
深度學習算法【帶示例的綜合指南】
已發表: 2020-10-28目錄
介紹
深度學習是機器學習的一個子集,它涉及受大腦排列和功能啟發的算法。 由於來自人類大腦的神經元傳遞信息並幫助從我們體內的反應器中學習,同樣,深度學習算法貫穿神經網絡算法的各個層並從它們的反應中學習。
換句話說,深度學習利用神經網絡算法層來發現依賴於原始輸入數據的更重要的級別數據。 神經網絡算法通過模擬人腦工作方式的過程來發現數據模式。
神經網絡有助於根據特徵的相似性從大量數據點中對數據點進行聚類。 這些系統被稱為人工神經網絡。
隨著越來越多的數據被輸入到模型中,深度學習算法被證明比其他算法更有效率並提供更好的結果。 深度學習算法用於解決各種問題,如圖像識別、語音識別、欺詐檢測、計算機視覺等。
神經網絡的組成部分
1.網絡拓撲——網絡拓撲是指神經網絡的結構。 它包括網絡中隱藏層的數量,包括輸入和輸出層在內的每層中的神經元數量等。
2.輸入層——輸入層是神經網絡的入口點。 輸入層的神經元數量應該等於輸入數據中的屬性數量。

3.輸出層——輸出層是神經網絡的出口點。 輸出層的神經元數量應該等於目標變量中的類數量(對於分類問題)。 對於回歸問題,輸出層中的神經元數量將為 1,因為輸出將是一個數值變量。
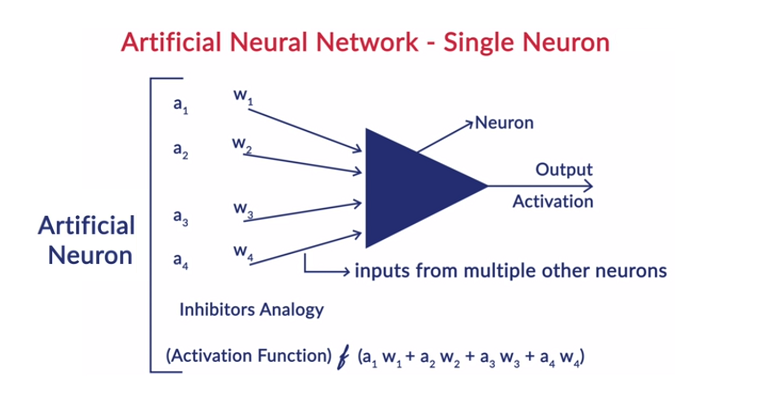
4.激活函數——激活函數是適用於神經元加權輸入總和的數學方程。 它有助於確定是否應該觸發神經元。 有許多激活函數,如 sigmoid 函數、整流線性單元 (ReLU)、Leaky ReLU、雙曲正切、Softmax 函數等。
5.權重——連續層中神經元之間的每個互連都有一個與之相關的權重。 它表明神經元之間的連接在發現一些有助於預測神經網絡結果的數據模式中的重要性。 權重值越高,顯著性越高。 它是網絡在訓練階段學習的參數之一。
6.偏差——偏差有助於將激活函數向左或向右移動,這對於更好的決策至關重要。 它的作用類似於線性方程中截距的作用。 權重可以增加激活函數的陡度,即表明激活函數將觸發多快,而偏差用於延遲激活函數的觸發。 它是網絡在訓練階段學習的第二個參數。
相關文章:頂級深度學習技術
神經元的一般工作
