
Algorytm Deep Learning [Kompleksowy przewodnik z przykładami]
Opublikowany: 2020-10-28Spis treści
Wstęp
Głębokie uczenie to podzbiór uczenia maszynowego, który obejmuje algorytmy inspirowane układem i funkcjonowaniem mózgu. Ponieważ neurony z ludzkiego mózgu przekazują informacje i pomagają w uczeniu się z reaktorów w naszym ciele, podobnie algorytmy głębokiego uczenia przechodzą przez różne warstwy algorytmów sieci neuronowych i uczą się na podstawie ich reakcji.
Innymi słowy, uczenie głębokie wykorzystuje warstwy algorytmów sieci neuronowej do wykrywania bardziej istotnych danych poziomu zależnych od surowych danych wejściowych. Algorytmy sieci neuronowych odkrywają wzorce danych w procesie symulującym działanie ludzkiego mózgu.
Sieci neuronowe pomagają w grupowaniu punktów danych z dużego zestawu punktów danych w oparciu o podobieństwa cech. Systemy te znane są jako sztuczne sieci neuronowe.
Ponieważ do modeli wprowadzano coraz więcej danych, algorytmy uczenia głębokiego okazały się bardziej wydajne i zapewniały lepsze wyniki niż reszta algorytmów. Algorytmy Deep Learning są używane do różnych problemów, takich jak rozpoznawanie obrazu, rozpoznawanie mowy, wykrywanie oszustw, wizja komputerowa itp.
Składniki sieci neuronowej
1. Topologia sieci – Topologia sieci odnosi się do struktury sieci neuronowej. Obejmuje liczbę ukrytych warstw w sieci, liczbę neuronów w każdej warstwie, w tym warstwę wejściową i wyjściową itp.
2. Warstwa wejściowa – Warstwa wejściowa jest punktem wejścia do sieci neuronowej. Liczba neuronów w warstwie wejściowej powinna być równa liczbie atrybutów w danych wejściowych.

3. Warstwa wyjściowa – Warstwa wyjściowa jest punktem wyjścia z sieci neuronowej. Liczba neuronów w warstwie wyjściowej powinna być równa liczbie klas w zmiennej docelowej (dla problemu klasyfikacji). W przypadku problemu regresji liczba neuronów w warstwie wyjściowej będzie wynosić 1, ponieważ wynik będzie zmienną numeryczną.
4. Funkcje aktywacji – Funkcje aktywacji to matematyczne równania, które odnoszą się do sumy ważonych wejść neuronu. Pomaga w określeniu, czy neuron powinien zostać wyzwolony, czy nie. Istnieje wiele funkcji aktywacji, takich jak funkcja sigmoid, Rectified Linear Unit (ReLU), Leaky ReLU, Hyperbolic Tangent, funkcja Softmax itp.
5. Wagi – Każde połączenie między neuronami w kolejnych warstwach ma przypisaną wagę. Wskazuje na znaczenie połączenia między neuronami w odkrywaniu pewnego wzorca danych, który pomaga w przewidywaniu wyniku sieci neuronowej. Im wyższe wartości wag, tym większe znaczenie. Jest to jeden z parametrów, których sieć uczy się w fazie szkolenia.
6. Biases – Bias pomaga w przesunięciu funkcji aktywacji w lewo lub w prawo, co może mieć kluczowe znaczenie dla lepszego podejmowania decyzji. Jego rola jest analogiczna do roli wyrazu wolnego w równaniu liniowym. Wagi mogą zwiększać stromość funkcji aktywacji, tj. wskazują, jak szybko funkcja aktywacji zostanie uruchomiona, podczas gdy odchylenie służy do opóźnienia uruchomienia funkcji aktywacji. Jest to drugi parametr, którego sieć uczy się w fazie uczenia.
Powiązany artykuł: Najlepsze techniki głębokiego uczenia
Ogólna praca neuronu
Głębokie uczenie współpracuje ze sztucznymi sieciami neuronowymi (ANN), aby naśladować pracę ludzkiego mózgu i uczyć się w sposób, w jaki robi to człowiek. Neurony w sztucznych sieciach neuronowych są ułożone warstwami. Pierwsza i ostatnia warstwa to warstwy wejściowe i wyjściowe. Warstwy pomiędzy tymi dwiema warstwami są nazywane warstwami ukrytymi.
