
Deep-Learning-Algorithmus [Umfassender Leitfaden mit Beispielen]
Veröffentlicht: 2020-10-28Inhaltsverzeichnis
Einführung
Deep Learning ist eine Teilmenge des maschinellen Lernens, bei dem Algorithmen verwendet werden, die von der Anordnung und Funktionsweise des Gehirns inspiriert sind. So wie Neuronen aus menschlichen Gehirnen Informationen übertragen und beim Lernen von den Reaktoren in unserem Körper helfen, durchlaufen die Deep-Learning-Algorithmen in ähnlicher Weise verschiedene Schichten von neuronalen Netzwerkalgorithmen und lernen aus ihren Reaktionen.
Mit anderen Worten, Deep Learning verwendet Schichten von neuronalen Netzwerkalgorithmen, um Daten auf signifikanterer Ebene in Abhängigkeit von Roheingabedaten zu entdecken. Die Algorithmen des neuronalen Netzwerks entdecken die Datenmuster durch einen Prozess, der die Funktionsweise eines menschlichen Gehirns simuliert.
Neuronale Netze helfen beim Clustern der Datenpunkte aus einer großen Menge von Datenpunkten basierend auf den Ähnlichkeiten der Merkmale. Diese Systeme werden als künstliche neuronale Netze bezeichnet.
Da den Modellen immer mehr Daten zugeführt wurden, erwiesen sich Deep-Learning-Algorithmen als produktiver und lieferten bessere Ergebnisse als der Rest der Algorithmen. Deep-Learning-Algorithmen werden für verschiedene Probleme wie Bilderkennung, Spracherkennung, Betrugserkennung, Computer Vision usw. verwendet.
Komponenten des neuronalen Netzwerks
1. Netzwerktopologie – Netzwerktopologie bezieht sich auf die Struktur des neuronalen Netzwerks. Es umfasst die Anzahl der verborgenen Schichten im Netzwerk, die Anzahl der Neuronen in jeder Schicht, einschließlich der Eingabe- und Ausgabeschicht usw.
2. Input Layer – Input Layer ist der Einstiegspunkt des neuronalen Netzes. Die Anzahl der Neuronen in der Eingabeschicht sollte gleich der Anzahl der Attribute in den Eingabedaten sein.

3. Output Layer – Output Layer ist der Ausgangspunkt des neuronalen Netzes. Die Anzahl der Neuronen in der Ausgabeschicht sollte gleich der Anzahl der Klassen in der Zielvariablen sein (für Klassifizierungsproblem). Beim Regressionsproblem ist die Anzahl der Neuronen in der Ausgabeschicht 1, da die Ausgabe eine numerische Variable wäre.
4. Aktivierungsfunktionen – Aktivierungsfunktionen sind mathematische Gleichungen, die auf die Summe der gewichteten Eingaben eines Neurons angewendet werden. Es hilft bei der Bestimmung, ob das Neuron getriggert werden soll oder nicht. Es gibt viele Aktivierungsfunktionen wie Sigmoid-Funktion, Rectified Linear Unit (ReLU), Leaky ReLU, Hyperbolic Tangens, Softmax-Funktion usw.
5. Gewichte – Jeder Verbindung zwischen den Neuronen in den aufeinanderfolgenden Schichten ist ein Gewicht zugeordnet. Es zeigt die Bedeutung der Verbindung zwischen den Neuronen bei der Entdeckung eines Datenmusters, das bei der Vorhersage des Ergebnisses des neuronalen Netzwerks hilft. Je höher die Gewichtswerte, desto höher die Signifikanz. Es ist einer der Parameter, die das Netzwerk während seiner Trainingsphase lernt.
6. Vorurteile – Vorurteile helfen beim Verschieben der Aktivierungsfunktion nach links oder rechts, was für eine bessere Entscheidungsfindung entscheidend sein kann. Seine Rolle ist analog zu der Rolle eines Achsenabschnitts in der linearen Gleichung. Gewichtungen können die Steilheit der Aktivierungsfunktion erhöhen, dh sie geben an, wie schnell die Aktivierungsfunktion ausgelöst wird, während eine Vorspannung verwendet wird, um das Auslösen der Aktivierungsfunktion zu verzögern. Es ist der zweite Parameter, den das Netzwerk während seiner Trainingsphase lernt.
