
Алгоритм глубокого обучения [Полное руководство с примерами]
Опубликовано: 2020-10-28Оглавление
Введение
Глубокое обучение — это разновидность машинного обучения, включающая алгоритмы, основанные на устройстве и функционировании мозга. Подобно тому, как нейроны человеческого мозга передают информацию и помогают в обучении с помощью реакторов в нашем теле, аналогичным образом алгоритмы глубокого обучения проходят через различные уровни алгоритмов нейронных сетей и учатся на их реакциях.
Другими словами, глубокое обучение использует слои алгоритмов нейронных сетей для обнаружения данных более важного уровня, зависящих от необработанных входных данных. Алгоритмы нейронной сети обнаруживают шаблоны данных с помощью процесса, который имитирует работу человеческого мозга.
Нейронные сети помогают группировать точки данных из большого набора точек данных на основе сходства функций. Эти системы известны как искусственные нейронные сети.
По мере того как в модели подавалось все больше и больше данных, алгоритмы глубокого обучения оказывались более продуктивными и давали лучшие результаты, чем остальные алгоритмы. Алгоритмы глубокого обучения используются для решения различных задач, таких как распознавание изображений, распознавание речи, обнаружение мошенничества, компьютерное зрение и т. д.
Компоненты нейронной сети
1. Топология сети. Топология сети относится к структуре нейронной сети. Он включает в себя количество скрытых слоев в сети, количество нейронов в каждом слое, включая входной и выходной слои и т. д.
2. Входной слой . Входной слой — это точка входа в нейронную сеть. Количество нейронов во входном слое должно быть равно количеству атрибутов во входных данных.

3. Выходной слой . Выходной слой — это точка выхода нейронной сети. Количество нейронов в выходном слое должно быть равно количеству классов в целевой переменной (для задачи классификации). Для задачи регрессии количество нейронов в выходном слое будет равно 1, так как выход будет числовой переменной.
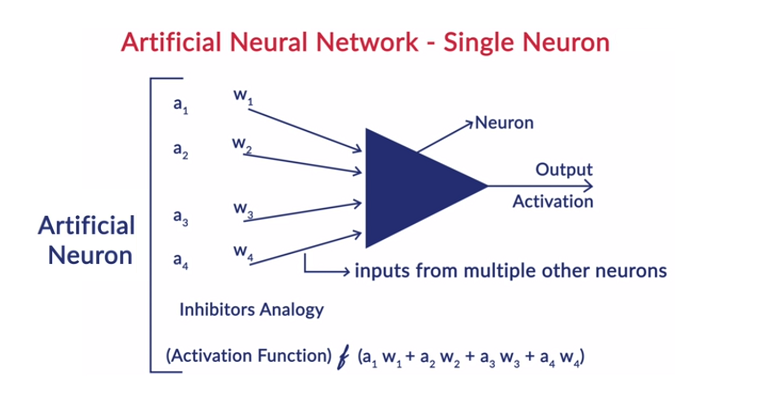
4. Функции активации. Функции активации представляют собой математические уравнения, которые применяются к сумме взвешенных входных данных нейрона. Это помогает определить, должен ли нейрон срабатывать или нет. Существует множество функций активации, таких как сигмовидная функция, выпрямленная линейная единица (ReLU), Leaky ReLU, гиперболический тангенс, функция Softmax и т. д.
5. Веса . Каждая взаимосвязь между нейронами в последовательных слоях имеет связанный с ней вес. Это указывает на важность связи между нейронами в обнаружении некоторого шаблона данных, который помогает предсказать результат нейронной сети. Чем выше значения веса, тем выше значимость. Это один из параметров, который сеть изучает на этапе обучения.
6. Предубеждения . Предубеждения помогают сместить функцию активации влево или вправо, что может иметь решающее значение для лучшего принятия решений. Его роль аналогична роли точки пересечения в линейном уравнении. Веса могут увеличивать крутизну функции активации, т. е. указывают, насколько быстро будет срабатывать функция активации, тогда как смещение используется для задержки срабатывания функции активации. Это второй параметр, который сеть изучает на этапе обучения.