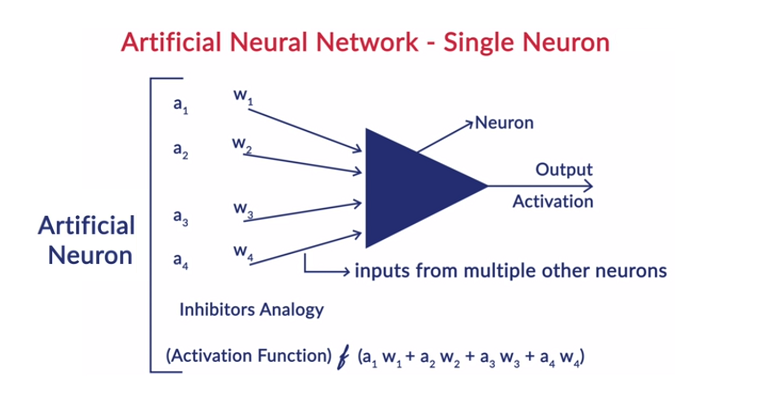
Każdy neuron w warstwie składa się z własnego odchylenia i istnieje waga związana z każdym połączeniem między neuronami z poprzedniej warstwy do następnej warstwy. Każde wejście jest mnożone przez wagę związaną z połączeniem.
Ważona suma wejść jest obliczana dla każdego neuronu w warstwach. Funkcja aktywacji jest stosowana do tej ważonej sumy danych wejściowych i dodawana z odchyleniem neuronu, aby wytworzyć wyjście neuronu. To wyjście służy jako wejście do połączeń tego neuronu w następnej warstwie i tak dalej.
Ten proces nazywa się feedforwardingiem. Wynik warstwy wyjściowej służy jako ostateczna decyzja podjęta przez model. Trening sieci neuronowych odbywa się na podstawie wagi każdego połączenia między neuronami i nastawienia każdego neuronu. Po przewidzeniu wyniku końcowego przez model, model oblicza całkowitą stratę, która jest funkcją wag i błędów systematycznych.
Całkowita strata to w zasadzie suma strat poniesionych przez wszystkie neurony. Ponieważ ostatecznym celem jest zminimalizowanie funkcji kosztu, algorytm cofa się i odpowiednio zmienia wagi i błędy systematyczne. Optymalizację funkcji kosztu można przeprowadzić metodą gradientu. Ten proces jest znany jako wsteczna propagacja.
Założenia w sieciach neuronowych
- Neurony są ułożone w postaci warstw, a warstwy te są ułożone w sposób sekwencyjny.
- Nie ma komunikacji między neuronami znajdującymi się w tej samej warstwie.
- Punktem wejścia sieci neuronowych jest warstwa wejściowa (pierwsza warstwa), a jej punktem wyjścia jest warstwa wyjściowa (ostatnia warstwa).
- Z każdym połączeniem w sieci neuronowej wiąże się pewna waga, a każdy neuron jest z nią powiązany.
- Ta sama funkcja aktywacji jest stosowana do wszystkich neuronów w określonej warstwie.
Przeczytaj: Pomysły na projekty głębokiego uczenia się
Różne algorytmy głębokiego uczenia
1. W pełni podłączona sieć neuronowa
W Fully Connected Neural Network (FCNN) każdy neuron w jednej warstwie jest połączony z każdym innym neuronem w następnej warstwie. Z tego samego powodu warstwy te są nazywane warstwami gęstymi. Te warstwy są bardzo kosztowne obliczeniowo, ponieważ każdy neuron łączy się ze wszystkimi innymi neuronami.
Preferowane jest stosowanie tego algorytmu, gdy liczba neuronów w warstwach jest mniejsza, w przeciwnym razie wykonanie operacji wymagałoby dużej mocy obliczeniowej i czasu. Może również prowadzić do overfittingu ze względu na pełną łączność.