深度學習與人工神經網絡 (ANN) 一起工作,以模仿人類大腦的工作並以人類的方式進行學習。 人工神經網絡中的神經元是分層排列的。 第一層和最後一層稱為輸入層和輸出層。 這兩層之間的層稱為隱藏層。
該層中的每個神經元都包含其自身的偏差,並且從上一層到下一層的神經元之間的每個互連都有一個權重。 每個輸入乘以與互連相關的權重。
為層中的每個神經元計算輸入的加權和。 將激活函數應用於該輸入的加權和,並與神經元的偏差相加以產生神經元的輸出。 該輸出用作下一層中該神經元連接的輸入,依此類推。
這個過程稱為前饋。 輸出層的結果作為模型做出的最終決定。 神經網絡的訓練是基於神經元之間每個互連的權重和每個神經元的偏差來完成的。 在模型預測最終結果後,它會計算總損失,這是權重和偏差的函數。
Total Loss 基本上是所有神經元損失的總和。 由於最終目標是最小化成本函數,因此算法會回溯並相應地更改權重和偏差。 成本函數的優化可以使用梯度下降法來完成。 這個過程稱為反向傳播。
神經網絡中的假設
- 神經元以層的形式排列,並且這些層以順序的方式排列。
- 同一層內的神經元之間沒有通信。
- 神經網絡的入口點是輸入層(第一層),出口點是輸出層(最後一層)。
- 神經網絡中的每個互連都有一些與之相關的權重,每個神經元都有與之相關的偏差。
- 相同的激活函數應用於某一層中的所有神經元。
閱讀:深度學習項目理念
不同的深度學習算法
1. 全連接神經網絡
在全連接神經網絡 (FCNN) 中,一層中的每個神經元都連接到下一層中的每個其他神經元。 出於同樣的原因,這些層被稱為密集層。 這些層在計算上非常昂貴,因為每個神經元都與所有其他神經元相連。
當層中的神經元數量較少時,最好使用該算法,否則將需要大量的計算能力和時間來執行操作。 由於其完全連通性,它也可能導致過度擬合。
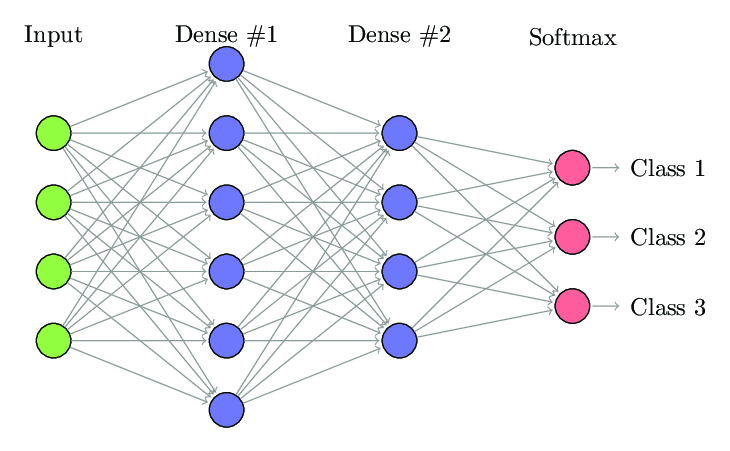
全連接神經網絡(來源:Researchgate.net)
2. 卷積神經網絡 (CNN)
卷積神經網絡 (CNN) 是一類神經網絡,旨在處理視覺數據。 即圖像和視頻。 因此,它用於許多圖像處理任務,如光學字符識別 (OCR)、對象定位等。CNN 也可用於視頻、文本和音頻識別。