Связанная статья: Лучшие методы глубокого обучения
Общая работа нейрона
Глубокое обучение работает с искусственными нейронными сетями (ИНС), чтобы имитировать работу человеческого мозга и учиться так, как это делает человек. Нейроны в искусственных нейронных сетях расположены слоями. Первый и последний слои называются входным и выходным слоями. Слои между этими двумя слоями называются скрытыми слоями.
Каждый нейрон в слое имеет свое собственное смещение, и каждому взаимодействию между нейронами от предыдущего слоя к следующему слою присваивается вес. Каждый вход умножается на вес, связанный с соединением.
Взвешенная сумма входов рассчитывается для каждого нейрона в слоях. Функция активации применяется к этой взвешенной сумме входных данных и добавляется со смещением нейрона для получения выходных данных нейрона. Этот выход служит входом для соединений этого нейрона в следующем слое и так далее.
Этот процесс называется форвардингом. Результат выходного слоя служит окончательным решением, принятым моделью. Обучение нейронных сетей осуществляется на основе веса каждой взаимосвязи между нейронами и смещения каждого нейрона. После того, как модель предсказывает окончательный результат, она вычисляет общие потери, которые являются функцией весов и погрешностей.
Общая потеря — это сумма потерь, понесенных всеми нейронами. Поскольку конечной целью является минимизация функции стоимости, алгоритм откатывается назад и соответствующим образом изменяет веса и смещения. Оптимизация функции стоимости может быть выполнена с использованием метода градиентного спуска. Этот процесс известен как обратное распространение.
Предположения в нейронных сетях
- Нейроны располагаются в виде слоев, и эти слои располагаются последовательно.
- Связь между нейронами, находящимися внутри одного слоя, отсутствует.
- Точка входа нейронных сетей — это входной слой (первый слой), а точка выхода — выходной слой (последний слой).
- Каждая взаимосвязь в нейронной сети имеет некоторый вес, связанный с ней, и каждый нейрон имеет связанную с ней предвзятость.
- Одна и та же функция активации применяется ко всем нейронам определенного слоя.
Читайте: Идеи проекта глубокого обучения
Различные алгоритмы глубокого обучения
1. Полностью подключенная нейронная сеть
В полносвязной нейронной сети (FCNN) каждый нейрон в одном слое связан с каждым другим нейроном в следующем слое. Эти слои называются плотными слоями по той же причине. Эти слои очень затратны в вычислительном отношении, поскольку каждый нейрон соединяется со всеми другими нейронами.
Этот алгоритм предпочтительнее использовать, когда количество нейронов в слоях меньше, иначе для выполнения операций потребуется много вычислительной мощности и времени. Это также может привести к переоснащению из-за его полной связности.
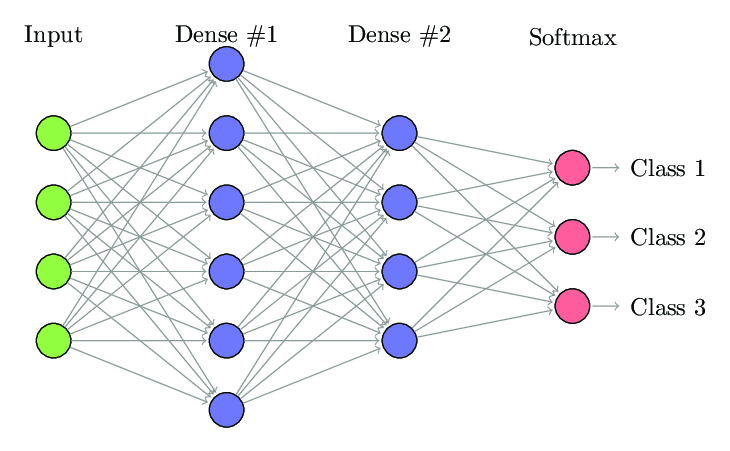
Полностью подключенная нейронная сеть (Источник: Researchgate.net)
2. Сверточная нейронная сеть (CNN)
Сверточная нейронная сеть (CNN) — это класс нейронных сетей, предназначенных для работы с визуальными данными. то есть изображения и видео. Таким образом, он используется для многих задач обработки изображений, таких как оптическое распознавание символов (OCR), локализация объектов и т. д. CNN также можно использовать для распознавания видео, текста и звука.
