
Algorithme d'apprentissage en profondeur [Guide complet avec exemples]
Publié: 2020-10-28Table des matières
introduction
L'apprentissage en profondeur est un sous-ensemble de l'apprentissage automatique, qui implique des algorithmes inspirés de l'arrangement et du fonctionnement du cerveau. Alors que les neurones du cerveau humain transmettent des informations et aident à apprendre à partir des réacteurs de notre corps, les algorithmes d'apprentissage en profondeur traversent également différentes couches d'algorithmes de réseaux de neurones et apprennent de leurs réactions.
En d'autres termes, l'apprentissage en profondeur utilise des couches d'algorithmes de réseau neuronal pour découvrir des données de niveau plus significatif dépendant des données d'entrée brutes. Les algorithmes du réseau neuronal découvrent les modèles de données grâce à un processus qui simule en quelque sorte le fonctionnement d'un cerveau humain.
Les réseaux de neurones aident à regrouper les points de données à partir d'un grand ensemble de points de données en fonction des similitudes des caractéristiques. Ces systèmes sont connus sous le nom de réseaux de neurones artificiels.
Au fur et à mesure que de plus en plus de données alimentaient les modèles, les algorithmes d'apprentissage en profondeur se sont révélés plus productifs et ont fourni de meilleurs résultats que les autres algorithmes. Les algorithmes d'apprentissage en profondeur sont utilisés pour divers problèmes tels que la reconnaissance d'images, la reconnaissance vocale, la détection de fraude, la vision par ordinateur, etc.
Composants du réseau neuronal
1. Topologie du réseau - La topologie du réseau fait référence à la structure du réseau neuronal. Il comprend le nombre de couches cachées dans le réseau, le nombre de neurones dans chaque couche, y compris la couche d'entrée et de sortie, etc.
2. Couche d' entrée - La couche d'entrée est le point d'entrée du réseau neuronal. Le nombre de neurones dans la couche d'entrée doit être égal au nombre d'attributs dans les données d'entrée.

3. Couche de sortie - La couche de sortie est le point de sortie du réseau neuronal. Le nombre de neurones dans la couche de sortie doit être égal au nombre de classes dans la variable cible (pour le problème de classification). Pour le problème de régression, le nombre de neurones dans la couche de sortie sera de 1 car la sortie serait une variable numérique.
4. Fonctions d'activation - Les fonctions d'activation sont des équations mathématiques qui s'appliquent à la somme des entrées pondérées d'un neurone. Cela aide à déterminer si le neurone doit être déclenché ou non. Il existe de nombreuses fonctions d'activation telles que la fonction sigmoïde, l'unité linéaire rectifiée (ReLU), le Leaky ReLU, la tangente hyperbolique, la fonction Softmax, etc.
5. Poids - Chaque interconnexion entre les neurones des couches consécutives est associée à un poids. Il indique l'importance de la connexion entre les neurones dans la découverte d'un modèle de données qui aide à prédire le résultat du réseau neuronal. Plus les valeurs de poids sont élevées, plus la signification est élevée. C'est un des paramètres que le réseau apprend lors de sa phase d'apprentissage.
6. Biais - Le biais aide à déplacer la fonction d'activation vers la gauche ou la droite, ce qui peut être essentiel pour une meilleure prise de décision. Son rôle est analogue au rôle d'une interception dans l'équation linéaire. Les poids peuvent augmenter la pente de la fonction d'activation, c'est-à-dire qu'ils indiquent à quelle vitesse la fonction d'activation se déclenchera, tandis que le biais est utilisé pour retarder le déclenchement de la fonction d'activation. C'est le second paramètre que le réseau apprend lors de sa phase d'apprentissage.