圖像由確定圖像中白度強度的像素組成。 圖像的每個像素都是一個特徵,將被饋送到神經網絡。 例如,128×128 的圖像表示該圖像由 16384 個像素或特徵組成。 它將作為大小為 16384 的向量饋送到神經網絡。 對於彩色圖像,有 3 個通道(每個通道一個 - 紅、藍、綠)。 在這種情況下,相同的彩色圖像將由 128x128x3 像素組成。
CNN 的層中有層次結構。 第一層嘗試提取圖像的原始特徵,如水平或垂直邊緣。 第二層從第一層提取的特徵中提取更多見解。 隨後的層將深入研究細節以識別圖像的某些部分,例如頭髮、皮膚、鼻子等。最後,最後一層將輸入圖像分類為人、貓、狗等。
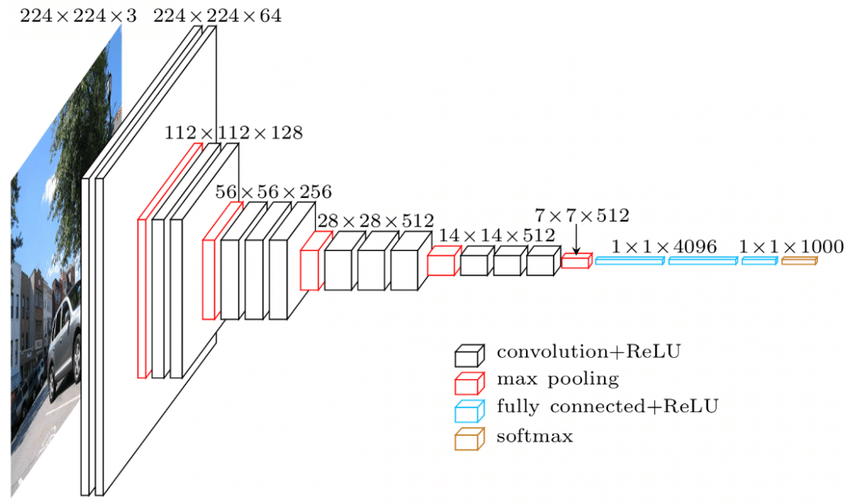
資源
VGGNet 架構——廣泛使用的 CNN 之一
CNN 中有三個重要的術語:
- 卷積——卷積是兩個矩陣的元素乘積的總和。 一個矩陣是輸入數據的一部分,另一個矩陣是用於從圖像中提取特徵的濾波器。
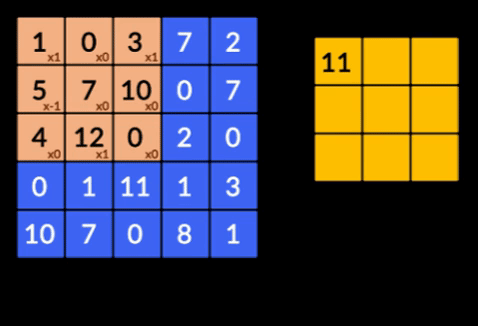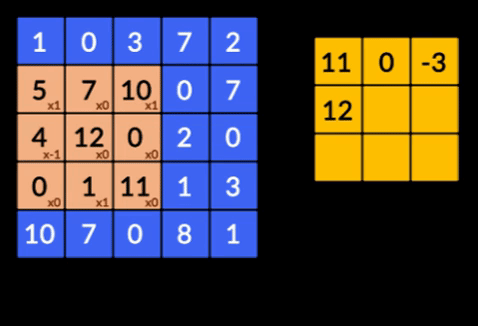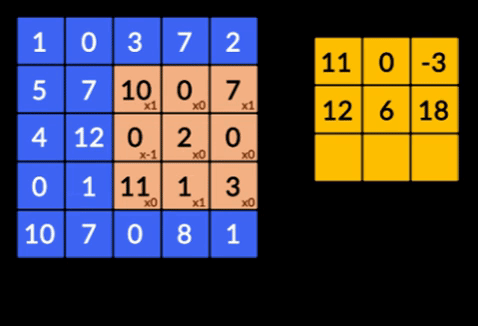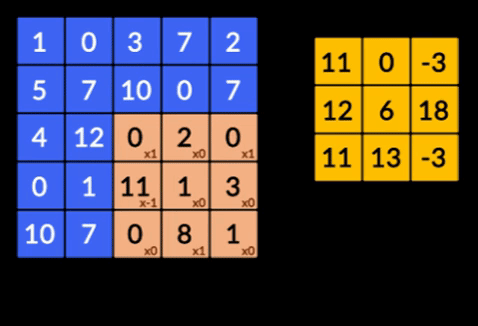

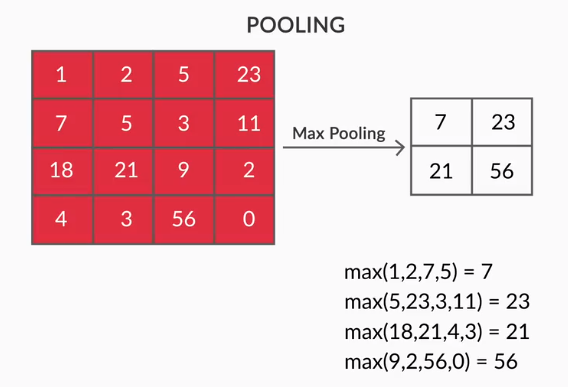
- 池化層——提取特徵的聚合由池化層完成。 這些層通常計算聚合統計量(最大值、平均值等),並使網絡對局部變換保持不變。
- 特徵圖——神經元是 CNN,基本上是一個過濾器,其權重是在訓練期間學習的。 每個神經元查看輸入中的特定區域,該區域稱為其感受野。 特徵圖是這樣的神經元的集合,它們以相同的權重查看圖像的不同區域。 特徵圖中的所有神經元都嘗試從圖像的不同區域提取相同的特徵。
3. 遞歸神經網絡 (RNN)
循環神經網絡旨在處理順序數據。 序列數據是指與先前數據有某種聯繫的數據,例如文本(單詞、句子等的序列)或視頻(圖像序列)、語音等。
