
深層学習アルゴリズム[例を含む包括的なガイド]
公開: 2020-10-28目次
序章
ディープラーニングは機械学習のサブセットであり、脳の配置と機能に触発されたアルゴリズムが含まれます。 人間の脳のニューロンが情報を伝達し、体内の原子炉からの学習を支援するのと同様に、深層学習アルゴリズムはニューラルネットワークアルゴリズムのさまざまな層を実行し、それらの反応から学習します。
言い換えると、ディープラーニングはニューラルネットワークアルゴリズムのレイヤーを利用して、生の入力データに依存するより重要なレベルのデータを検出します。 ニューラルネットワークアルゴリズムは、人間の脳がどのように機能するかをシミュレートするプロセスを通じてデータパターンを検出します。
ニューラルネットワークは、機能の類似性に基づいて、データポイントの大規模なセットからデータポイントをクラスタリングするのに役立ちます。 これらのシステムは、人工ニューラルネットワークとして知られています。
ますます多くのデータがモデルに供給されるにつれて、深層学習アルゴリズムは他のアルゴリズムよりも生産性が高く、より良い結果を提供することが証明されました。 ディープラーニングアルゴリズムは、画像認識、音声認識、不正検出、コンピュータービジョンなどのさまざまな問題に使用されます。
ニューラルネットワークのコンポーネント
1.ネットワークトポロジ–ネットワークトポロジとは、ニューラルネットワークの構造を指します。 これには、ネットワーク内の隠れ層の数、入力層と出力層を含む各層のニューロンの数などが含まれます。
2.入力層–入力層はニューラルネットワークのエントリポイントです。 入力層のニューロンの数は、入力データの属性の数と同じである必要があります。

3.出力層–出力層はニューラルネットワークの出口点です。 出力層のニューロンの数は、ターゲット変数のクラスの数と同じである必要があります(分類問題の場合)。 回帰問題の場合、出力は数値変数になるため、出力層のニューロンの数は1になります。
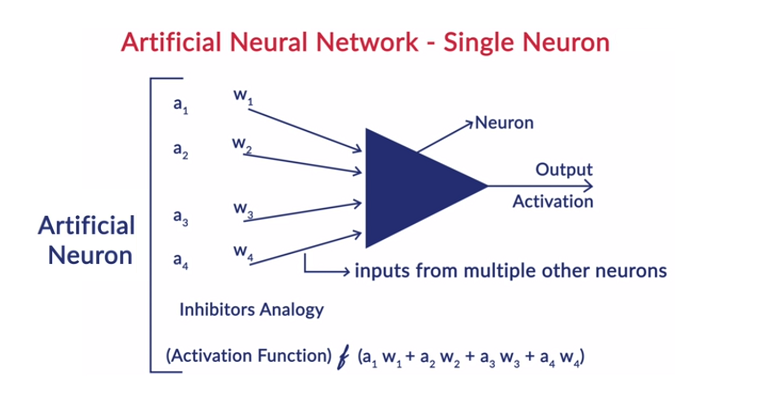
4.活性化関数–活性化関数は、ニューロンの加重入力の合計に適用される数式です。 これは、ニューロンをトリガーする必要があるかどうかを判断するのに役立ちます。 シグモイド関数、Rectified Linear Unit(ReLU)、Leaky ReLU、Hyperbolic Tangent、Softmax関数などの多くの活性化関数があります。
5.重み–連続する層のニューロン間のすべての相互接続には、重みが関連付けられています。 これは、ニューラルネットワークの結果を予測するのに役立つデータパターンを発見する際のニューロン間の接続の重要性を示しています。 重みの値が高いほど、重要性が高くなります。 これは、ネットワークがトレーニングフェーズ中に学習するパラメータの1つです。