Article connexe : Meilleures techniques d'apprentissage en profondeur
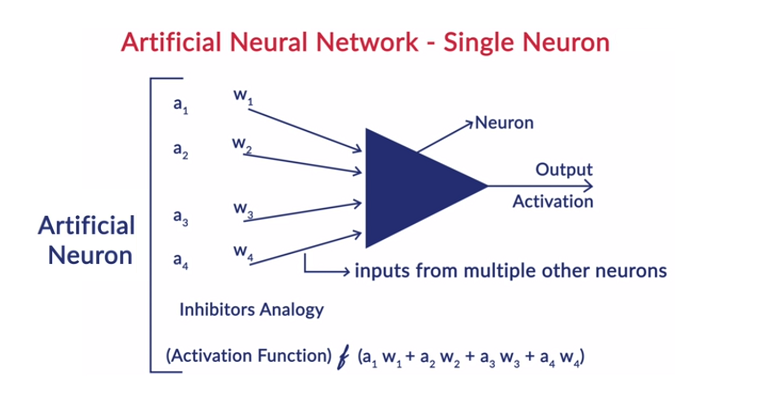
Fonctionnement général d'un neurone
L'apprentissage en profondeur fonctionne avec les réseaux de neurones artificiels (ANN) pour imiter le fonctionnement du cerveau humain et apprendre d'une manière humaine. Les neurones des réseaux de neurones artificiels sont disposés en couches. La première et la dernière couche sont appelées couches d'entrée et de sortie. Les couches entre ces deux couches sont appelées couches cachées.
Chaque neurone de la couche est constitué de son propre biais et un poids est associé à chaque interconnexion entre les neurones de la couche précédente à la couche suivante. Chaque entrée est multipliée par le poids associé à l'interconnexion.
La somme pondérée des entrées est calculée pour chacun des neurones dans les couches. Une fonction d'activation est appliquée à cette somme pondérée d'entrée et ajoutée avec le biais du neurone pour produire la sortie du neurone. Cette sortie sert d'entrée aux connexions de ce neurone dans la couche suivante et ainsi de suite.
Ce processus est appelé feedforwarding. Le résultat de la couche de sortie sert de décision finale prise par le modèle. L'entraînement des réseaux de neurones se fait sur la base du poids de chaque interconnexion entre les neurones et du biais de chaque neurone. Une fois que le résultat final a été prédit par le modèle, il calcule la perte totale qui est fonction des pondérations et des biais.
La perte totale est essentiellement la somme des pertes subies par tous les neurones. Comme le but ultime est de minimiser la fonction de coût, l'algorithme revient en arrière et modifie les poids et les biais en conséquence. L'optimisation de la fonction de coût peut être effectuée en utilisant la méthode de descente de gradient. Ce processus est connu sous le nom de rétropropagation.
Hypothèses dans les réseaux de neurones
- Les neurones sont disposés sous forme de couches et ces couches sont disposées de manière séquentielle.
- Il n'y a pas de communication entre les neurones qui se trouvent dans la même couche.
- Le point d'entrée des réseaux de neurones est la couche d'entrée (première couche) et le point de sortie de ceux-ci est la couche de sortie (dernière couche).
- Chaque interconnexion dans le réseau neuronal a un certain poids qui lui est associé et chaque neurone a un biais qui lui est associé.
- La même fonction d'activation est appliquée à tous les neurones d'une certaine couche.
Lire : Idées de projets d'apprentissage en profondeur
Différents algorithmes d'apprentissage en profondeur
1. Réseau neuronal entièrement connecté
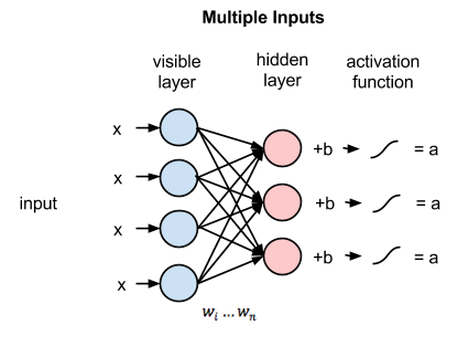
Dans les réseaux de neurones entièrement connectés (FCNN), chaque neurone d'une couche est connecté à tous les autres neurones de la couche suivante. Ces couches sont appelées couches denses pour la même raison. Ces couches sont très coûteuses en calcul car chaque neurone se connecte à tous les autres neurones.