了解這些連續實體之間的聯繫非常重要,否則將整個段落弄亂並試圖從中得出一些含義是沒有意義的。 RNN 旨在處理這些順序實體。 使用 RNN 的一個很好的例子是在 YouTube 中自動生成字幕。 它只不過是使用 RNN 實現的自動語音識別。
普通神經網絡和循環神經網絡之間的主要區別在於輸入數據沿兩個維度流動——時間(沿序列長度以從中提取特徵)和深度(普通神經層)。 有不同類型的 RNN,它們的結構也相應發生變化。
- 多對一 RNN:——在這種架構中,輸入網絡是一個序列,輸出是一個單一的實體。 該架構用於解決情感分類等問題或預測輸入數據的情感分數(回歸問題)。 它還可用於將視頻分類為某些類別。
- 多對多 RNN: - 輸入和輸出都是此架構中的序列。 它可以根據輸入和輸出的長度進一步分類。
- 相同長度: – 網絡在每個時間步產生一個輸出。 每個時間步的輸入和輸出之間存在一一對應的關係。 這種架構可以用作詞性標記器,其中輸入序列中的每個單詞都在每個時間步用其詞性作為輸出進行標記。
- 不同的長度: – 在這種情況下,輸入的長度不等於輸出的長度。 這種架構的用途之一是語言翻譯。 英語句子的長度可能與相應的印地語句子不同。
- 一對多 RNN:——這裡的輸入是單個實體,而輸出是一個序列。 這些類型的神經網絡用於生成音樂、圖像等任務。
- 一對一 RNN: - 它是一種傳統的神經網絡,其中輸入和輸出是單個實體。
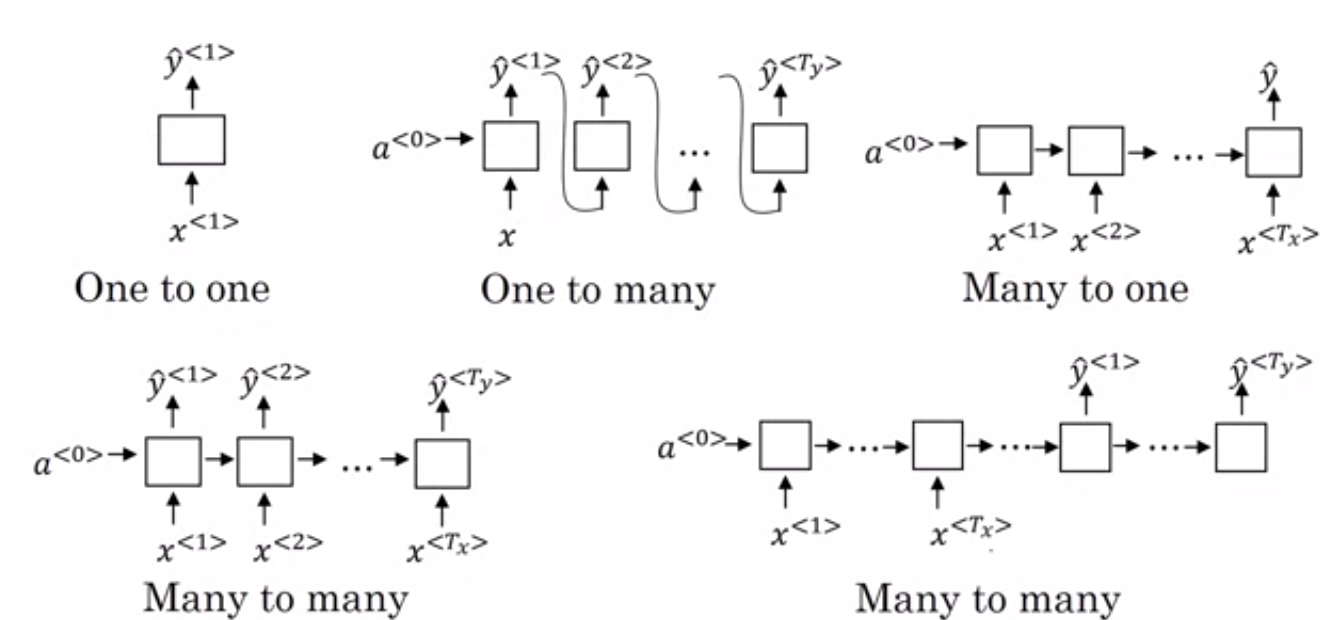
RNN 的類型(來源:iq.opengenus.org)
4. 長短期記憶網絡(LSTM)
遞歸神經網絡的缺點之一是梯度消失問題。 當我們使用隨機梯度下降和反向傳播等基於梯度的學習方法訓練神經網絡時會遇到這個問題。 激活函數的梯度負責更新網絡的權重。
它們變得如此之小,以至於幾乎不會影響神經網絡的權重變化。 這可以防止神經網絡訓練。 當 RNN 在學習長期依賴方面遇到困難時,他們會面臨這個問題。
長短期記憶網絡 (LSTM) 旨在解決這個問題。 LSTM 由一個存儲單元組成,它可以存儲與先前信息相關的信息。 門控循環單元 (GRU) 也是 RNN 的一種變體,有助於消除梯度問題。