Изображения состоят из пикселей, которые определяют интенсивность белого цвета на изображении. Каждый пиксель изображения — это функция, которая будет передана в нейронную сеть. Например, изображение размером 128×128 указывает на то, что изображение состоит из 16 384 пикселей или элементов. Он будет передан в виде вектора размером 16384 в нейронную сеть. Для цветных изображений предусмотрено 3 канала (по одному на каждый — красный, синий, зеленый). В этом случае одно и то же изображение в цвете будет иметь размер 128x128x3 пикселя.
В слоях CNN существует иерархия. Первый слой пытается извлечь необработанные функции изображений, такие как горизонтальные или вертикальные края. Вторые слои извлекают больше информации из функций, извлеченных первым слоем. Последующие слои затем будут углубляться в особенности, чтобы идентифицировать определенные части изображения, такие как волосы, кожа, нос и т. д. Наконец, последний слой будет классифицировать входное изображение как человека, кошку, собаку и т. д.
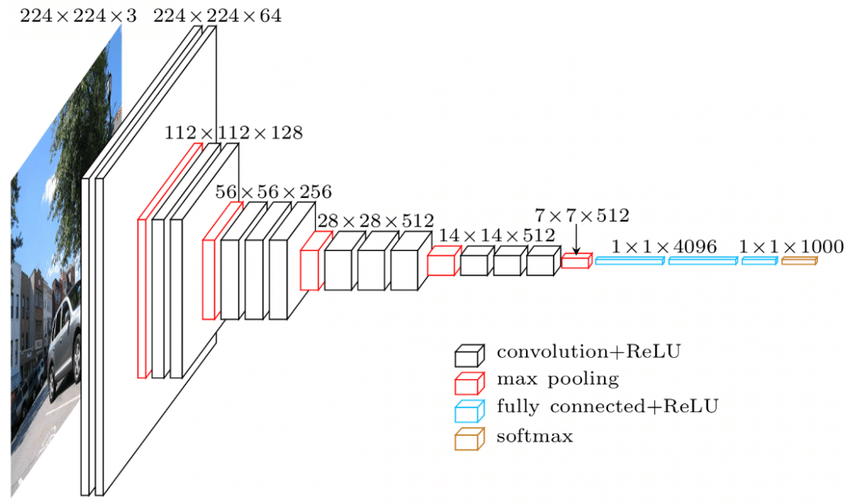
Источник
Архитектура VGGNet — одна из широко используемых CNN.
В CNN используются три важных термина:
- Свертки — свертки — это сумма поэлементного произведения двух матриц. Одна матрица является частью входных данных, а другая матрица является фильтром, который используется для извлечения признаков из изображения.