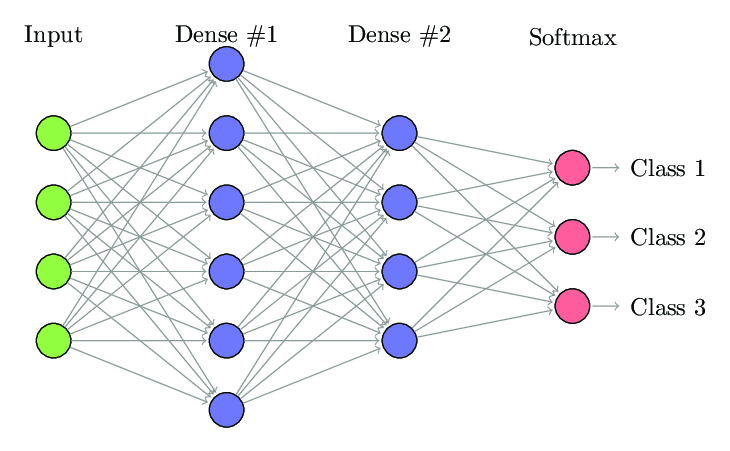
W pełni połączona sieć neuronowa (źródło: Researchgate.net)
2. Konwolucyjna sieć neuronowa (CNN)
Convolutional Neural Network (CNN) to klasa sieci neuronowych zaprojektowanych do pracy z danymi wizualnymi. czyli obrazy i filmy. W związku z tym jest używany do wielu zadań przetwarzania obrazu, takich jak optyczne rozpoznawanie znaków (OCR), lokalizacja obiektów itp. CNN mogą być również używane do rozpoznawania wideo, tekstu i dźwięku.
Obrazy składają się z pikseli, które określają intensywność bieli obrazu. Każdy piksel obrazu jest cechą, która zostanie przekazana do sieci neuronowej. Na przykład obraz 128×128 oznacza, że obraz składa się z 16384 pikseli lub elementów. Zostanie on podany do sieci neuronowej jako wektor o rozmiarze 16384. W przypadku obrazów kolorowych dostępne są 3 kanały (po jednym na każdy – czerwony, niebieski, zielony). W takim przypadku ten sam obrazek w kolorze będzie miał 128x128x3 piksele.
W warstwach CNN istnieje hierarchia. Pierwsza warstwa próbuje wydobyć surowe cechy obrazów, takie jak krawędzie poziome lub pionowe. Drugie warstwy wydobywają więcej wglądu z cech wyodrębnionych przez pierwszą warstwę. Kolejne warstwy zagłębiłyby się następnie głębiej w szczegóły, aby zidentyfikować pewne części obrazu, takie jak włosy, skóra, nos itp. Wreszcie ostatnia warstwa klasyfikowałaby obraz wejściowy jako człowieka, kota, psa itp.
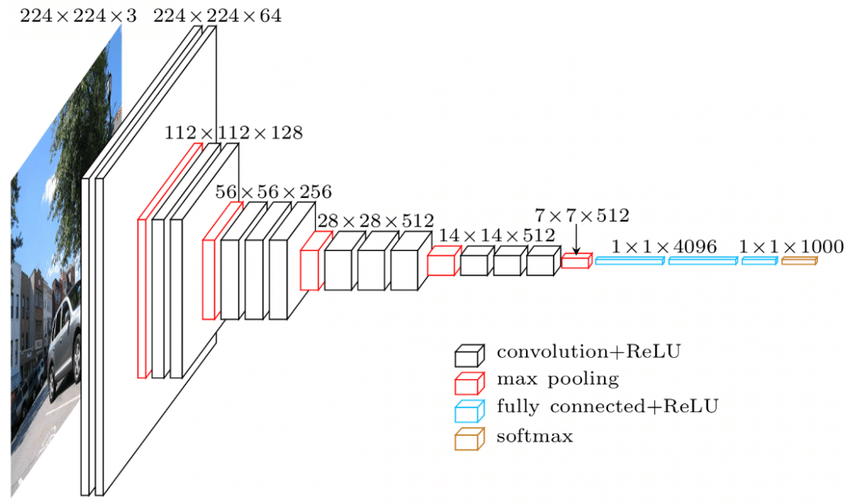
Źródło
Architektura VGGNet — jedna z powszechnie używanych sieci CNN
W CNN istnieją trzy ważne terminy:
- Sploty – Sploty to suma iloczynu pierwiastkowego dwóch macierzy. Jedna macierz jest częścią danych wejściowych, a druga macierz to filtr, który służy do wyodrębniania cech z obrazu.
