
Algoritmo di deep learning [Guida completa con esempi]
Pubblicato: 2020-10-28Sommario
introduzione
Il Deep Learning è un sottoinsieme dell'apprendimento automatico, che coinvolge algoritmi ispirati alla disposizione e al funzionamento del cervello. Poiché i neuroni del cervello umano trasmettono informazioni e aiutano nell'apprendimento dai reattori nel nostro corpo, allo stesso modo gli algoritmi di apprendimento profondo attraversano vari livelli di algoritmi di reti neurali e imparano dalle loro reazioni.
In altre parole, l'apprendimento profondo utilizza livelli di algoritmi di rete neurale per scoprire dati di livello più significativi dipendenti dai dati di input grezzi. Gli algoritmi della rete neurale scoprono i modelli di dati attraverso un processo che simula in un certo modo il funzionamento di un cervello umano.
Le reti neurali aiutano a raggruppare i punti dati da un ampio insieme di punti dati in base alle somiglianze delle caratteristiche. Questi sistemi sono conosciuti come reti neurali artificiali.
Man mano che un numero sempre maggiore di dati veniva fornito ai modelli, gli algoritmi di deep learning si sono rivelati più produttivi e forniscono risultati migliori rispetto al resto degli algoritmi. Gli algoritmi di Deep Learning vengono utilizzati per vari problemi come riconoscimento di immagini, riconoscimento vocale, rilevamento di frodi, visione artificiale, ecc.
Componenti della rete neurale
1. Topologia di rete: la topologia di rete si riferisce alla struttura della rete neurale. Include il numero di livelli nascosti nella rete, il numero di neuroni in ogni livello incluso il livello di input e output ecc.
2. Input Layer – Input Layer è il punto di ingresso della rete neurale. Il numero di neuroni nel livello di input dovrebbe essere uguale al numero di attributi nei dati di input.

3. Output Layer – Output Layer è il punto di uscita della rete neurale. Il numero di neuroni nel livello di output dovrebbe essere uguale al numero di classi nella variabile target (per problemi di classificazione). Per problemi di regressione, il numero di neuroni nel livello di output sarà 1 poiché l'output sarebbe una variabile numerica.
4. Funzioni di attivazione – Le funzioni di attivazione sono equazioni matematiche che si applicano alla somma degli input ponderati di un neurone. Aiuta a determinare se il neurone deve essere attivato o meno. Esistono molte funzioni di attivazione come la funzione sigmoidea, l'unità lineare rettificata (ReLU), la Leaky ReLU, la tangente iperbolica, la funzione Softmax ecc.
5. Pesi – Ad ogni interconnessione tra i neuroni negli strati consecutivi è associato un peso. Indica il significato della connessione tra i neuroni nella scoperta di alcuni modelli di dati che aiutano a prevedere l'esito della rete neurale. Maggiori sono i valori di peso, maggiore è la significatività. È uno dei parametri che la rete apprende durante la sua fase di addestramento.
6. Bias – Bias aiuta a spostare la funzione di attivazione a sinistra oa destra, il che può essere fondamentale per un migliore processo decisionale. Il suo ruolo è analogo al ruolo di un'intercetta nell'equazione lineare. I pesi possono aumentare la pendenza della funzione di attivazione, ovvero indica la velocità con cui si attiverà la funzione di attivazione, mentre la polarizzazione viene utilizzata per ritardare l'attivazione della funzione di attivazione. È il secondo parametro che la rete apprende durante la sua fase di addestramento.
Articolo correlato: Le migliori tecniche di apprendimento profondo
Funzionamento generale di un neurone
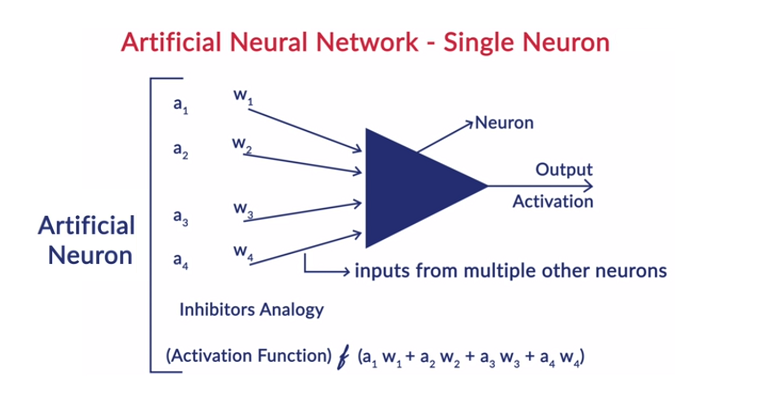
Il Deep Learning funziona con le reti neurali artificiali (ANN) per imitare il funzionamento del cervello umano e per apprendere come fa l'uomo. I neuroni nelle reti neurali artificiali sono disposti a strati. Il primo e l'ultimo livello sono chiamati livelli di input e output. I livelli tra questi due livelli sono chiamati livelli nascosti.