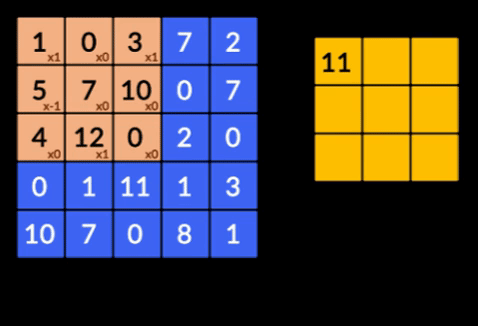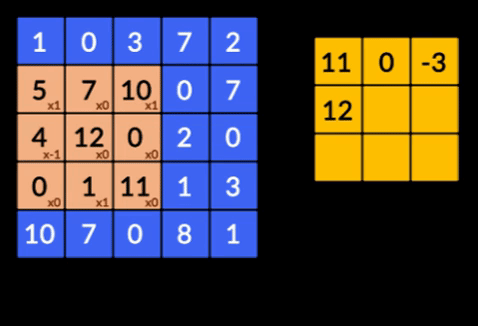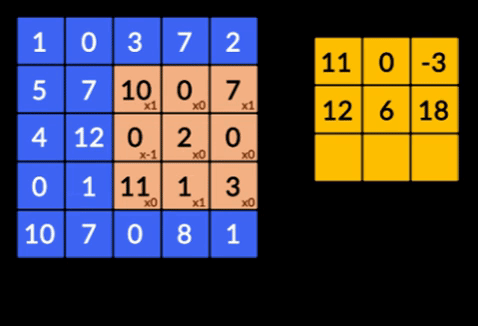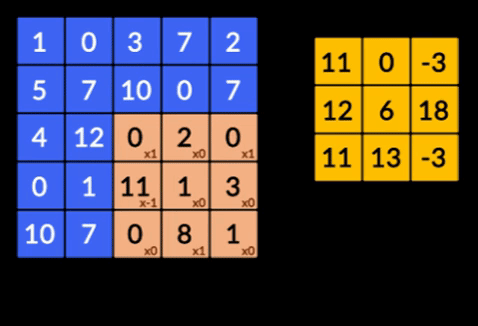
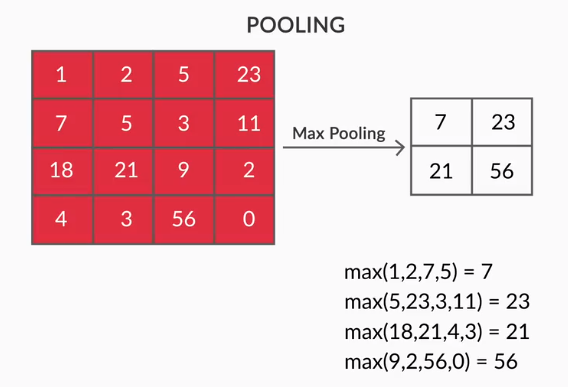
- Слои пула — объединение извлеченных объектов осуществляется слоями пула. Эти слои обычно вычисляют совокупную статистику (максимум, среднее и т. д.) и делают сеть инвариантной к локальным преобразованиям.
- Карты признаков. Нейрон — это CNN, по сути, фильтр, веса которого изучаются во время обучения. Каждый нейрон смотрит на определенную область на входе, известную как его рецептивное поле. Карта признаков — это набор таких нейронов, которые смотрят на разные области изображения с одинаковыми весами. Все нейроны на карте признаков пытаются извлечь один и тот же признак, но из разных областей изображения.
3. Рекуррентные нейронные сети (RNN)
Рекуррентные нейронные сети предназначены для работы с последовательными данными. Последовательные данные означают данные, которые имеют некоторую связь с предыдущими данными, такими как текст (последовательность слов, предложений и т. д.) или видео (последовательность изображений), речь и т. д.

Очень важно понимать связь между этими последовательными сущностями, иначе не имеет смысла смешивать весь абзац и пытаться извлечь из него какой-то смысл. RNN были разработаны для обработки этих последовательных объектов. Хорошим примером использования RNN является автоматическое создание субтитров на YouTube. Это не что иное, как автоматическое распознавание речи, реализованное с использованием RNN.
Основное различие между обычными нейронными сетями и рекуррентными нейронными сетями заключается в том, что входные данные проходят по двум измерениям — времени (по длине последовательности для извлечения из нее признаков) и глубине (обычные нейронные слои). Существуют различные типы RNN, и соответственно меняется их структура.
- Многие к одному RNN: – В этой архитектуре ввод, подаваемый в сеть, представляет собой последовательность, а вывод – единый объект. Эта архитектура используется для решения таких проблем, как классификация тональности или для прогнозирования оценки тональности входных данных (проблема регрессии). Его также можно использовать для классификации видео по определенным категориям.
- Многие ко многим RNN: – И вход, и выход являются последовательностями в этой архитектуре. Его можно дополнительно классифицировать на основе длины входа и выхода.
- Одинаковая длина: – Сеть выдает выходные данные на каждом временном шаге. На каждом временном шаге существует однозначное соответствие между входом и выходом. Эту архитектуру можно использовать как средство маркировки части речи, где каждое слово последовательности на входе помечается своей частью речи в качестве вывода на каждом временном шаге.