Verwandter Artikel: Die besten Deep-Learning-Techniken
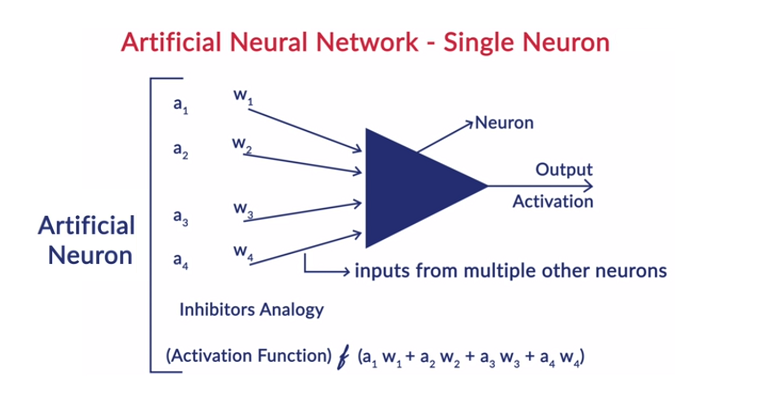
Allgemeine Funktionsweise eines Neurons
Deep Learning arbeitet mit künstlichen neuronalen Netzen (KNNs), um die Funktionsweise des menschlichen Gehirns nachzuahmen und auf menschliche Weise zu lernen. Neuronen in künstlichen neuronalen Netzen sind in Schichten angeordnet. Die erste und die letzte Schicht werden Eingabe- und Ausgabeschicht genannt. Die Schichten zwischen diesen beiden Schichten werden als verborgene Schichten bezeichnet.
Jedes Neuron in der Schicht besteht aus seiner eigenen Vorspannung, und jeder Verbindung zwischen den Neuronen von der vorherigen Schicht zur nächsten Schicht ist ein Gewicht zugeordnet. Jede Eingabe wird mit der der Verbindung zugeordneten Gewichtung multipliziert.
Die gewichtete Summe der Eingaben wird für jedes Neuron in den Schichten berechnet. Eine Aktivierungsfunktion wird auf diese gewichtete Summe der Eingaben angewendet und mit der Vorspannung des Neurons addiert, um die Ausgabe des Neurons zu erzeugen. Diese Ausgabe dient als Eingabe für die Verbindungen dieses Neurons in der nächsten Schicht und so weiter.
Dieser Vorgang wird Feedforwarding genannt. Das Ergebnis der Ausgabeschicht dient als endgültige Entscheidung des Modells. Das Training der neuronalen Netze erfolgt auf der Grundlage der Gewichtung jeder Verbindung zwischen den Neuronen und der Vorspannung jedes Neurons. Nachdem das endgültige Ergebnis vom Modell vorhergesagt wurde, berechnet es den Gesamtverlust, der eine Funktion der Gewichtungen und Verzerrungen ist.
Der Gesamtverlust ist im Grunde die Summe der Verluste aller Neuronen. Da das ultimative Ziel darin besteht, die Kostenfunktion zu minimieren, geht der Algorithmus zurück und ändert die Gewichte und die Bias entsprechend. Die Optimierung der Kostenfunktion kann mit der Gradientenabstiegsmethode erfolgen. Dieser Vorgang wird als Backpropagation bezeichnet.
Annahmen in den neuronalen Netzen
- Die Neuronen sind in Form von Schichten angeordnet und diese Schichten sind sequentiell angeordnet.
- Es gibt keine Kommunikation zwischen den Neuronen, die sich in derselben Schicht befinden.
- Der Eintrittspunkt neuronaler Netze ist die Eingabeschicht (erste Schicht) und der Austrittspunkt derselben ist die Ausgabeschicht (letzte Schicht).
- Jede Verbindung im neuronalen Netzwerk hat ein gewisses Gewicht und jedes Neuron hat eine damit verbundene Vorspannung.
- Dieselbe Aktivierungsfunktion wird auf alle Neuronen in einer bestimmten Schicht angewendet.
Lesen Sie: Deep-Learning-Projektideen
Verschiedene Deep-Learning-Algorithmen
1. Vollständig verbundenes neuronales Netzwerk
In Fully Connected Neural Network (FCNNs) ist jedes Neuron in einer Schicht mit jedem anderen Neuron in der nächsten Schicht verbunden. Diese Schichten werden aus demselben Grund als dichte Schichten bezeichnet. Diese Schichten sind rechenintensiv, da jedes Neuron mit allen anderen Neuronen verbunden ist.