Ogni neurone nello strato è costituito da un proprio bias e c'è un peso associato per ogni interconnessione tra i neuroni dallo strato precedente allo strato successivo. Ogni ingresso viene moltiplicato per il peso associato all'interconnessione.
La somma ponderata degli input viene calcolata per ciascuno dei neuroni negli strati. Una funzione di attivazione viene applicata a questa somma ponderata di input e aggiunta con la distorsione del neurone per produrre l'output del neurone. Questo output funge da input per le connessioni di quel neurone nel livello successivo e così via.
Questo processo è chiamato feedforward. Il risultato del livello di output funge da decisione finale presa dal modello. L'allenamento delle reti neurali avviene sulla base del peso di ogni interconnessione tra i neuroni e del bias di ogni neurone. Dopo che il risultato finale è stato previsto dal modello, calcola la perdita totale che è una funzione dei pesi e delle distorsioni.
La perdita totale è fondamentalmente la somma delle perdite subite da tutti i neuroni. Poiché l'obiettivo finale è ridurre al minimo la funzione di costo, l'algoritmo torna indietro e modifica di conseguenza i pesi e le distorsioni. L'ottimizzazione della funzione di costo può essere effettuata utilizzando il metodo della discesa del gradiente. Questo processo è noto come backpropagation.
Ipotesi nelle Reti Neurali
- I neuroni sono disposti sotto forma di strati e questi strati sono disposti in modo sequenziale.
- Non c'è comunicazione tra i neuroni che si trovano all'interno dello stesso strato.
- Il punto di ingresso delle reti neurali è lo strato di input (primo strato) e il punto di uscita delle stesse è lo strato di uscita (ultimo strato).
- Ogni interconnessione nella rete neurale ha un peso ad essa associato e ogni neurone ha un bias ad esso associato.
- La stessa funzione di attivazione viene applicata a tutti i neuroni in un determinato livello.
Leggi: Idee per progetti di deep learning
Diversi algoritmi di apprendimento profondo
1. Rete neurale completamente connessa
Nella rete neurale completamente connessa (FCNN), ogni neurone in uno strato è connesso a ogni altro neurone nello strato successivo. Questi strati sono indicati come strati densi per lo stesso motivo. Questi strati sono molto costosi dal punto di vista computazionale poiché ogni neurone si connette con tutti gli altri neuroni.
È preferibile utilizzare questo algoritmo quando il numero di neuroni negli strati è inferiore, altrimenti richiederebbe molta potenza di calcolo e tempo per eseguire le operazioni. Può anche portare a un overfitting a causa della sua piena connettività.
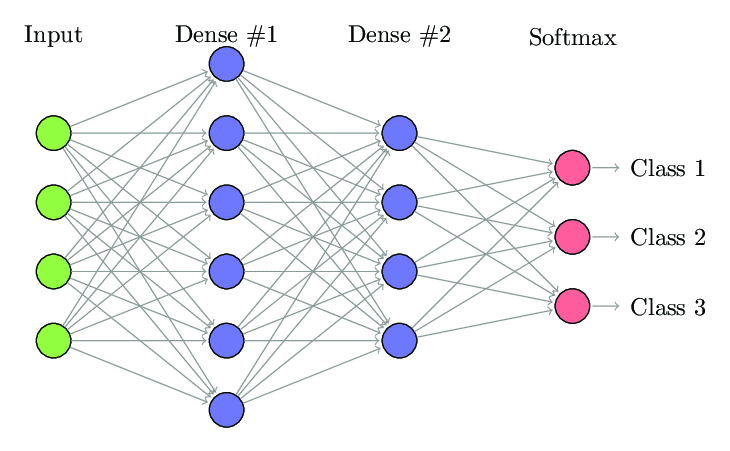
Rete neurale completamente connessa (fonte: Researchgate.net)
2. Rete neurale convoluzionale (CNN)
Le reti neurali convoluzionali (CNN) sono una classe di reti neurali progettate per funzionare con i dati visivi. cioè immagini e video. Pertanto, viene utilizzato per molte attività di elaborazione delle immagini come il riconoscimento ottico dei caratteri (OCR), la localizzazione di oggetti ecc. Le CNN possono essere utilizzate anche per il riconoscimento di video, testo e audio.