6.バイアス–バイアスは、活性化関数を左または右にシフトするのに役立ちます。これは、より良い意思決定のために重要になる可能性があります。 その役割は、線形方程式における切片の役割に類似しています。 重みは、活性化関数の急峻さを高めることができます。つまり、活性化関数がトリガーされる速度を示しますが、バイアスは、活性化関数のトリガーを遅らせるために使用されます。 これは、ネットワークがトレーニングフェーズ中に学習する2番目のパラメーターです。
関連記事:トップディープラーニングテクニック
ニューロンの一般的な働き
ディープラーニングは、人工ニューラルネットワーク(ANN)と連携して、人間の脳の働きを模倣し、人間と同じように学習します。 人工ニューラルネットワークのニューロンは層状に配置されています。 最初と最後のレイヤーは、入力レイヤーと出力レイヤーと呼ばれます。 これら2つのレイヤーの間にあるレイヤーは、非表示レイヤーと呼ばれます。
層内の各ニューロンは独自のバイアスで構成され、前の層から次の層へのニューロン間のすべての相互接続に関連付けられた重みがあります。 各入力は、相互接続に関連付けられた重みで乗算されます。
入力の加重和は、層内のニューロンごとに計算されます。 活性化関数は、この加重された入力の合計に適用され、ニューロンのバイアスが追加されて、ニューロンの出力を生成します。 この出力は、次の層のそのニューロンの接続への入力として機能します。
このプロセスはフィードフォワードと呼ばれます。 出力層の結果は、モデルによって行われる最終決定として機能します。 ニューラルネットワークのトレーニングは、ニューロン間のすべての相互接続の重みとすべてのニューロンのバイアスに基づいて行われます。 モデルによって最終的な結果が予測された後、重みとバイアスの関数である総損失が計算されます。
総損失は、基本的にすべてのニューロンが被った損失の合計です。 最終的な目標はコスト関数を最小化することであるため、アルゴリズムはそれに応じて重みとバイアスをバックトラックして変更します。 コスト関数の最適化は、勾配降下法を使用して実行できます。 このプロセスは、バックプロパゲーションとして知られています。
ニューラルネットワークの仮定
- ニューロンは層の形で配置され、これらの層は順番に配置されます。
- 同じ層内にあるニューロン間の通信はありません。
- ニューラルネットワークの入口点は入力層(最初の層)であり、同じものの出口点は出力層(最後の層)です。
- ニューラルネットワークのすべての相互接続にはある程度の重みが関連付けられており、すべてのニューロンにはバイアスが関連付けられています。
- 同じ活性化関数が特定の層のすべてのニューロンに適用されます。
読む:ディープラーニングプロジェクトのアイデア
