gradien.
Keduanya menggunakan mekanisme gating untuk mengatasi masalah ini. GRU menggunakan lebih sedikit parameter pelatihan dan dengan demikian menggunakan lebih sedikit memori daripada LSTM. Ini memungkinkan GRU untuk berlatih lebih cepat tetapi LSTM memberikan hasil yang lebih akurat di mana urutan inputnya panjang.
5. Jaringan Permusuhan Generatif (GAN)
Generative Adversarial Networks (GAN) adalah algoritma pembelajaran tanpa pengawasan yang secara otomatis menemukan dan mempelajari pola dari data. Setelah mempelajari pola-pola ini, ia menghasilkan data baru sebagai output yang memiliki karakteristik yang sama dengan inputnya. Ini menciptakan model yang dibagi menjadi dua sub model – generator dan diskriminator.
Model generator mencoba menghasilkan gambar baru dari input sedangkan peran model diskriminator adalah untuk mengklasifikasikan apakah data tersebut adalah gambar nyata dari kumpulan data atau dari gambar yang dihasilkan secara artifisial (gambar dari model yang dihasilkan).
Model diskriminator umumnya bertindak sebagai pengklasifikasi biner dalam bentuk jaringan saraf convolutional. Dengan setiap iterasi, kedua model mencoba meningkatkan hasilnya karena tujuan model generator adalah untuk mengelabui model diskriminator dalam mengidentifikasi gambar dan tujuan diskriminator adalah mengidentifikasi gambar palsu dengan benar.
6. Mesin Boltzmann Terbatas (RBM)
Restricted Boltzmann Machine (RBM) adalah jaringan saraf non-deterministik dengan kemampuan generatif dan mempelajari distribusi probabilitas melalui input. Mereka adalah bentuk terbatas dari Boltzmann Machine, dibatasi dalam hal interkoneksi antara node di lapisan.
Ini melibatkan hanya dua lapisan yaitu lapisan terlihat dan lapisan tersembunyi. Tidak ada lapisan keluaran di RBM dan lapisan-lapisan tersebut sepenuhnya terhubung satu sama lain. RBM sekarang benar-benar digunakan karena telah digantikan oleh GAN. Beberapa RBM juga dapat disatukan untuk membuat jaringan baru yang dapat disetel menggunakan penurunan gradien dan propagasi balik seperti jaringan saraf lainnya. Jaringan seperti ini disebut sebagai Deep Belief Networks.
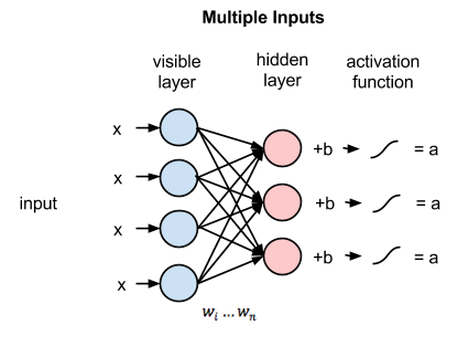
Mesin Boltzmann Terbatas (Sumber: Medium)
7. Transformer
Transformer adalah jenis arsitektur jaringan saraf yang dirancang untuk terjemahan mesin saraf. Mereka melibatkan mekanisme perhatian yang berfokus pada bagian dari informasi yang diberikan ke jaringan. Ini melibatkan dua bagian: Encoder dan Decoder.
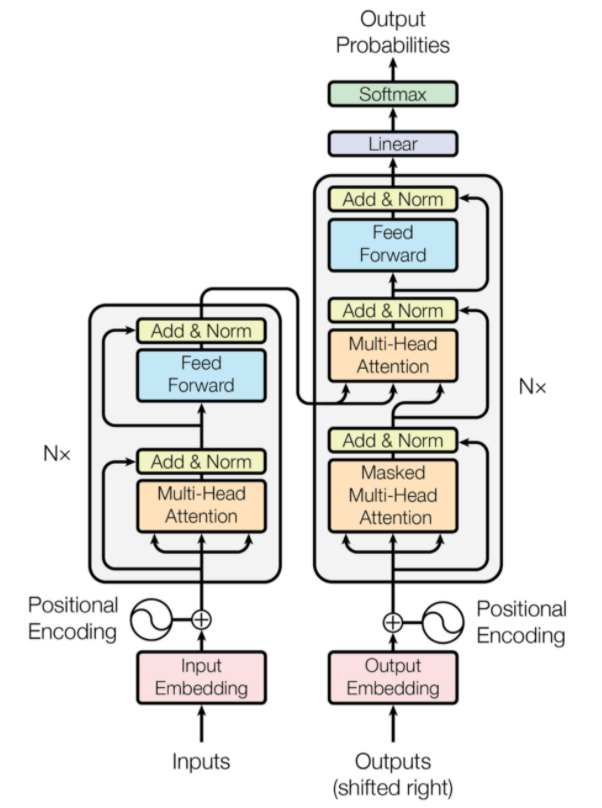
Arsitektur Transformer (Sumber: arxiv.org)
Bagian kiri gambar adalah Encoder, dan bagian kanan adalah Decoder. Encoder dan decoder dapat terdiri dari beberapa modul yang dapat ditumpuk di atas satu sama lain. Hal yang sama disampaikan oleh Nx pada gambar. Fungsi dari setiap lapisan encoder adalah untuk mengetahui bagian mana dari input yang relevan satu sama lain yang disebut sebagai encoding.