Il est préférable d'utiliser cet algorithme lorsque le nombre de neurones dans les couches est inférieur, sinon cela nécessiterait beaucoup de puissance de calcul et de temps pour effectuer les opérations. Cela peut également entraîner un surajustement en raison de sa connectivité complète.
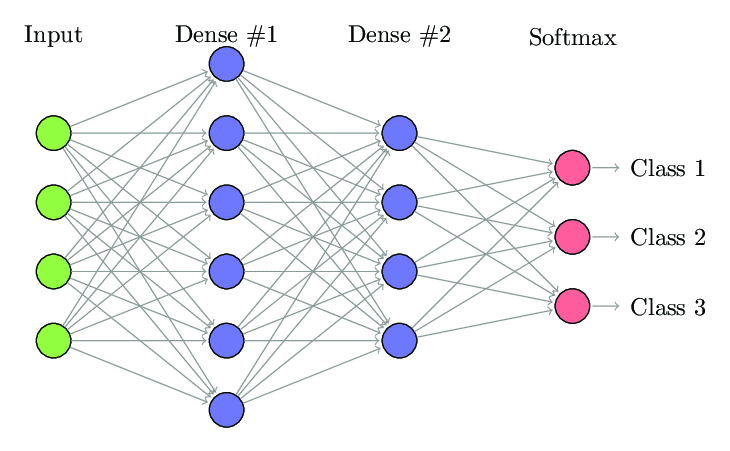
Réseau neuronal entièrement connecté (Source : Researchgate.net)
2. Réseau de neurones convolutionnels (CNN)
Les réseaux neuronaux convolutifs (CNN) sont une classe de réseaux neuronaux conçus pour fonctionner avec les données visuelles. c'est-à-dire des images et des vidéos. Ainsi, il est utilisé pour de nombreuses tâches de traitement d'images telles que la reconnaissance optique de caractères (OCR), la localisation d'objets, etc. Les CNN peuvent également être utilisés pour la reconnaissance vidéo, textuelle et audio.
Les images sont composées de pixels qui déterminent l'intensité de la blancheur de l'image. Chaque pixel d'une image est une caractéristique qui sera transmise au réseau de neurones. Par exemple, une image 128×128 indique que l'image est composée de 16384 pixels ou caractéristiques. Il sera envoyé sous forme de vecteur de taille 16384 au réseau de neurones. Pour les images couleur, il y a 3 canaux (un pour chacun – Rouge, Bleu, Vert). Dans ce cas, la même image en couleur serait constituée de 128x128x3 pixels.
Il y a une hiérarchie dans les couches du CNN. La première couche essaie d'extraire les caractéristiques brutes des images comme les bords horizontaux ou verticaux. Les deuxièmes couches extraient plus d'informations des fonctionnalités extraites par la première couche. Les couches suivantes plongeraient alors plus profondément dans les détails pour identifier certaines parties d'une image telles que les cheveux, la peau, le nez, etc. Enfin, la dernière couche classerait l'image d'entrée comme humain, chat, chien, etc.