さまざまな深層学習アルゴリズム
1.完全に接続されたニューラルネットワーク
Fully Connected Neural Network(FCNN)では、1つの層の各ニューロンは、次の層の他のすべてのニューロンに接続されます。 これらのレイヤーは、まったく同じ理由で高密度レイヤーと呼ばれます。 これらの層は、すべてのニューロンが他のすべてのニューロンと接続するため、計算コストが非常に高くなります。
層内のニューロンの数が少ない場合はこのアルゴリズムを使用することをお勧めします。そうしないと、操作を実行するために多くの計算能力と時間が必要になります。 また、完全な接続性のために過剰適合につながる可能性があります。
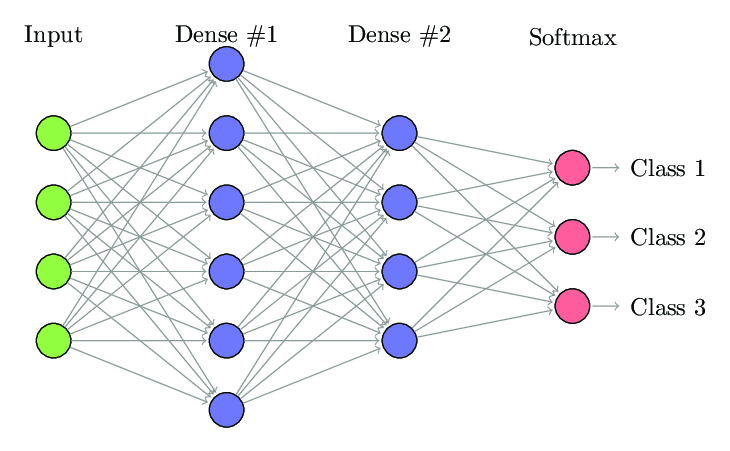
完全に接続されたニューラルネットワーク(出典:Researchgate.net)
2.畳み込みニューラルネットワーク(CNN)
畳み込みニューラルネットワーク(CNN)は、視覚データを処理するように設計されたニューラルネットワークのクラスです。 つまり、画像とビデオ。 したがって、光学式文字認識(OCR)、オブジェクトのローカリゼーションなどの多くの画像処理タスクに使用されます。CNNは、ビデオ、テキスト、およびオーディオの認識にも使用できます。
画像は、画像の白色度の強度を決定するピクセルで構成されています。 画像の各ピクセルは、ニューラルネットワークに供給される特徴です。 たとえば、128×128の画像は、画像が16384ピクセルまたはフィーチャで構成されていることを示します。 サイズ16384のベクトルとしてニューラルネットワークに供給されます。 カラー画像の場合、3つのチャネルがあります(それぞれに1つ–赤、青、緑)。 その場合、同じ色の画像は128x128x3ピクセルで構成されます。
CNNのレイヤーには階層があります。 最初のレイヤーは、水平エッジや垂直エッジなどの画像の生の特徴を抽出しようとします。 2番目のレイヤーは、最初のレイヤーによって抽出された特徴からより多くの洞察を抽出します。 後続のレイヤーは、詳細を深く掘り下げて、髪、肌、鼻などの画像の特定の部分を識別します。最後に、最後のレイヤーは、入力画像を人間、猫、犬などに分類します。
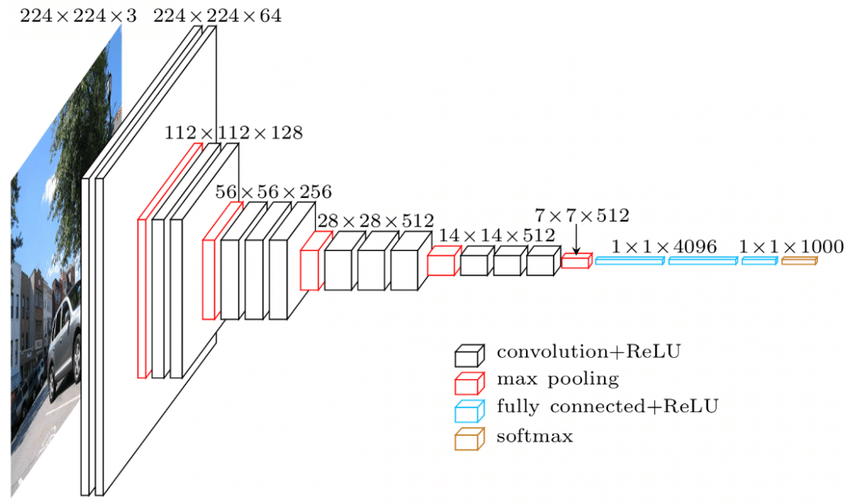
ソース
VGGNetアーキテクチャ–広く使用されているCNNの1つ
CNNには3つの重要な用語があります。
- たたみ込み–たたみ込みは、2つの行列の要素ごとの積の合計です。 1つの行列は入力データの一部であり、もう1つの行列は画像から特徴を抽出するために使用されるフィルターです。