Le immagini sono costituite da pixel che determinano l'intensità del bianco nell'immagine. Ogni pixel di un'immagine è una caratteristica che verrà inviata alla rete neurale. Ad esempio, un'immagine 128×128 indica che l'immagine è composta da 16384 pixel o caratteristiche. Sarà alimentato come vettore di dimensione 16384 alla rete neurale. Per le immagini a colori, ci sono 3 canali (uno per ciascuno – Rosso, Blu, Verde). In tal caso, la stessa immagine a colori sarebbe composta da 128x128x3 pixel.
C'è una gerarchia nei livelli della CNN. Il primo livello cerca di estrarre le caratteristiche grezze delle immagini come i bordi orizzontali o verticali. I secondi livelli estraggono più approfondimenti dalle funzionalità estratte dal primo livello. I livelli successivi si immergerebbero quindi più a fondo nelle specifiche per identificare alcune parti di un'immagine come capelli, pelle, naso ecc. Infine, l'ultimo livello classificherebbe l'immagine di input come umana, gatto, cane ecc.
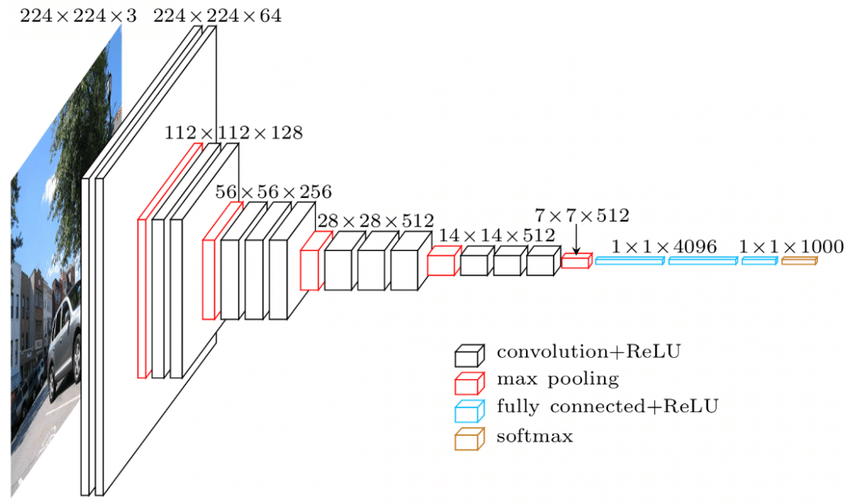
Fonte
Architettura VGGNet – Una delle CNN ampiamente utilizzate
Ci sono tre terminologie importanti nelle CNN:
- Convoluzioni: le convoluzioni sono la somma del prodotto saggio degli elementi delle due matrici. Una matrice fa parte dei dati di input e l'altra matrice è un filtro utilizzato per estrarre le caratteristiche dall'immagine.