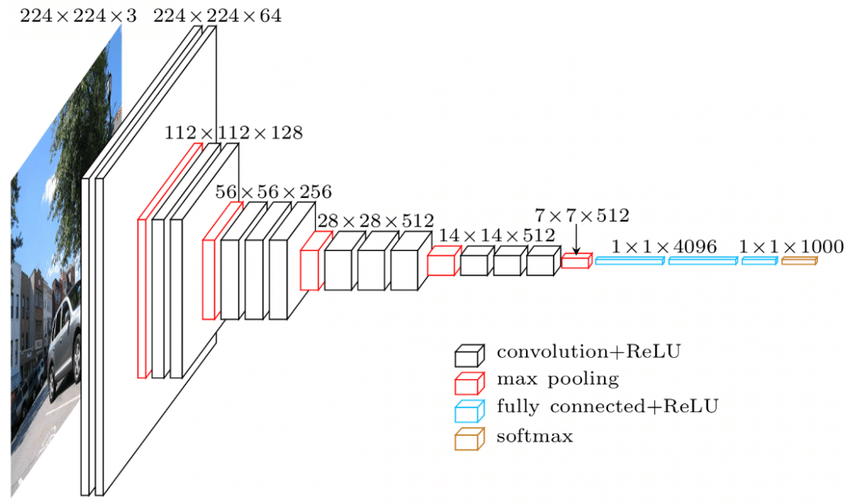
La source
Architecture VGGNet - L'un des CNN les plus utilisés
Il existe trois terminologies importantes dans les CNN :
- Convolutions - Les convolutions sont la somme du produit par élément des deux matrices. Une matrice fait partie des données d'entrée et l'autre matrice est un filtre utilisé pour extraire les caractéristiques de l'image.
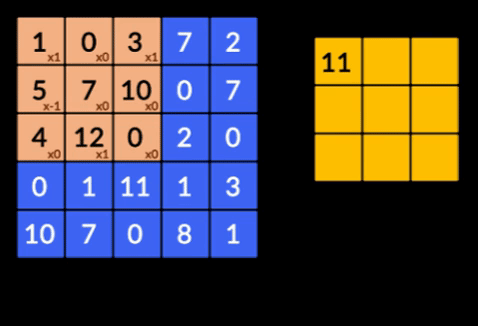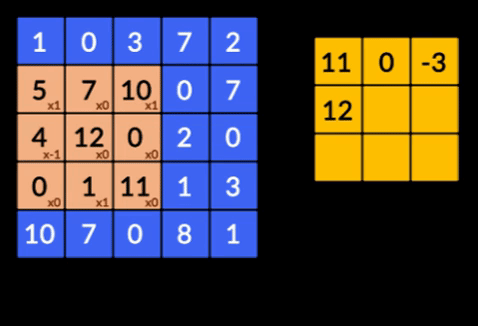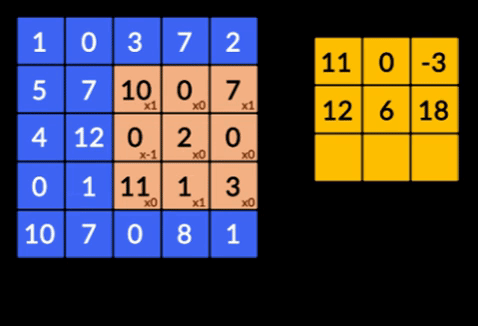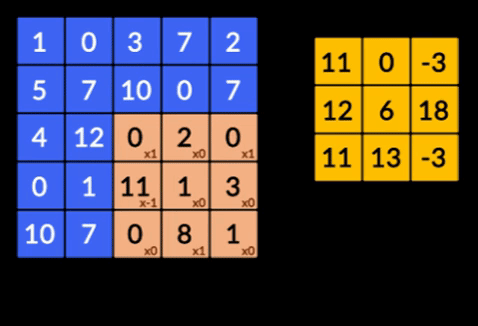
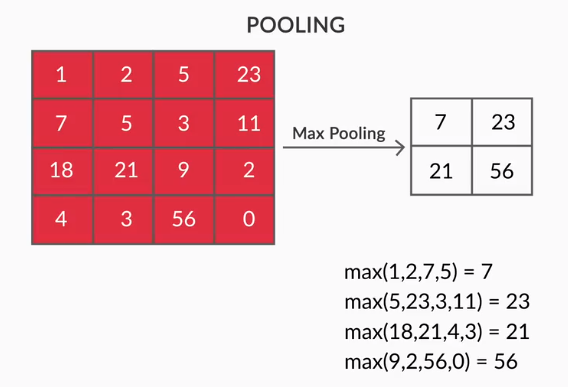
- Pooling Layers - L'agrégation des entités extraites est effectuée par Pooling Layers. Ces couches calculent généralement une statistique agrégée (max, moyenne, etc.) et rendent le réseau invariant aux transformations locales.