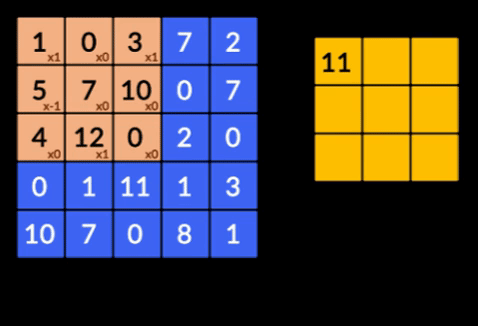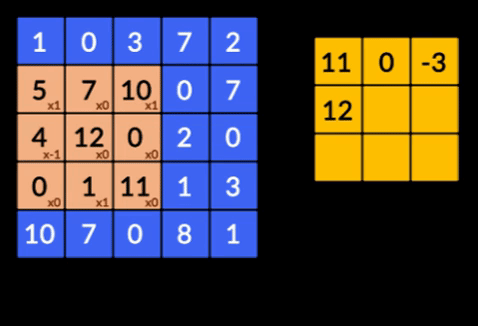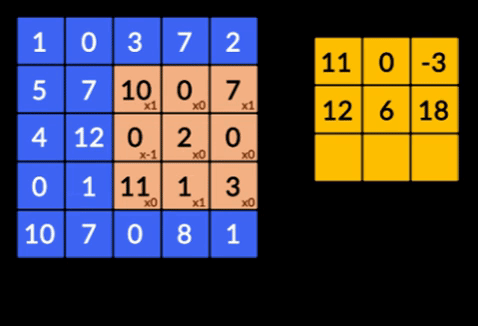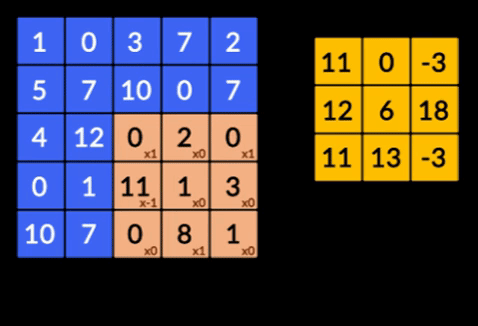
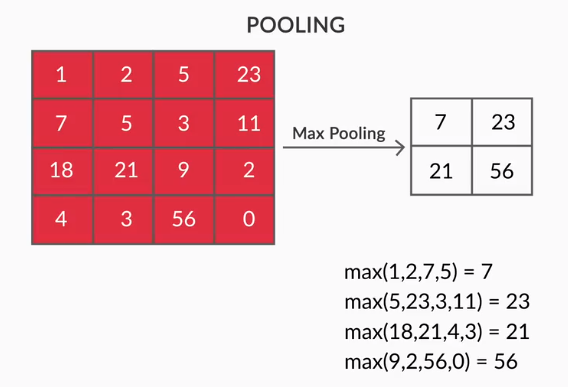
- プーリングレイヤー–抽出された特徴の集約はプーリングレイヤーによって行われます。 これらのレイヤーは通常、集計統計(最大、平均など)を計算し、ネットワークをローカル変換に対して不変にします。

- 機能マップ–ニューロンはCNNであり、基本的にはトレーニング中に重みが学習されるフィルターです。 各ニューロンは、受容野として知られている入力の特定の領域を調べます。 特徴マップは、同じ重みで画像のさまざまな領域を見るそのようなニューロンのコレクションです。 特徴マップ内のすべてのニューロンは、画像の異なる領域から同じ特徴を抽出しようとします。
3.リカレントニューラルネットワーク(RNN)
リカレントニューラルネットワークは、シーケンシャルデータを処理するように設計されています。 シーケンシャルデータとは、テキスト(単語、文のシーケンスなど)やビデオ(画像のシーケンス)、音声など、以前のデータと何らかの関係があるデータを意味します。
これらの連続したエンティティ間の関係を理解することは非常に重要です。そうしないと、段落全体を混乱させて、そこから何らかの意味を導き出そうとしても意味がありません。 RNNは、これらのシーケンシャルエンティティを処理するように設計されています。 使用されているRNNの良い例は、YouTubeでの字幕の自動生成です。 これは、RNNを使用して実装された自動音声認識に他なりません。
通常のニューラルネットワークとリカレントニューラルネットワークの主な違いは、入力データが時間(シーケンスの長さに沿って特徴を抽出する)と深さ(通常のニューラルレイヤー)の2つの次元に沿って流れることです。 RNNにはさまざまなタイプがあり、それに応じて構造が変化します。
- 多対1のRNN:–このアーキテクチャでは、ネットワークに供給される入力はシーケンスであり、出力は単一のエンティティです。 このアーキテクチャは、感情分類などの問題に対処したり、入力データの感情スコアを予測したりするために使用されます(回帰問題)。 また、ビデオを特定のカテゴリに分類するために使用することもできます。
- 多対多RNN:–入力と出力の両方がこのアーキテクチャのシーケンスです。 入力と出力の長さに基づいてさらに分類できます。
- 同じ長さ:–ネットワークは各タイムステップで出力を生成します。 各タイムステップでの入力と出力の間には1対1の対応があります。 このアーキテクチャは、入力内のシーケンスの各単語がすべてのタイムステップで出力としての品詞でタグ付けされる品詞タガーとして使用できます。