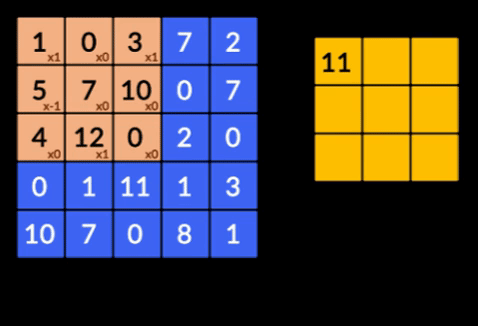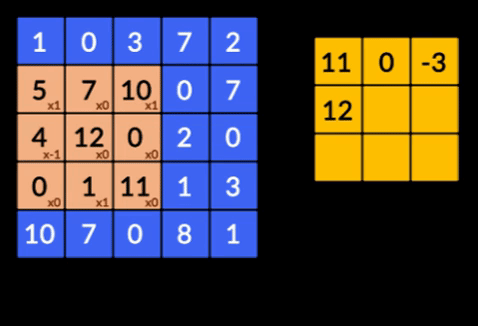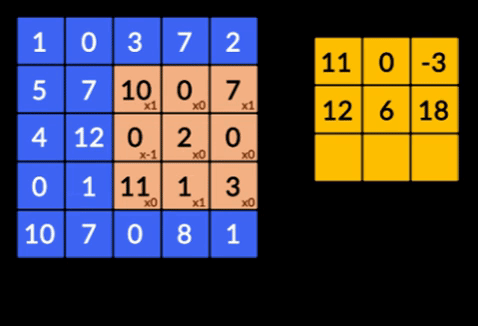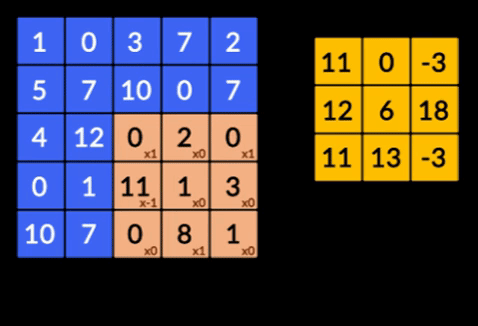
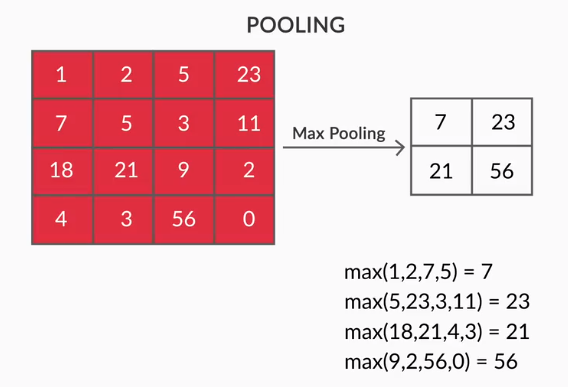
- Livelli di raggruppamento: l'aggregazione delle funzionalità estratte viene eseguita tramite il raggruppamento di livelli. Questi strati generalmente calcolano una statistica aggregata (max, media, ecc.) e rendono la rete invariante rispetto alle trasformazioni locali.
- Mappe delle caratteristiche: un neurone è CNN è fondamentalmente un filtro i cui pesi vengono appresi durante il suo allenamento. Ogni neurone osserva una particolare regione dell'input che è nota come campo ricettivo. Una Feature Map è una raccolta di tali neuroni che osservano diverse regioni dell'immagine con lo stesso peso. Tutti i neuroni in una mappa delle caratteristiche cercano di estrarre la stessa caratteristica ma da diverse regioni dell'immagine.
3. Reti neurali ricorrenti (RNN)
Le reti neurali ricorrenti sono progettate per gestire dati sequenziali. Per dati sequenziali si intendono i dati che hanno una qualche connessione con i dati precedenti come testo (sequenza di parole, frasi ecc.) o video (sequenza di immagini), voce ecc.

È molto importante capire la connessione tra queste entità sequenziali, altrimenti non avrebbe senso confondere l'intero paragrafo e cercare di trarne un significato. Gli RNN sono stati progettati per elaborare queste entità sequenziali. Un buon esempio di RNN in uso è la generazione automatica dei sottotitoli in YouTube. Non è altro che il riconoscimento vocale automatico implementato utilizzando gli RNN.
La principale differenza tra le normali reti neurali e le reti neurali ricorrenti è che i dati di input fluiscono lungo due dimensioni: tempo (lungo la lunghezza della sequenza per estrarne le caratteristiche) e profondità (strati neurali normali). Esistono diversi tipi di RNN e la loro struttura cambia di conseguenza.
- Many to One RNN: – In questa architettura, l'input fornito alla rete è una sequenza e l'output è una singola entità. Questa architettura viene utilizzata per affrontare problemi come la classificazione del sentimento o per prevedere il punteggio del sentimento dei dati di input (problema di regressione). Può anche essere utilizzato per classificare i video in determinate categorie.
- Many to Many RNN: – Sia l'input che l'output sono sequenze in questa architettura. Può essere ulteriormente classificato in base alla lunghezza dell'ingresso e dell'uscita.