- Cartes de caractéristiques - Un neurone est CNN est essentiellement un filtre dont les poids sont appris au cours de sa formation. Chaque neurone regarde une région particulière dans l'entrée qui est connue comme son champ récepteur. Une carte de caractéristiques est une collection de tels neurones qui regardent différentes régions de l'image avec les mêmes poids. Tous les neurones d'une carte de caractéristiques tentent d'extraire la même caractéristique mais à partir de différentes régions de l'image.
3. Réseaux de neurones récurrents (RNN)
Les réseaux de neurones récurrents sont conçus pour traiter des données séquentielles. Les données séquentielles désignent les données qui ont un lien avec les données précédentes telles que le texte (séquence de mots, phrases, etc.) ou les vidéos (séquence d'images), la parole, etc.

Il est très important de comprendre le lien entre ces entités séquentielles, sinon cela n'aurait aucun sens de mélanger tout le paragraphe et d'essayer d'en tirer un sens. Les RNN ont été conçus pour traiter ces entités séquentielles. Un bon exemple d'utilisation des RNN est la génération automatique de sous-titres sur YouTube. Ce n'est rien d'autre que la reconnaissance automatique de la parole mise en œuvre à l'aide de RNN.
La principale différence entre les réseaux de neurones normaux et les réseaux de neurones récurrents est que les données d'entrée circulent selon deux dimensions : le temps (le long de la séquence pour en extraire des caractéristiques) et la profondeur (couches de neurones normales). Il existe différents types de RNN et leur structure change en conséquence.
- Plusieurs vers un RNN : – Dans cette architecture, l'entrée envoyée au réseau est une séquence et la sortie est une entité unique. Cette architecture est utilisée pour résoudre des problèmes tels que la classification des sentiments ou pour prédire le score de sentiment des données d'entrée (problème de régression). Il peut également être utilisé pour classer les vidéos dans certaines catégories.
- Plusieurs à plusieurs RNN : – L'entrée et la sortie sont toutes deux des séquences dans cette architecture. Il peut être encore classé sur la base de la longueur de l'entrée et de la sortie.
- Même longueur : – Le réseau produit une sortie à chaque pas de temps. Il existe une correspondance un à un entre l'entrée et la sortie à chaque pas de temps. Cette architecture peut être utilisée comme une partie de l'étiqueteur de parole où chaque mot de la séquence dans l'entrée est étiqueté avec sa partie de la parole en sortie à chaque pas de temps.
- Longueur différente : – Dans ce cas, la longueur de l'entrée n'est pas égale à la longueur de la sortie. L'une des utilisations de cette architecture est la traduction de langue. La longueur d'une phrase en anglais peut être différente de la phrase correspondante en hindi.
- Un à plusieurs RNN : - L'entrée ici est une entité unique alors que la sortie est une séquence. Ces types de réseaux de neurones sont utilisés pour des tâches telles que la génération de musique, d'images, etc.
- One to One RNN : - Il s'agit d'un réseau de neurones traditionnel dans lequel l'entrée et la sortie sont des entités uniques.