- 異なる長さ:–この場合、入力の長さは出力の長さと等しくありません。 このアーキテクチャの用途の1つは、言語の翻訳です。 英語の文の長さは、対応するヒンディー語の文とは異なる場合があります。
- 1対多のRNN:–ここでの入力は単一のエンティティですが、出力はシーケンスです。 これらの種類のニューラルネットワークは、音楽や画像などの生成などのタスクに使用されます。
- 1対1のRNN:–これは、入力と出力が単一のエンティティである従来のニューラルネットワークです。
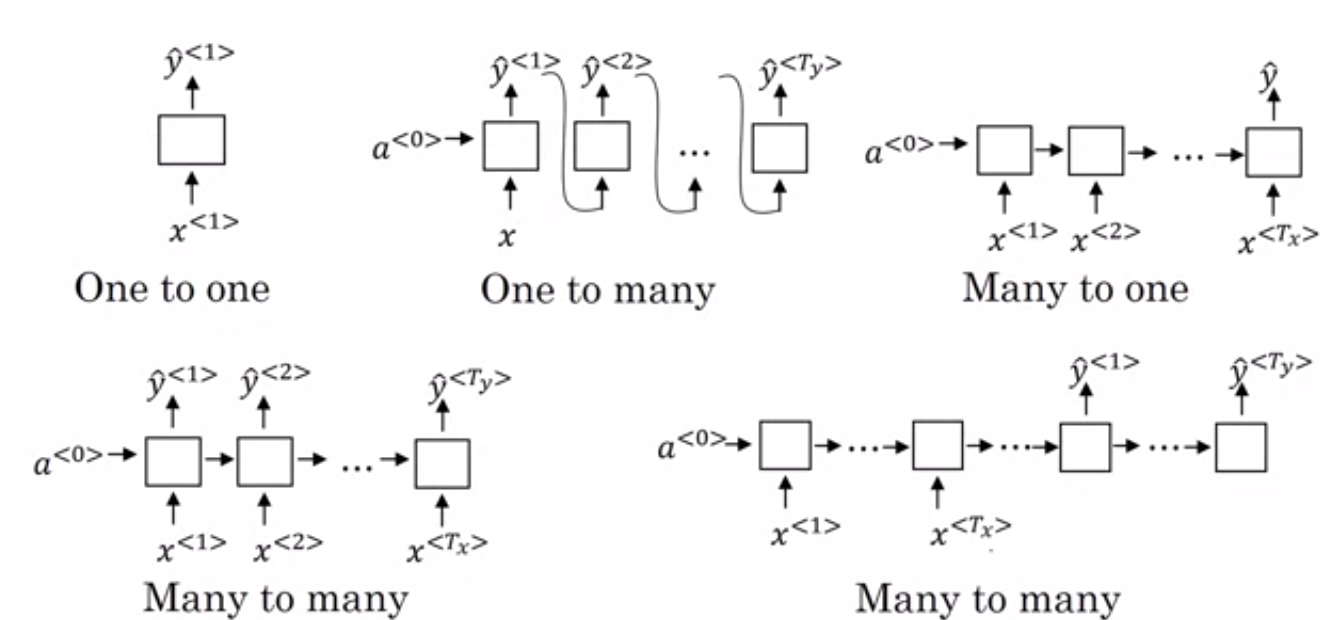
RNNの種類(出典:iq.opengenus.org)
4.長期–短期記憶ネットワーク(LSTM)
リカレントニューラルネットワークの欠点の1つは、勾配消失問題です。 この問題は、確率的勾配降下法やバックプロパゲーションなどの勾配ベースの学習方法でニューラルネットワークをトレーニングしているときに発生します。 活性化関数の勾配は、ネットワークの重みを更新する役割を果たします。
それらは非常に小さくなるので、変化する神経ネットワークの重みにほとんど影響を与えません。 これにより、ニューラルネットワークのトレーニングが妨げられます。 RNNは、長期的な依存関係の学習に問題がある場合にこの問題に直面します。
長期–短期記憶ネットワーク(LSTM)は、この非常に問題に遭遇するように設計されました。 LSTMは、以前の情報に関連する情報を格納できるメモリユニットで構成されています。 ゲート付き回帰ユニット(GRU)も、勾配消失問題の解消に役立つRNNの変形です。
どちらもこの問題を解決するためにゲーティングメカニズムを使用しています。 GRUは、LSTMよりも少ないトレーニングパラメータを使用するため、使用するメモリも少なくなります。 これにより、GRUはより高速にトレーニングできますが、LSTMは、入力シーケンスが長い場合に、より正確な結果を提供します。
5.生成的敵対的ネットワーク(GAN)
Generative Adversarial Networks(GAN)は、データからパターンを自動的に検出して学習する教師なし学習アルゴリズムです。 これらのパターンを学習した後、入力と同じ特性を持つ新しいデータを出力として生成します。 ジェネレーターとディスクリミネーターの2つのサブモデルに分割されたモデルを作成します。
ジェネレーターモデルは入力から新しい画像を生成しようとしますが、ディスクリミネーターモデルの役割は、データがデータセットからの実際の画像であるか、人工的に生成された画像(生成されたモデルからの画像)からであるかを分類することです。
弁別器モデルは、一般に、畳み込みニューラルネットワークの形式で二項分類器として機能します。 ジェネレータモデルの目的は画像を識別する際に弁別子モデルをだますことであり、弁別子の目的は偽の画像を正しく識別することであるため、反復ごとに、両方のモデルが結果を改善しようとします。