- Stessa lunghezza: – La rete produce un output ad ogni timestep. C'è una corrispondenza uno a uno tra l'input e l'output ad ogni timestep. Questa architettura può essere utilizzata come parte del tagger vocale in cui ogni parola della sequenza nell'input viene contrassegnata con la sua parte del parlato come output ad ogni timestep.
- Lunghezza diversa: – In questo caso, la lunghezza dell'ingresso non è uguale alla lunghezza dell'uscita. Uno degli usi di questa architettura è la traduzione linguistica. La lunghezza di una frase in inglese può essere diversa dalla corrispondente frase hindi.
- One to Many RNN: – L'input qui è una singola entità mentre l'output è una sequenza. Questi tipi di reti neurali vengono utilizzati per attività come la generazione di musica, immagini, ecc.
- One to One RNN: – È una rete neurale tradizionale in cui l'input e l'output sono entità singole.
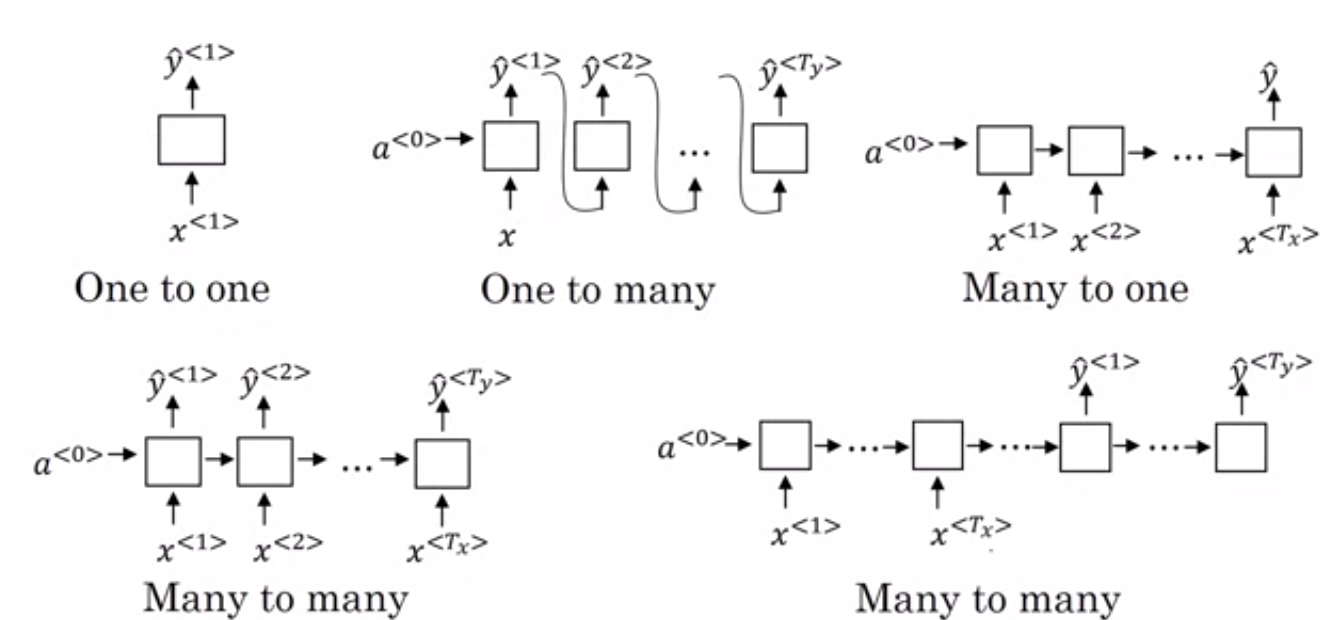
Tipi di RNN (Fonte: iq.opengenus.org)
4. Reti di memoria a lungo - breve termine (LSTM)
Uno degli svantaggi delle reti neurali ricorrenti è la scomparsa del problema del gradiente. Questo problema si incontra quando stiamo addestrando reti neurali con metodi di apprendimento basati su gradiente come la discesa del gradiente stocastico e la backpropagation. I gradienti della funzione di attivazione sono responsabili dell'aggiornamento dei pesi delle reti.
Diventano così piccoli che non cambia il peso delle reti neurali. Ciò impedisce alle reti neurali di allenarsi. Le RNN affrontano questo problema quando hanno difficoltà ad apprendere le dipendenze a lungo termine.