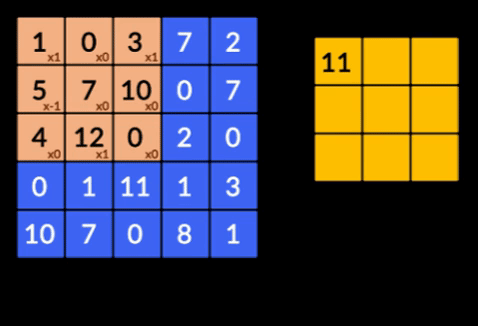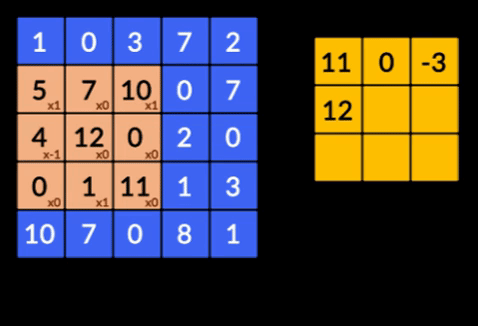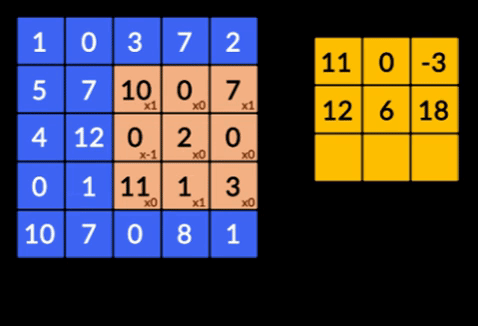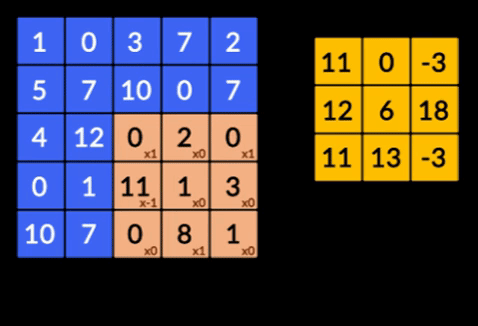
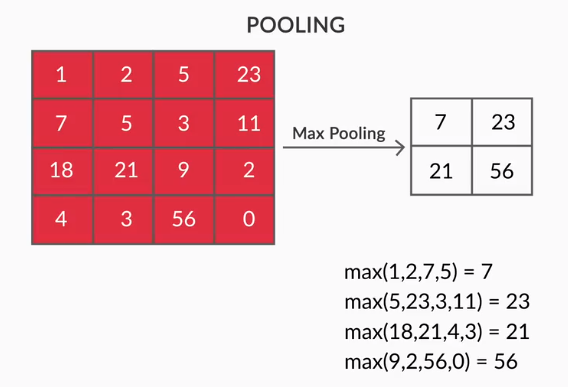
- Pooling Layers – agregacja wyodrębnionych funkcji jest wykonywana przez Pooling Layers. Warstwy te zazwyczaj obliczają zbiorczą statystykę (maksymalną, średnią itp.) i sprawiają, że sieć jest niezmienna w stosunku do lokalnych przekształceń.