6.制限付きボルツマンマシン(RBM)
制限付きボルツマンマシン(RBM)は、生成機能を備えた非決定論的ニューラルネットワークであり、入力全体の確率分布を学習します。 それらは、層内のノード間の相互接続の観点から制限された、ボルツマンマシンの制限された形式です。
これらには、可視層と非表示層の2つの層のみが含まれます。 RBMには出力レイヤーがなく、レイヤーは互いに完全に接続されています。 RBMは、GANに置き換えられたため、現在は厳粛に使用されています。 複数のRBMを組み合わせて、他のニューラルネットワークと同様に最急降下法とバックプロパゲーションを使用して調整できる新しいネットワークを作成することもできます。 このようなネットワークは、ディープビリーフネットワークと呼ばれます。
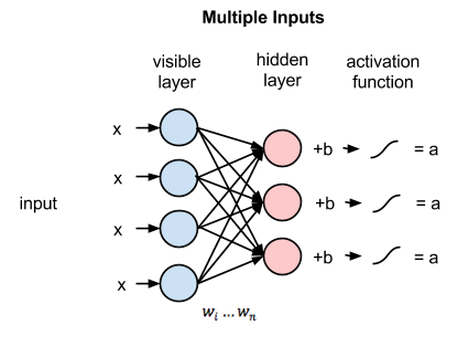
制限付きボルツマンマシン(出典:中)
7.トランスフォーマー
トランスフォーマーは、ニューラル機械翻訳用に設計されたニューラルネットワークアーキテクチャの一種です。 それらは、ネットワークに提供される情報の一部に焦点を当てる注意メカニズムを含みます。 これには、エンコーダーとデコーダーの2つの部分が含まれます。
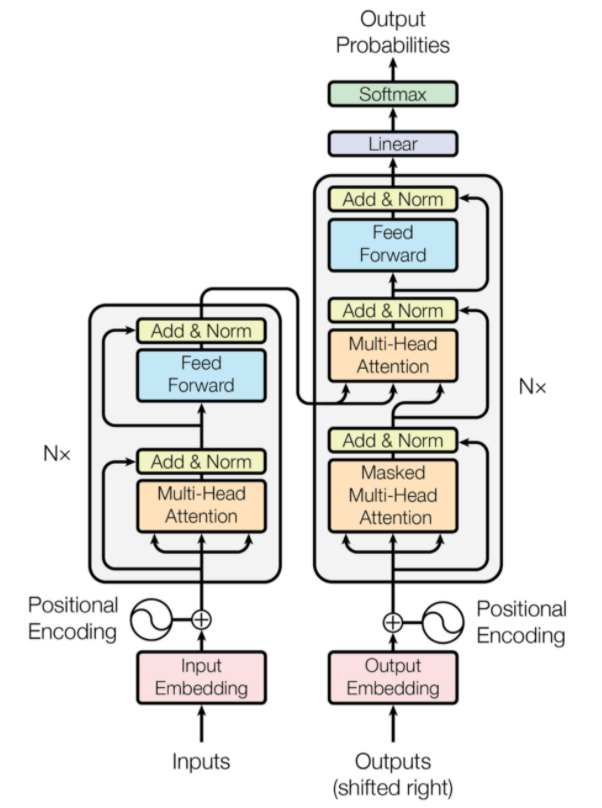
Transformerアーキテクチャ(出典:arxiv.org)
図の左側がエンコーダー、右側がデコーダーです。 エンコーダーとデコーダーは、互いに積み重ねることができる複数のモジュールで構成できます。 同じことが図のNxによって伝えられます。 各エンコーダーレイヤーの機能は、入力のどの部分が互いに関連しているかを把握することです。これは、エンコーディングと呼ばれます。
これらのエンコーディングは、入力として次のエンコーダ層に渡されます。 デコーダー層はこれらのエンコーディングを取得し、それらを処理して出力シーケンスを生成します。 注意深いメカニズムは、他のすべての入力の重要性を評価し、これらの関係から情報を抽出して、出力シーケンスを予測します。 エンコーダー層とデコーダー層も、出力のさらなる処理に使用されるフィードフォワード層で構成されます。
また読む:ディープラーニングとニューラルネットワーク
結論
この記事では、ディープラーニングドメイン、ニューラルネットワークで使用されるコンポーネント、ディープラーニングアルゴリズムのアイデア、ニューラルネットワークを簡素化するための前提条件などについて簡単に紹介しました。この記事では、ディープラーニングアルゴリズムの制限付きリストを提供します。既存のアルゴリズムの制限を克服するために絶えず作成されている多くの異なるアルゴリズム。