Es wird bevorzugt, diesen Algorithmus zu verwenden, wenn die Anzahl der Neuronen in den Schichten geringer ist, da sonst viel Rechenleistung und Zeit erforderlich wäre, um die Operationen durchzuführen. Es kann aufgrund seiner vollständigen Konnektivität auch zu einer Überanpassung führen.
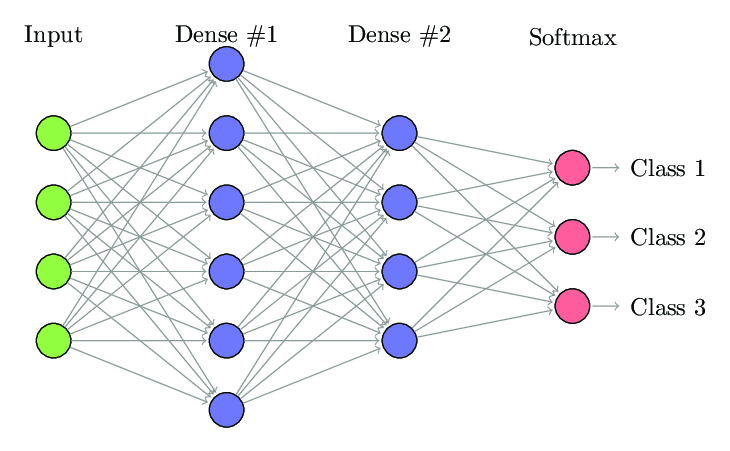
Vollständig verbundenes neuronales Netzwerk (Quelle: Researchgate.net)
2. Convolutional Neural Network (CNNs)
Das Convolutional Neural Network (CNNs) ist eine Klasse von neuronalen Netzwerken, die für die Arbeit mit visuellen Daten ausgelegt sind. dh Bilder und Videos. Daher wird es für viele Bildverarbeitungsaufgaben wie optische Zeichenerkennung (OCR), Objektlokalisierung usw. verwendet. CNNs können auch für Video-, Text- und Audioerkennung verwendet werden.
Die Bilder bestehen aus Pixeln, die die Intensität des Weiß im Bild bestimmen. Jedes Pixel eines Bildes ist ein Merkmal, das dem neuronalen Netzwerk zugeführt wird. Ein 128×128-Bild zeigt beispielsweise an, dass das Bild aus 16384 Pixeln oder Merkmalen besteht. Er wird als Vektor der Größe 16384 dem neuronalen Netz zugeführt. Für Farbbilder gibt es 3 Kanäle (jeweils einen – Rot, Blau, Grün). In diesem Fall würde dasselbe Bild in Farbe aus 128 x 128 x 3 Pixel bestehen.
Es gibt eine Hierarchie in den Schichten des CNN. Die erste Ebene versucht, die rohen Merkmale der Bilder wie horizontale oder vertikale Kanten zu extrahieren. Die zweiten Schichten extrahieren mehr Einblicke aus den Merkmalen, die von der ersten Schicht extrahiert werden. Die nachfolgenden Ebenen würden dann tiefer in die Besonderheiten eintauchen, um bestimmte Teile eines Bildes wie Haare, Haut, Nase usw. zu identifizieren. Schließlich würde die letzte Ebene das Eingabebild als Mensch, Katze, Hund usw. klassifizieren.
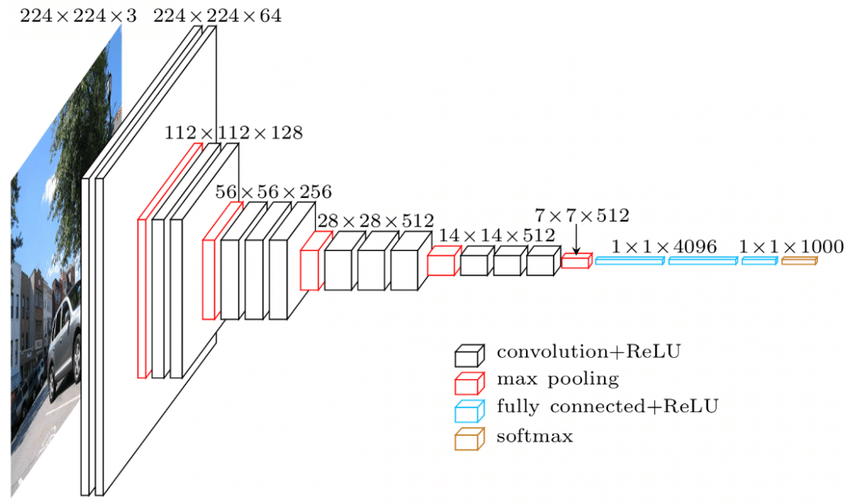
Quelle
VGGNet-Architektur – Eines der weit verbreiteten CNNs
Es gibt drei wichtige Terminologien in den CNNs:
- Faltungen – Faltungen sind die Summe der elementweisen Produkte der beiden Matrizen. Eine Matrix ist ein Teil der Eingabedaten und die andere Matrix ist ein Filter, der verwendet wird, um Merkmale aus dem Bild zu extrahieren.