兩者都使用門控機制來解決這個問題。 GRU 使用更少的訓練參數,因此比 LSTM 使用更少的內存。 這使 GRU 能夠更快地訓練,但 LSTM 在輸入序列較長的情況下提供更準確的結果。
5. 生成對抗網絡(GAN)
生成對抗網絡 (GAN) 是一種無監督學習算法,可自動從數據中發現和學習模式。 在學習了這些模式之後,它會生成與輸入具有相同特徵的新數據作為輸出。 它創建了一個模型,該模型分為兩個子模型——生成器和鑑別器。
生成器模型嘗試從輸入生成新圖像,而判別器模型的作用是分類數據是來自數據集的真實圖像還是來自人工生成的圖像(來自生成模型的圖像)。
鑑別器模型通常充當卷積神經網絡形式的二元分類器。 在每次迭代中,兩個模型都試圖改進其結果,因為生成器模型的目標是在識別圖像時欺騙判別器模型,而判別器的目標是正確識別假圖像。
6. 受限玻爾茲曼機(RBM)
受限玻爾茲曼機 (RBM) 是具有生成能力的非確定性神經網絡,可以學習輸入的概率分佈。 它們是玻爾茲曼機的受限形式,受限於層中節點之間的互連。
這些只涉及兩層,即可見層和隱藏層。 RBM 中沒有輸出層,並且層之間是完全連接的。 RBM 現在被鄭重地使用,因為它們已被 GAN 取代。 也可以將多個 RBM 組合在一起以創建一個新網絡,該網絡可以像其他神經網絡一樣使用梯度下降和反向傳播進行調整。 這樣的網絡被稱為深度信念網絡。
受限玻爾茲曼機(來源:Medium)
7. 變形金剛
Transformer 是一種神經網絡架構,專為神經機器翻譯而設計。 它們涉及一種注意力機制,該機制專注於提供給網絡的部分信息。 它涉及兩個部分:編碼器和解碼器。
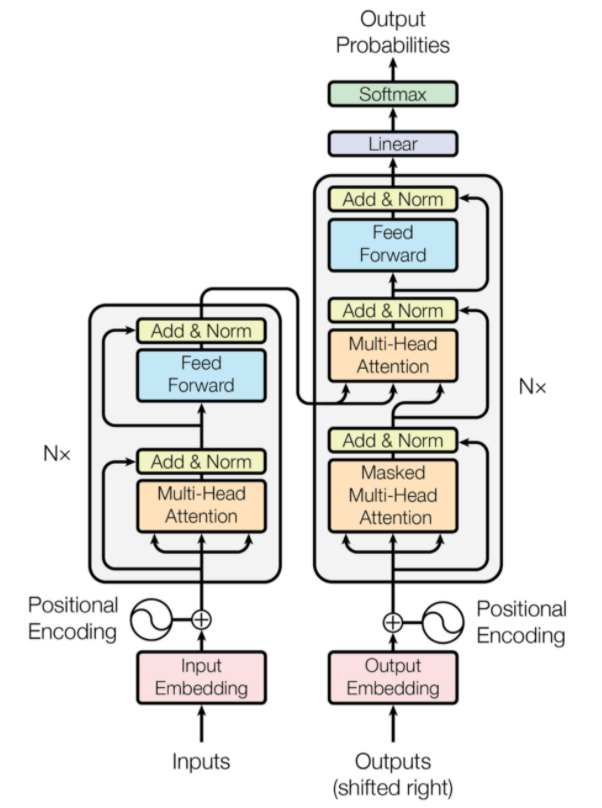
變壓器架構(來源:arxiv.org)
圖中左邊是Encoder,右邊是Decoder。 編碼器和解碼器可以由多個模塊組成,這些模塊可以相互堆疊。 圖中的Nx也是如此。 每個編碼器層的功能是找出輸入的哪些部分彼此相關,這些部分稱為編碼。
然後將這些編碼作為輸入傳遞到下一個編碼器層。 解碼器層採用這些編碼並對其進行處理以生成輸出序列。 注意力機制權衡每個其他輸入的重要性並從這些關係中提取信息以預測輸出序列。 編碼器和解碼器層還包括用於進一步處理輸出的前饋層。