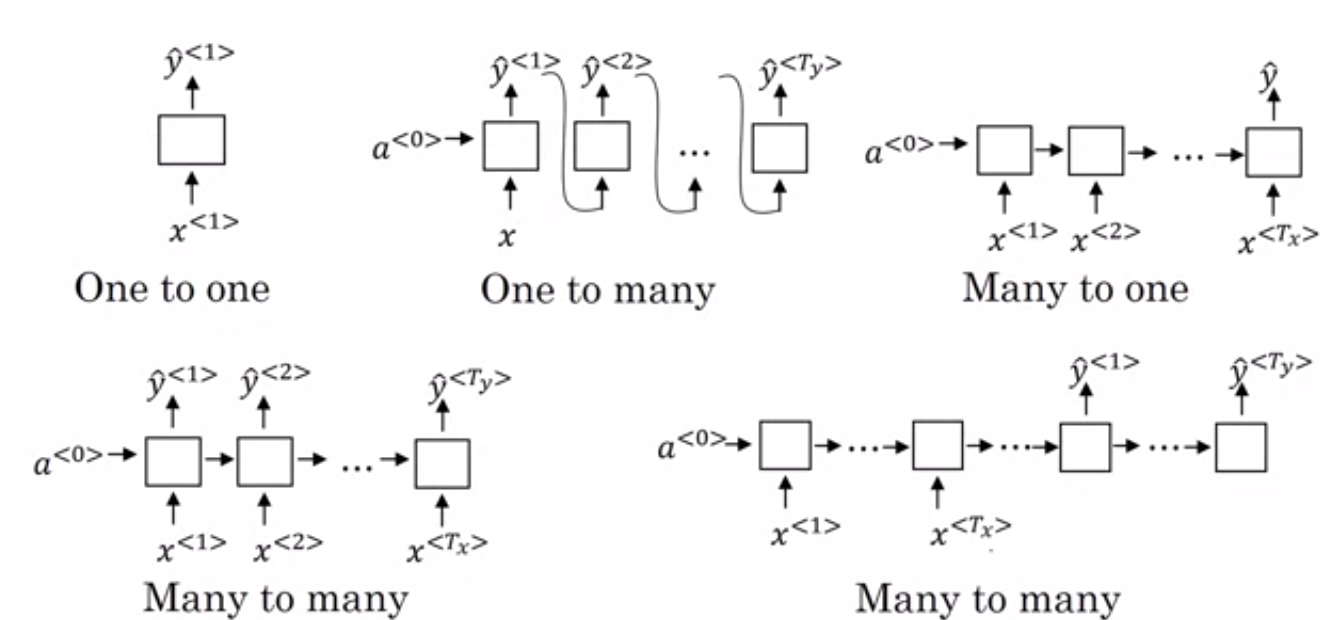
Types de RNN (Source : iq.opengenus.org)
4. Réseaux de mémoire à long et à court terme (LSTM)
L'un des inconvénients des réseaux de neurones récurrents est le problème du gradient de disparition. Ce problème est rencontré lorsque nous entraînons des réseaux de neurones avec des méthodes d'apprentissage basées sur les gradients comme la descente de gradient stochastique et la rétropropagation. Les gradients de la fonction d'activation sont responsables de la mise à jour des poids des réseaux.
Ils deviennent si petits que cela n'affecte guère les poids des réseaux de neurones à changer. Cela empêche les réseaux de neurones de s'entraîner. Les RNN sont confrontés à ce problème lorsqu'ils ont des difficultés à apprendre les dépendances à long terme.
Les réseaux de mémoire à long et à court terme (LSTM) ont été conçus pour résoudre ce problème. LSTM consiste en une unité de mémoire qui peut stocker les informations pertinentes par rapport aux informations précédentes. Les unités récurrentes fermées (GRU) sont également une variante des RNN qui aident à résoudre les problèmes de gradient de fuite.
Les deux utilisent un mécanisme de déclenchement pour résoudre ce problème. GRU utilise moins de paramètres de formation et utilise donc moins de mémoire que LSTM. Cela permet aux GRU de s'entraîner plus rapidement, mais LSTM fournit des résultats plus précis lorsque les séquences d'entrée sont longues.
5. Réseaux antagonistes génératifs (GAN)
Les réseaux antagonistes génératifs (GAN) sont un algorithme d'apprentissage non supervisé qui découvre et apprend automatiquement les modèles à partir des données. Après avoir appris ces modèles, il génère de nouvelles données en sortie qui ont les mêmes caractéristiques que l'entrée. Il crée un modèle qui est divisé en deux sous-modèles - générateur et discriminateur.