- Mapy funkcji – neuron to CNN to w zasadzie filtr, którego wagi są poznawane podczas treningu. Każdy neuron przygląda się określonemu obszarowi na wejściu, który jest znany jako jego pole receptywne. Mapa funkcji to zbiór takich neuronów, które przyglądają się różnym obszarom obrazu o tych samych wagach. Wszystkie neurony na mapie cech próbują wyodrębnić tę samą cechę, ale z różnych obszarów obrazu.
3. Rekurencyjne sieci neuronowe (RNN)
Rekurencyjne sieci neuronowe są zaprojektowane do radzenia sobie z danymi sekwencyjnymi. Dane sekwencyjne oznaczają dane, które mają jakiś związek z danymi poprzednimi, takimi jak tekst (sekwencja słów, zdań itp.) lub wideo (sekwencja obrazów), mowa itp.

Bardzo ważne jest zrozumienie związku między tymi sekwencyjnymi bytami, w przeciwnym razie nie miałoby sensu mieszać całego akapitu i próbować wydobyć z niego jakieś znaczenie. RNN zostały zaprojektowane do przetwarzania tych sekwencyjnych jednostek. Dobrym przykładem wykorzystania RNN jest automatyczne generowanie napisów w YouTube. To nic innego jak Automatyczne Rozpoznawanie Mowy zaimplementowane za pomocą RNN.
Główna różnica między normalnymi sieciami neuronowymi a rekurencyjnymi sieciami neuronowymi polega na tym, że dane wejściowe przepływają w dwóch wymiarach – czasie (wzdłuż długości sekwencji, aby wyodrębnić z niej cechy) i głębokości (normalne warstwy neuronowe). Istnieją różne typy RNN, a ich struktura odpowiednio się zmienia.
- Wiele do jednego RNN: – W tej architekturze wejście podawane do sieci jest sekwencją, a wyjście jest pojedynczą jednostką. Ta architektura jest używana do rozwiązywania problemów, takich jak klasyfikacja tonacji lub do przewidywania wyniku tonacji danych wejściowych (problem regresji). Może być również używany do klasyfikowania filmów do określonych kategorii.
- Wiele do wielu RNN: – Zarówno wejście, jak i wyjście są sekwencjami w tej architekturze. Można go dalej klasyfikować na podstawie długości wejścia i wyjścia.
- Ta sama długość: – Sieć generuje dane wyjściowe w każdym kroku czasowym. W każdym kroku czasowym istnieje zależność jeden do jednego między wejściem i wyjściem. Ta architektura może być używana jako część tagera mowy, w której każde słowo sekwencji w wejściu jest oznaczane jego częścią mowy jako wyjściową w każdym kroku czasowym.
- Inna długość: – W tym przypadku długość wejścia nie jest równa długości wyjścia. Jednym z zastosowań tej architektury jest tłumaczenie języka. Długość zdania w języku angielskim może różnić się od odpowiadającego mu zdania w języku hindi.
- Jeden do wielu RNN: – Wejście jest tutaj pojedynczą jednostką, podczas gdy wyjście jest sekwencją. Tego rodzaju sieci neuronowe są wykorzystywane do zadań takich jak generowanie muzyki, obrazów itp.
- Jeden do jednego RNN: – Jest to tradycyjna sieć neuronowa, w której wejście i wyjście to pojedyncze jednostki.