- Различная длина: – В этом случае длина ввода не равна длине вывода. Одним из применений этой архитектуры является языковой перевод. Длина предложения на английском языке может отличаться от соответствующего предложения на хинди.
- RNN «один ко многим»: вход здесь представляет собой один объект, а выход — последовательность. Эти виды нейронных сетей используются для таких задач, как генерация музыки, изображений и т. д.
- RNN «один к одному»: — это традиционная нейронная сеть, в которой вход и выход являются отдельными объектами.
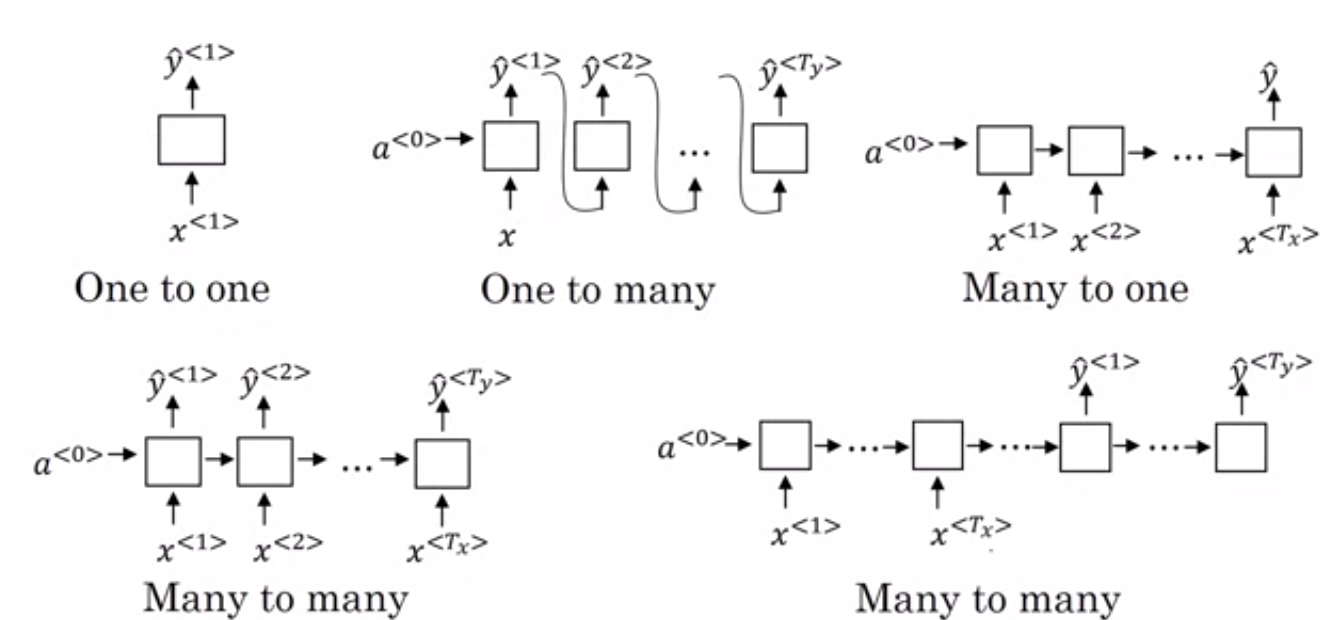
Типы RNN (Источник: iq.opengenus.org)
4. Сети долговременной памяти (LSTM)
Одним из недостатков рекуррентных нейронных сетей является исчезающая проблема градиента. Эта проблема возникает, когда мы обучаем нейронные сети с помощью методов обучения на основе градиента, таких как стохастический градиентный спуск и обратное распространение ошибки. Градиенты функции активации отвечают за обновление весов сетей.
Они становятся настолько маленькими, что практически не влияют на изменение веса нейронных сетей. Это предотвращает обучение нейронных сетей. RNN сталкиваются с этой проблемой, когда у них возникают трудности с изучением долгосрочных зависимостей.