Le modèle générateur essaie de générer de nouvelles images à partir de l'entrée tandis que le rôle du modèle discriminateur est de classer si les données sont une image réelle de l'ensemble de données ou des images générées artificiellement (images du modèle généré).
Le modèle de discriminateur agit généralement comme un classificateur binaire sous forme de réseau de neurones convolutif. À chaque itération, les deux modèles tentent d'améliorer leurs résultats car l'objectif du modèle générateur est de tromper le modèle discriminateur dans l'identification de l'image et l'objectif du discriminateur est d'identifier correctement les fausses images.
6. Machine Boltzmann restreinte (RBM)
Les machines de Boltzmann restreintes (RBM) sont des réseaux de neurones non déterministes dotés de capacités génératives et apprennent la distribution de probabilité sur l'entrée. Ils sont une forme restreinte de Boltzmann Machine, restreinte en termes d'interconnexions entre les nœuds de la couche.
Celles-ci n'impliquent que deux couches, à savoir la couche visible et la couche cachée. Il n'y a pas de couche de sortie dans le RBM et les couches sont entièrement connectées les unes aux autres. Les RBM sont maintenant solennellement utilisés puisqu'ils ont été remplacés par les GAN. Plusieurs RBM peuvent également être assemblés pour créer un nouveau réseau qui peut être réglé en utilisant la descente de gradient et la rétropropagation comme les autres réseaux de neurones. Ces réseaux sont appelés Deep Belief Networks.
Machine Boltzmann restreinte (Source : Medium)
7. Transformateurs
Les transformateurs sont un type d'architecture de réseau neuronal conçu pour la traduction automatique neuronale. Ils impliquent un mécanisme d'attention qui se concentre sur une partie des informations fournies au réseau. Il comprend deux parties : les encodeurs et les décodeurs.
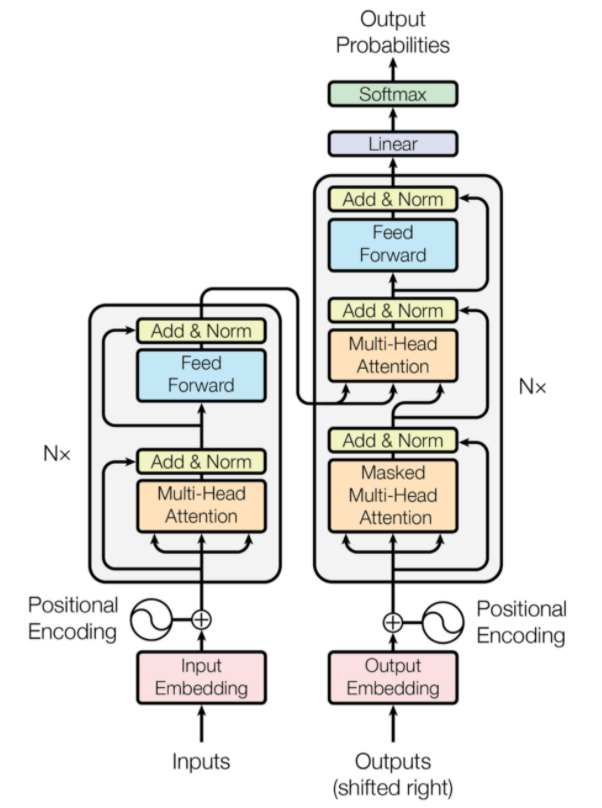
Architecture de transformateur (Source : arxiv.org)
La partie gauche de la figure est l'encodeur et la partie droite est le décodeur. L'encodeur et le décodeur peuvent être constitués de plusieurs modules qui peuvent être empilés les uns sur les autres. La même chose est véhiculée par Nx sur la figure. La fonction de chaque couche d'encodeur est de déterminer quelles parties de l'entrée sont pertinentes les unes pour les autres et sont appelées codages.