Le reti di memoria a lungo termine (LSTM) sono state progettate proprio per affrontare questo problema. LSTM è costituito da un'unità di memoria in grado di memorizzare le informazioni rilevanti per le informazioni precedenti. Anche le Gated Recurrent Units (GRU) sono una variante delle RNN che aiutano a risolvere i problemi di gradiente.
Entrambi utilizzano il meccanismo di gating per risolvere questo problema. GRU utilizza meno parametri di allenamento e quindi utilizza meno memoria rispetto a LSTM. Ciò consente ai GRU di addestrarsi più velocemente, ma LSTM fornisce risultati più accurati quando le sequenze di input sono lunghe.
5. Reti generative contraddittorio (GAN)
Generative Adversarial Networks (GAN) è un algoritmo di apprendimento non supervisionato che scopre e apprende automaticamente i modelli dai dati. Dopo aver appreso questi modelli, genera nuovi dati come output che hanno le stesse caratteristiche dell'input. Crea un modello che è diviso in due sottomodelli: generatore e discriminatore.
Il modello generatore cerca di generare nuove immagini dall'input mentre il ruolo del modello discriminatore è classificare se i dati sono un'immagine reale dal set di dati o dalle immagini generate artificialmente (immagini dal modello generato).
Il modello discriminatore agisce generalmente come un classificatore binario sotto forma di rete neurale convoluzionale. Con ogni iterazione, entrambi i modelli cercano di migliorare i propri risultati poiché l'obiettivo del modello generatore è ingannare il modello discriminatore nell'identificare l'immagine e l'obiettivo del discriminatore è identificare correttamente le immagini false.
6. Macchina di Boltzmann limitata (RBM)
Le Restricted Boltzmann Machine (RBM) sono reti neurali non deterministiche con capacità generative e apprendono la distribuzione di probabilità sull'input. Sono una forma ristretta di Boltzmann Machine, ristretta nei termini delle interconnessioni tra i nodi nello strato.
Questi coinvolgono solo due strati cioè strato visibile e strato nascosto. Non vi è alcun livello di output nell'RBM e gli strati sono completamente collegati tra loro. Gli RBM sono ora solennemente utilizzati poiché sono stati sostituiti dai GAN. È anche possibile mettere insieme più RBM per creare una nuova rete che può essere sintonizzata utilizzando la discesa del gradiente e la backpropagation come le altre reti neurali. Tali reti sono chiamate Deep Belief Networks.
Macchina Boltzmann limitata (fonte: media)
7. Trasformatori
I trasformatori sono un tipo di architettura di rete neurale progettata per la traduzione automatica neurale. Implicano un meccanismo di attenzione che si concentra su una parte delle informazioni fornite alla rete. Si compone di due parti: Encoder e Decoder.
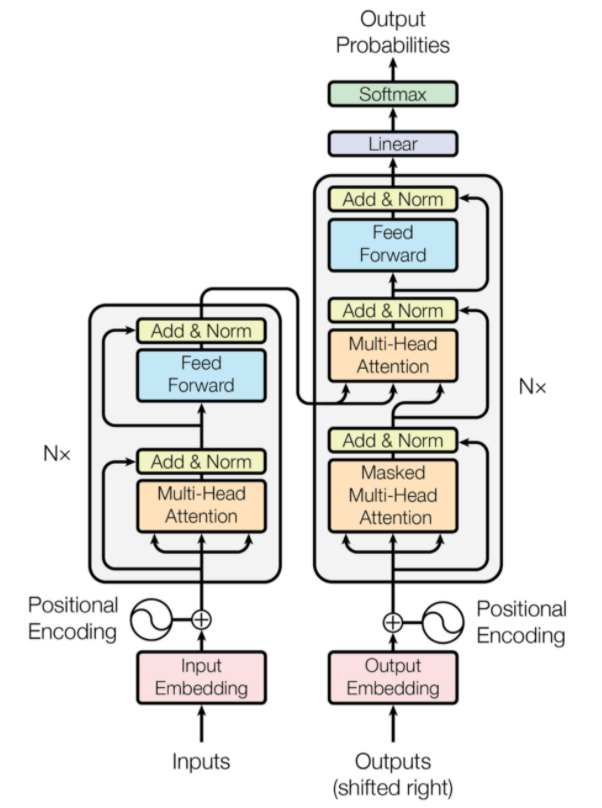
Architettura del trasformatore (Fonte: arxiv.org)
La parte sinistra della figura è l'Encoder e la parte destra è il Decoder. L'encoder e il decoder possono essere costituiti da più moduli che possono essere impilati uno sopra l'altro. Lo stesso è espresso da Nx nella figura. La funzione di ciascun livello del codificatore è di capire quali parti dell'input sono rilevanti l'una per l'altra e vengono definite codifiche.