Сети долговременной памяти (LSTM) были разработаны именно для решения этой проблемы. LSTM состоит из блока памяти, в котором может храниться информация, относящаяся к предыдущей информации. Закрытые рекуррентные единицы (GRU) также являются вариантом RNN, которые помогают решить проблемы с исчезающим градиентом.
Оба используют механизм стробирования для решения этой проблемы. GRU использует меньше параметров обучения и, следовательно, использует меньше памяти, чем LSTM. Это позволяет GRU обучаться быстрее, но LSTM обеспечивает более точные результаты при длинных входных последовательностях.
5. Генеративно-состязательные сети (GAN)
Генеративно-состязательные сети (GAN) — это неконтролируемый алгоритм обучения, который автоматически обнаруживает и изучает шаблоны из данных. Изучив эти шаблоны, он генерирует новые данные на выходе, которые имеют те же характеристики, что и входные данные. Он создает модель, которая делится на две подмодели — генератор и дискриминатор.
Модель генератора пытается генерировать новые изображения из входных данных, тогда как роль модели дискриминатора заключается в том, чтобы классифицировать, являются ли данные реальным изображением из набора данных или искусственно сгенерированными изображениями (изображениями из сгенерированной модели).
Модель дискриминатора обычно действует как бинарный классификатор в форме сверточной нейронной сети. С каждой итерацией обе модели пытаются улучшить свои результаты, поскольку цель модели генератора — обмануть модель дискриминатора при идентификации изображения, а цель дискриминатора — правильно идентифицировать поддельные изображения.
6. Ограниченная машина Больцмана (RBM)
Ограниченная машина Больцмана (RBM) — это недетерминированные нейронные сети с генеративными возможностями, которые изучают распределение вероятностей по входным данным. Они представляют собой ограниченную форму машины Больцмана, ограниченную с точки зрения взаимосвязей между узлами в слое.
Они включают только два слоя, т.е. видимый слой и скрытый слой. В RBM нет выходного слоя и слои полностью связаны друг с другом. RBM теперь торжественно используются, поскольку они были заменены GAN. Несколько RBM также могут быть объединены для создания новой сети, которую можно настроить с помощью градиентного спуска и обратного распространения, как и другие нейронные сети. Такие сети называются сетями глубокого убеждения.
Ограниченная машина Больцмана (Источник: Medium)
7. Трансформеры
Трансформеры — это тип архитектуры нейронной сети, который был разработан для нейронного машинного перевода. Они включают механизм внимания, который фокусируется на части информации, предоставляемой сети. Он состоит из двух частей: кодеров и декодеров.
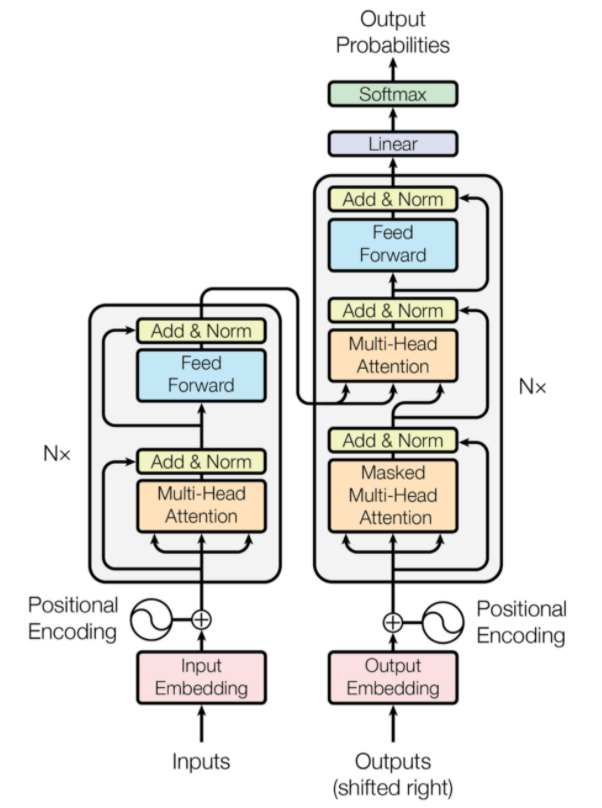
Трансформаторная архитектура (Источник: arxiv.org)
Левая часть рисунка — кодировщик, а правая — декодер. Кодер и декодер могут состоять из нескольких модулей, которые можно ставить друг на друга. То же самое передается через Nx на рисунке. Функция каждого уровня кодировщика состоит в том, чтобы выяснить, какие части входных данных имеют отношение друг к другу, что называется кодированием.