Ces codages sont ensuite transmis à la couche de codeur suivante en tant qu'entrées. La couche décodeur prend ces codages et les traite pour générer la séquence de sortie. Le mécanisme attentif évalue la signification de chaque autre entrée et extrait des informations de ces relations pour prédire la séquence de sortie. Les couches d'encodeur et de décodeur consistent également en des couches d'anticipation qui sont utilisées pour le traitement ultérieur des sorties.
Lisez aussi : Apprentissage en profondeur vs réseaux de neurones
Conclusion
L'article a donné une brève introduction au domaine de l'apprentissage en profondeur, les composants utilisés dans les réseaux de neurones, l'idée d'algorithmes d'apprentissage en profondeur, les hypothèses faites pour simplifier les réseaux de neurones, etc. Cet article fournit une liste restreinte d'algorithmes d'apprentissage en profondeur car il existe de nombreux algorithmes différents qui sont constamment créés pour surmonter les limites des algorithmes existants.
Les algorithmes d'apprentissage en profondeur ont révolutionné la façon de traiter les vidéos, les images, le texte, etc. et ils peuvent être facilement mis en œuvre en important les packages requis. Enfin, pour tous les Deep Learners, Infinity est la limite.
Si vous souhaitez en savoir plus sur les techniques d'apprentissage en profondeur , l'apprentissage automatique, consultez la certification PG d'IIIT-B et upGrad en apprentissage automatique et en apprentissage en profondeur, conçue pour les professionnels en activité et offrant plus de 240 heures de formation rigoureuse, plus de 5 études de cas. & affectations, statut IIIT-B Alumni & aide à l'emploi avec les meilleures entreprises.
Différence entre CNN et ANN ?
Les réseaux de neurones artificiels (ANN) construisent des couches de réseau parallèles aux couches de neurones humains : couches de décision d'entrée, cachées et de sortie. Les ANN perçoivent les failles et se mettent à jour en se restructurant après une lacune. Les réseaux de neurones convolutifs (CNN) sont principalement axés sur l'entrée d'images. Dans les CNN, la première couche extrait l'image brute. La couche suivante scrute les informations trouvées dans la couche précédente. La troisième couche identifie les caractéristiques de l'image et la dernière couche reconnaît l'image. Les CNN ne nécessitent pas de descriptions d'entrée explicites ; Ils reconnaissent les données à l'aide de caractéristiques spatiales. Ils sont hautement préférés pour les tâches de reconnaissance visuelle.
L'apprentissage en profondeur offre-t-il un avantage en matière d'intelligence artificielle ?
L'intelligence artificielle (IA) a rendu la technologie plus précise et représentative du monde. Dans le cadre du Machine Learning dans l'IA, le Deep Learning peut traiter efficacement de grandes quantités de données. Il a une approche point à point pour résoudre les problèmes. Deep Learning a créé des systèmes efficaces et rapides, tandis que les systèmes d'apprentissage automatique ont plusieurs étapes pour démarrer. Bien que le Deep Learning nécessite beaucoup de temps de formation, sa réciprocité de test est instantanée. Le Deep Learning fait indéniablement partie intégrante de l'Intelligence Artificielle et a contribué à la détection de données auditives et visuelles. Il a rendu possibles les assistants vocaux automatisés, les véhicules et de nombreuses autres technologies.
Quelles sont les limites du Deep Learning ?
L'apprentissage en profondeur a fait des progrès dans l'interaction homme-machine et a rendu la technologie utile à l'humanité à bien des égards. Il a des obstacles de formation approfondie, des exigences d'équipement coûteuses et des prérequis de données volumineux. Il fournit des solutions automatisées, mais il prend des décisions qui ne sont pas claires tant que le calcul de nombreux algorithmes et réseaux de neurones n'est pas effectué. La voie est tracée jusqu'aux nœuds spécifiques, ce qui est presque impossible ; L'apprentissage automatique a un chemin droit de suivi des processus et est préférable. Le Deep Learning a de nombreuses limites, mais ses avantages l'emportent sur tous.