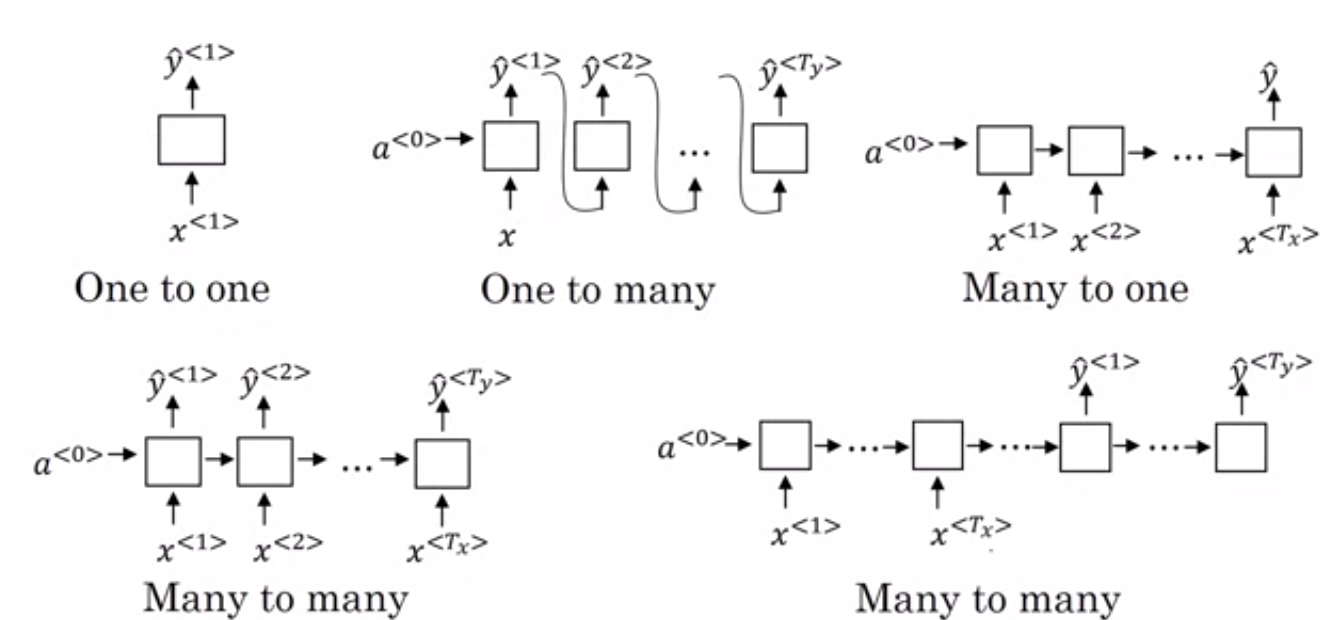
Rodzaje sieci RNN (źródło: iq.opengenus.org)
4. Sieci pamięci długo-krótkotrwałej (LSTM)
Jedną z wad Recurrent Neural Networks jest zanikający problem gradientu. Ten problem pojawia się, gdy trenujemy sieci neuronowe metodami uczenia opartymi na gradientach, takimi jak stochastyczne opadanie gradientu i propagacja wsteczna. Gradienty funkcji aktywacji odpowiadają za aktualizację wag sieci.
Stają się tak małe, że nie ma to większego wpływu na zmianę wag sieci neuronowych. Zapobiega to trenowaniu sieci neuronowych. RNN borykają się z tym problemem, gdy mają trudności z uczeniem się długoterminowych zależności.
Sieci pamięci długo-krótkotrwałej (LSTM) zostały zaprojektowane, aby stawić czoła temu właśnie problemowi. LSTM składa się z jednostki pamięci, która może przechowywać informacje istotne dla poprzednich informacji. Bramkowane jednostki rekurencyjne (GRU) są również wariantem RNN, które pomagają w znikaniu problemów z gradientem.
Oba wykorzystują mechanizm bramkowania, aby rozwiązać ten problem. GRU używa mniej parametrów treningowych, a tym samym zużywa mniej pamięci niż LSTM. Dzięki temu GRU mogą trenować szybciej, ale LSTM zapewnia dokładniejsze wyniki, gdy sekwencje wejściowe są długie.
5. Generatywne sieci kontradyktoryjne (GAN)
Generative Adversarial Networks (GAN) to nienadzorowany algorytm uczenia się, który automatycznie wykrywa i uczy się wzorców na podstawie danych. Po nauczeniu się tych wzorców generuje nowe dane jako dane wyjściowe, które mają te same cechy, co dane wejściowe. Tworzy model, który podzielony jest na dwa podmodele – generator i dyskryminator.
Model generatora stara się generować nowe obrazy z danych wejściowych, natomiast rolą modelu dyskryminatora jest klasyfikowanie, czy dane są rzeczywistym obrazem ze zbioru danych, czy ze sztucznie wygenerowanych obrazów (obrazy z wygenerowanego modelu).