另請閱讀:深度學習與神經網絡
結論
本文簡要介紹了深度學習領域、神經網絡中使用的組件、深度學習算法的思想、簡化神經網絡的假設等。本文提供了深度學習算法的限制列表,因為有許多不同的算法不斷被創造出來,以克服現有算法的局限性。
深度學習算法徹底改變了處理視頻、圖像、文本等的方式,並且可以通過導入所需的包輕鬆實現。 最後,對於所有深度學習者來說,無限是極限。
如果您有興趣了解有關深度學習技術、機器學習的更多信息,請查看 IIIT-B 和 upGrad 的機器學習和深度學習 PG 認證,該認證專為在職專業人士設計,提供 240 多個小時的嚴格培訓、5 個以上的案例研究和分配,IIIT-B 校友身份和頂級公司的工作協助。
CNN和ANN的區別?
人工神經網絡 (ANN) 構建與人類神經層平行的網絡層:輸入、隱藏和輸出決策層。 人工神經網絡能夠感知錯誤並在出現缺陷後通過自我重組來更新自己。 卷積神經網絡 (CNN) 主要關注圖像輸入。 在 CNN 中,第一層提取原始圖像。 下一層對等到上一層中找到的信息。 第三層識別圖像的特徵,最後一層識別圖像。 CNN 不需要明確的輸入描述; 他們使用空間特徵識別數據。 它們非常適合視覺識別任務。
深度學習是否提供了人工智能的優勢?
人工智能 (AI) 使技術更加準確和具有世界代表性。 作為人工智能機器學習的一部分,深度學習可以有效地處理大量數據。 它具有解決問題的點對點方法。 深度學習創建了高效快速的系統,而機器學習系統需要幾個步驟才能開始。 儘管深度學習需要大量的訓練時間,但它的測試互惠是瞬時的。 不可否認,深度學習是人工智能不可或缺的一部分,並有助於檢測聽覺和視覺數據。 它使自動語音助手設備、車輛和許多其他技術成為可能。
深度學習的局限性是什麼?
深度學習在人機交互方面取得了長足進步,並使技術在許多方面為人類服務。 它具有廣泛的培訓、昂貴的設備要求和大數據先決條件等障礙。 它提供了自動化的解決方案,但在執行大量算法和神經網絡的計算之前,它做出的決策並不明確。 路徑追溯到特定節點,這幾乎是不可能的; 機器學習具有跟踪過程的直接路徑,並且是可取的。 深度學習確實有很多局限性,但它的優勢超過了所有這些。