Эти кодировки затем передаются на следующий уровень кодировщика в качестве входных данных. Уровень декодера принимает эти кодировки и обрабатывает их для создания выходной последовательности. Внимательный механизм взвешивает значимость каждого другого входа и извлекает информацию из этих взаимосвязей, чтобы предсказать выходную последовательность. Уровни кодера и декодера также состоят из слоев прямой связи, которые используются для дальнейшей обработки выходных данных.
Читайте также: Глубокое обучение против нейронных сетей
Заключение
В статье дано краткое введение в область глубокого обучения, компоненты, используемые в нейронных сетях, идея алгоритмов глубокого обучения, предположения, сделанные для упрощения нейронных сетей, и т. д. В этой статье представлен ограниченный список алгоритмов глубокого обучения, поскольку они существуют. множество различных алгоритмов, которые постоянно создаются для преодоления ограничений существующих алгоритмов.
Алгоритмы глубокого обучения произвели революцию в способах обработки видео, изображений, текста и т. д., и их можно легко реализовать, импортировав необходимые пакеты. Наконец, для всех Глубоких Учеников пределом является бесконечность.
Если вам интересно узнать больше о методах глубокого обучения и машинном обучении, ознакомьтесь с сертификацией PG IIIT-B и upGrad в области машинного обучения и глубокого обучения, которая предназначена для работающих профессионалов и предлагает более 240 часов тщательного обучения, 5+ тематических исследований. и задания, статус выпускника IIIT-B и помощь в трудоустройстве в ведущих фирмах.
Разница между CNN и ANN?
Искусственные нейронные сети (ИНС) создают сетевые уровни, параллельные человеческим нейронным слоям: входные, скрытые и выходные уровни принятия решений. ANN воспринимают ошибки и обновляют себя, реструктурируя себя после недостатка. Сверточные нейронные сети (CNN) в основном ориентированы на ввод изображений. В CNN первый слой извлекает необработанное изображение. Следующий уровень вглядывается в информацию, найденную на предыдущем уровне. Третий слой идентифицирует особенности изображения, а последний слой распознает изображение. CNN не требуют явных входных описаний; Они распознают данные, используя пространственные функции. Они очень предпочтительны для задач визуального распознавания.
Дает ли глубокое обучение преимущество в области искусственного интеллекта?
Искусственный интеллект (ИИ) сделал технологии более точными и репрезентативными для мира. Как часть машинного обучения в ИИ, глубокое обучение может эффективно обрабатывать большие объемы данных. Он имеет точечный подход к решению проблем. Глубокое обучение создало эффективные и быстрые системы, в то время как системы машинного обучения требуют нескольких шагов для начала работы. Хотя для глубокого обучения требуется много времени на обучение, его проверка взаимности происходит мгновенно. Глубокое обучение, несомненно, является неотъемлемой частью искусственного интеллекта и способствует обнаружению слуховых и визуальных данных. Это сделало возможными автоматизированные голосовые помощники, транспортные средства и многие другие технологии.
Каковы ограничения глубокого обучения?
Глубокое обучение добилось больших успехов во взаимодействии человека и машины и сделало технологии полезными для человечества во многих отношениях. Он сталкивается с препятствиями, связанными с обширным обучением, требованиями к дорогостоящему оборудованию и предварительными требованиями к большим данным. Он предоставляет автоматизированные решения, но принимает решения, которые не ясны до тех пор, пока не будут проведены вычисления многочисленных алгоритмов и нейронных сетей. Путь прослеживается до конкретных узлов, что практически невозможно; Машинное обучение имеет прямой путь отслеживания процессов и предпочтительнее. Глубокое обучение имеет много ограничений, но его преимущества перевешивают их все.