Model dyskryminatora generalnie działa jako klasyfikator binarny w postaci splotowej sieci neuronowej. Z każdą iteracją oba modele próbują poprawić swoje wyniki, ponieważ celem modelu generatora jest oszukanie modelu dyskryminatora w identyfikacji obrazu, a celem dyskryminatora jest poprawna identyfikacja fałszywych obrazów.
6. Ograniczona maszyna Boltzmanna (RBM)
Restricted Boltzmann Machine (RBM) to niedeterministyczne sieci neuronowe z możliwościami generatywnymi i uczą się rozkładu prawdopodobieństwa na wejściu. Są to zastrzeżona forma maszyny Boltzmanna, ograniczona w zakresie połączeń między węzłami w warstwie.
Obejmują one tylko dwie warstwy, tj. warstwę widoczną i warstwę ukrytą. W RBM nie ma warstwy wyjściowej, a warstwy są ze sobą w pełni połączone. RBM są teraz uroczyście używane, ponieważ zostały zastąpione przez GAN. Wiele RBM można również połączyć, aby utworzyć nową sieć, którą można dostroić za pomocą gradientu i propagacji wstecznej, podobnie jak inne sieci neuronowe. Takie sieci nazywane są Deep Belief Networks.
Ograniczona maszyna Boltzmanna (źródło: Medium)
7. Transformatory
Transformatory to rodzaj architektury sieci neuronowej, która została zaprojektowana do neuronowego tłumaczenia maszynowego. Obejmują mechanizm uwagi, który skupia się na części informacji dostarczanych do sieci. Składa się z dwóch części: Enkoderów i Dekoderów.
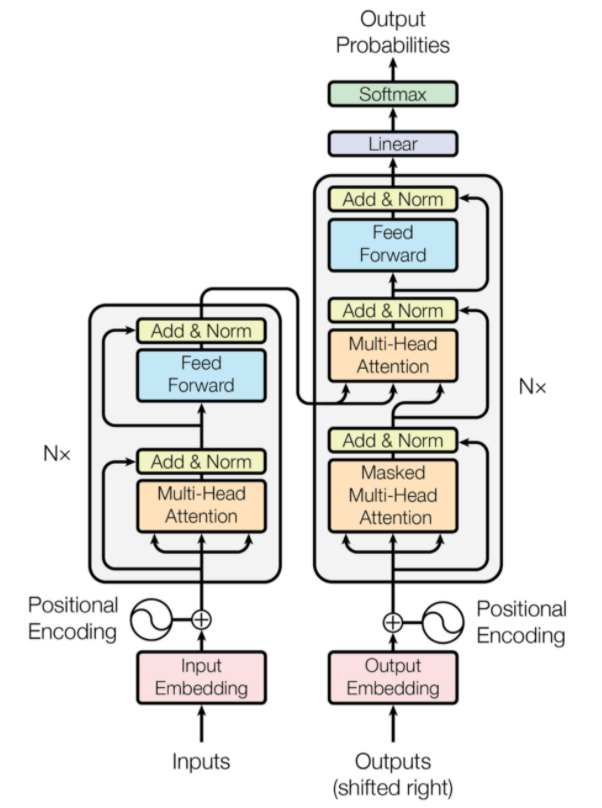
Architektura transformatora (źródło: arxiv.org)
Lewa część rysunku to Encoder, a prawa to Decoder. Koder i dekoder mogą składać się z wielu modułów, które można układać jeden na drugim. To samo przedstawia Nx na rysunku. Funkcją każdej warstwy kodera jest ustalenie, które części danych wejściowych są ze sobą powiązane, co określa się mianem kodowania.
Te kodowania są następnie przekazywane do następnej warstwy kodera jako dane wejściowe. Warstwa dekodera pobiera te kodowania i przetwarza je w celu wygenerowania sekwencji wyjściowej. Uważny mechanizm waży znaczenie każdego innego wejścia i wydobywa informacje z tych relacji, aby przewidzieć sekwencję wyjściową. Warstwy kodera i dekodera również składają się z warstw sprzężenia do przodu, które są wykorzystywane do dalszego przetwarzania danych wyjściowych.