ディープラーニングアルゴリズムは、ビデオ、画像、テキストなどの処理方法に革命をもたらし、必要なパッケージをインポートすることで簡単に実装できます。 最後に、すべてのディープラーナーにとって、無限大が限界です。
深層学習技術、機械学習について詳しく知りたい場合は、機械学習と深層学習におけるIIIT-BとupGradのPG認定を確認してください。これは、働く専門家向けに設計されており、240時間以上の厳格なトレーニング、5つ以上のケーススタディを提供します。 &アサインメント、IIIT-B同窓生のステータスとトップ企業との仕事の支援。
CNNとANNの違いは?
人工ニューラルネットワーク(ANN)は、人間の神経層に平行なネットワーク層(入力、非表示、出力の決定層)を構築します。 ANNは障害を認識し、欠点の後に自分自身を再構築することによって自分自身を更新します。 畳み込みニューラルネットワーク(CNN)は、主に画像入力に焦点を合わせています。 CNNでは、最初のレイヤーが生の画像を抽出します。 次のレイヤーは、前のレイヤーで見つかった情報をピアリングします。 3番目のレイヤーは画像の特徴を識別し、最後のレイヤーは画像を認識します。 CNNは明示的な入力記述を必要としません。 それらは、空間的特徴を使用してデータを認識します。 それらは視覚認識タスクに非常に好まれます。
ディープラーニングは人工知能の優位性を提供していますか?
人工知能(AI)は、テクノロジーをより正確で世界を代表するものにしました。 AIの機械学習の一部として、ディープラーニングは大量のデータを効率的に処理できます。 問題を解決するためのポイントツーポイントアプローチがあります。 ディープラーニングは効率的で迅速なシステムを作成しましたが、機械学習システムには開始するためのいくつかのステップがあります。 ディープラーニングには多くのトレーニング時間が必要ですが、テストの相互関係は瞬時に行われます。 ディープラーニングは、間違いなく人工知能の不可欠な部分であり、聴覚および視覚データの検出に貢献しています。 これにより、自動音声アシスタントデバイス、車両、およびその他の多くのテクノロジーが可能になりました。
ディープラーニングの制限は何ですか?
ディープラーニングは、機械と人間の相互作用を進歩させ、テクノロジーをさまざまな方法で人類に提供できるようにしました。 広範なトレーニング、高価な機器要件、および大規模なデータの前提条件というハードルがあります。 自動化されたソリューションを提供しますが、多数のアルゴリズムとニューラルネットワークの計算が実行されるまで明確ではない決定を下します。 経路は特定のノードにまでさかのぼりますが、これはほとんど不可能です。 機械学習はプロセスを追跡するためのまっすぐな道を持っており、望ましいです。 ディープラーニングには多くの制限がありますが、その利点はそれらすべてを上回ります。