Pengkodean ini kemudian diteruskan ke lapisan encoder berikutnya sebagai input. Lapisan dekoder mengambil pengkodean ini dan memprosesnya untuk menghasilkan urutan keluaran. Mekanisme penuh perhatian menimbang signifikansi setiap input lainnya dan mengekstrak informasi dari hubungan ini untuk memprediksi urutan output. Lapisan encoder dan decoder juga terdiri dari lapisan feed forward yang digunakan untuk pemrosesan lebih lanjut dari output.
Baca Juga: Deep Learning vs Neural Networks
Kesimpulan
Artikel tersebut memberikan pengenalan singkat ke domain Deep Learning, komponen yang digunakan dalam jaringan saraf, ide algoritma pembelajaran mendalam, asumsi yang dibuat untuk menyederhanakan jaringan saraf, dll. Artikel ini memberikan daftar terbatas algoritma pembelajaran mendalam karena ada banyak algoritma yang berbeda yang terus-menerus diciptakan untuk mengatasi keterbatasan algoritma yang ada.
Algoritma Deep Learning telah merevolusi cara pemrosesan video, gambar, teks, dll. Dan mereka dapat dengan mudah diimplementasikan dengan mengimpor paket yang diperlukan. Terakhir, untuk semua Deep Learners, Infinity adalah batasnya.
Jika Anda tertarik untuk mempelajari lebih lanjut tentang teknik pembelajaran mendalam , pembelajaran mesin, lihat Sertifikasi PG IIIT-B & upGrad dalam Pembelajaran Mesin & Pembelajaran Mendalam yang dirancang untuk profesional yang bekerja dan menawarkan 240+ jam pelatihan ketat, 5+ studi kasus & penugasan, status Alumni IIIT-B & bantuan pekerjaan dengan perusahaan papan atas.
Perbedaan antara CNN dan ANN?
Jaringan Syaraf Tiruan (JST) membangun lapisan jaringan sejajar dengan lapisan saraf manusia: lapisan keputusan input, tersembunyi, dan output. JST peka terhadap kesalahan dan memperbarui diri dengan merestrukturisasi diri mereka sendiri setelah kekurangan. Convolutional Neural Networks (CNNs) terutama berfokus pada input gambar. Di CNN, lapisan pertama mengekstrak gambar mentah. Lapisan berikutnya mengintip ke dalam informasi yang ditemukan di lapisan sebelumnya. Lapisan ketiga mengidentifikasi fitur gambar, dan lapisan terakhir mengenali gambar. CNN tidak memerlukan deskripsi input eksplisit; Mereka mengenali data menggunakan fitur spasial. Mereka sangat disukai untuk tugas pengenalan visual.
Apakah Deep Learning memberikan keunggulan dalam Kecerdasan Buatan?
Artificial Intelligence (AI) telah membuat teknologi lebih akurat dan mewakili dunia. Sebagai bagian dari Machine Learning di AI, Deep Learning dapat memproses data dalam jumlah besar secara efisien. Ini memiliki pendekatan titik ke titik untuk memecahkan masalah. Deep Learning telah menciptakan sistem yang efisien dan cepat, sementara sistem Machine Learning memiliki beberapa langkah untuk memulai. Meskipun Deep Learning membutuhkan banyak waktu pelatihan, timbal balik pengujiannya terjadi seketika. Deep Learning tidak dapat disangkal merupakan bagian integral dari Kecerdasan Buatan dan telah berkontribusi untuk mendeteksi data pendengaran dan visual. Itu telah memungkinkan perangkat asisten suara otomatis, kendaraan, dan banyak teknologi lainnya.
Apa keterbatasan Deep Learning?
Deep Learning telah membuat kemajuan dalam interaksi mesin-manusia dan membuat teknologi berguna bagi umat manusia dalam banyak hal. Ini memiliki rintangan pelatihan ekstensif, persyaratan peralatan yang mahal, dan prasyarat data yang besar. Ini memberikan solusi otomatis, tetapi membuat keputusan yang tidak jelas sampai perhitungan banyak algoritma dan jaringan saraf dilakukan. Jalur ditelusuri kembali ke node tertentu, yang hampir tidak mungkin; Pembelajaran Mesin memiliki jalur proses pelacakan yang lurus dan lebih disukai. Deep Learning memang memiliki banyak keterbatasan, tetapi kelebihannya melebihi semuanya.