Przeczytaj także: Głębokie uczenie a sieci neuronowe
Wniosek
Artykuł zawierał krótkie wprowadzenie do dziedziny Deep Learning, komponentów używanych w sieciach neuronowych, idei algorytmów głębokiego uczenia, założeń przyjętych w celu uproszczenia sieci neuronowych itp. Ten artykuł zawiera ograniczoną listę algorytmów głębokiego uczenia, które istnieją wiele różnych algorytmów, które są stale tworzone, aby przezwyciężyć ograniczenia istniejących algorytmów.
Algorytmy Deep Learning zrewolucjonizowały sposób przetwarzania filmów, obrazów, tekstu itp. i można je łatwo wdrożyć, importując wymagane pakiety. Wreszcie, dla wszystkich Deep Learners nieskończoność jest granicą.
Jeśli chcesz dowiedzieć się więcej o technikach głębokiego uczenia , uczeniu maszynowym, sprawdź certyfikat PG IIIT-B i upGrad w zakresie uczenia maszynowego i głębokiego uczenia się, który jest przeznaczony dla pracujących profesjonalistów i oferuje ponad 240 godzin rygorystycznych szkoleń, ponad 5 studiów przypadków i zadania, status absolwentów IIIT-B i pomoc w pracy z najlepszymi firmami.
Różnica między CNN a ANN?
Sztuczne sieci neuronowe (ANN) tworzą warstwy sieciowe równoległe do ludzkich warstw neuronowych: wejściowe, ukryte i wyjściowe warstwy decyzyjne. SSN dostrzegają błędy i aktualizują się, restrukturyzując się po wystąpieniu niedociągnięcia. Konwolucyjne sieci neuronowe (CNN) skupiają się głównie na wprowadzaniu obrazów. W sieci CNN pierwsza warstwa wyodrębnia surowy obraz. Następna warstwa łączy się z informacjami znalezionymi w poprzedniej warstwie. Trzecia warstwa identyfikuje cechy obrazu, a ostatnia warstwa rozpoznaje obraz. CNN nie wymagają wyraźnych opisów danych wejściowych; Rozpoznają dane za pomocą cech przestrzennych. Są bardzo preferowane do zadań związanych z rozpoznawaniem wizualnym.
Czy Deep Learning zapewnia przewagę w sztucznej inteligencji?
Sztuczna inteligencja (AI) sprawiła, że technologia jest bardziej dokładna i reprezentatywna dla świata. W ramach uczenia maszynowego w AI, głębokie uczenie może wydajnie przetwarzać duże ilości danych. Ma punkt do punktu podejście do rozwiązywania problemów. Deep Learning stworzył wydajne i szybkie systemy, podczas gdy systemy Machine Learning mają kilka kroków, aby zacząć. Chociaż Deep Learning wymaga dużo czasu na szkolenie, jego wzajemność testowania jest natychmiastowa. Głębokie uczenie jest niezaprzeczalnie integralną częścią sztucznej inteligencji i przyczyniło się do wykrywania danych słuchowych i wizualnych. Umożliwił korzystanie z automatycznych asystentów głosowych, pojazdów i wielu innych technologii.
Jakie są ograniczenia Deep Learning?
Głębokie uczenie poczyniło postępy w interakcji maszyna-człowiek i sprawiło, że technologia stała się użyteczna dla ludzkości na wiele sposobów. Ma przeszkody w postaci szeroko zakrojonych szkoleń, wymagań dotyczących drogiego sprzętu i wymagań wstępnych dotyczących dużych ilości danych. Dostarcza zautomatyzowane rozwiązania, ale podejmuje decyzje, które nie są jasne, dopóki nie zostaną wykonane obliczenia wielu algorytmów i sieci neuronowych. Ścieżka prowadzi do konkretnych węzłów, co jest prawie niemożliwe; Uczenie maszynowe ma prostą ścieżkę śledzenia procesów i jest preferowane. Głębokie uczenie ma wiele ograniczeń, ale jego zalety przeważają nad nimi wszystkimi.