Queste codifiche vengono quindi trasmesse al livello di codificatore successivo come input. Il livello del decodificatore prende queste codifiche e le elabora per generare la sequenza di output. Il meccanismo attento soppesa il significato di ogni altro input ed estrae informazioni da queste relazioni per prevedere la sequenza di output. Gli strati codificatore e decodificatore sono anche costituiti da strati feed forward che vengono utilizzati per l'ulteriore elaborazione delle uscite.
Leggi anche: Deep Learning vs Reti Neurali
Conclusione
L'articolo ha fornito una breve introduzione al dominio del Deep Learning, ai componenti utilizzati nelle reti neurali, all'idea degli algoritmi di deep learning, alle ipotesi fatte per semplificare le reti neurali, ecc. Questo articolo fornisce un elenco ristretto di algoritmi di deep learning in quanto esistono molti algoritmi diversi che vengono costantemente creati per superare i limiti degli algoritmi esistenti.
Gli algoritmi di Deep Learning hanno rivoluzionato il modo di elaborare video, immagini, testo ecc. e possono essere facilmente implementati importando i pacchetti richiesti. Infine, per tutti i Deep Learners, l'infinito è il limite.
Se sei interessato a saperne di più sulle tecniche di deep learning e machine learning, dai un'occhiata alla certificazione PG di IIIT-B e upGrad in Machine Learning e Deep Learning, progettata per i professionisti che lavorano e offre oltre 240 ore di formazione rigorosa, oltre 5 casi di studio & incarichi, status di Alumni IIIT-B e assistenza al lavoro con le migliori aziende.
Differenza tra CNN e ANN?
Le reti neurali artificiali (ANN) costruiscono strati di rete paralleli agli strati neurali umani: livelli decisionali di input, nascosti e di output. Le RNA sono percettive dei difetti e si aggiornano ristrutturandosi dopo un difetto. Le reti neurali convoluzionali (CNN) sono principalmente focalizzate sull'input di immagini. Nelle CNN, il primo livello estrae l'immagine grezza. Il livello successivo esegue il peering nelle informazioni trovate nel livello precedente. Il terzo livello identifica le caratteristiche dell'immagine e il livello finale riconosce l'immagine. Le CNN non richiedono descrizioni di input esplicite; Riconoscono i dati utilizzando caratteristiche spaziali. Sono altamente preferiti per le attività di riconoscimento visivo.
Il Deep Learning offre un vantaggio nell'Intelligenza Artificiale?
L'intelligenza artificiale (AI) ha reso la tecnologia più accurata e rappresentativa del mondo. Come parte del Machine Learning nell'IA, il Deep Learning può elaborare in modo efficiente grandi quantità di dati. Ha un approccio punto a punto per risolvere i problemi. Il Deep Learning ha creato sistemi efficienti e veloci, mentre i sistemi di Machine Learning hanno diversi passaggi per iniziare. Sebbene il Deep Learning richieda molto tempo di formazione, la sua reciprocità di test è istantanea. Il Deep Learning è innegabilmente parte integrante dell'Intelligenza Artificiale e ha contribuito a rilevare dati uditivi e visivi. Ha reso possibili dispositivi di assistente vocale automatizzati, veicoli e molte altre tecnologie.
Quali sono i limiti del Deep Learning?
Il deep learning ha fatto passi da gigante nell'interazione macchina-uomo e ha reso la tecnologia utile per l'umanità in molti modi. Ha ostacoli di formazione approfondita, requisiti di apparecchiature costose e prerequisiti di dati di grandi dimensioni. Fornisce soluzioni automatizzate, ma prende decisioni che non sono chiare fino a quando non viene eseguito il calcolo di numerosi algoritmi e reti neurali. Il percorso viene ricondotto ai nodi specifici, il che è quasi impossibile; L'apprendimento automatico ha un percorso diretto di tracciamento dei processi ed è preferibile. Il Deep Learning ha molti limiti, ma i suoi vantaggi li superano tutti.