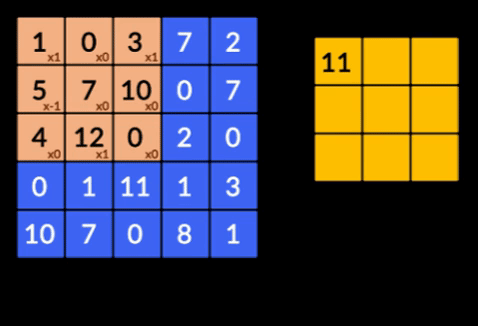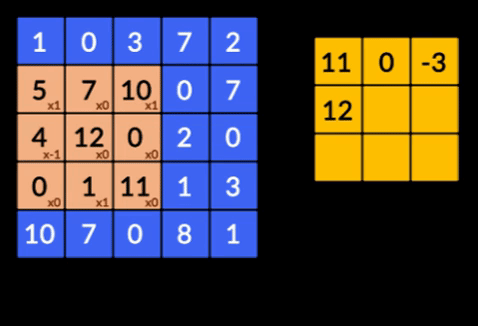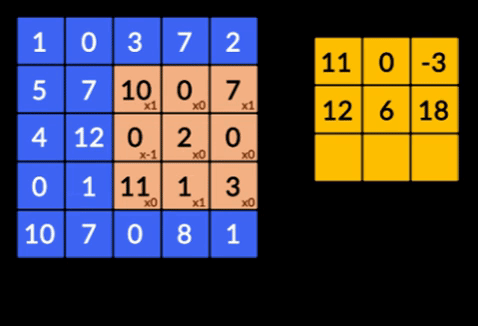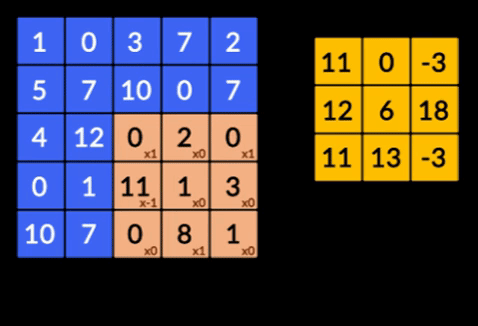
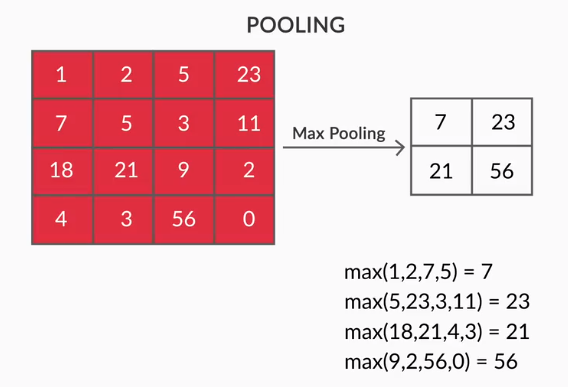
- Pooling Layers – Die Aggregation der extrahierten Features erfolgt durch Pooling Layers. Diese Schichten berechnen im Allgemeinen eine aggregierte Statistik (Maximum, Durchschnitt usw.) und machen das Netzwerk invariant gegenüber den lokalen Transformationen.
- Feature Maps – Ein Neuron ist CNN ist im Grunde ein Filter, dessen Gewichte während seines Trainings gelernt werden. Jedes Neuron betrachtet eine bestimmte Region in der Eingabe, die als sein rezeptives Feld bekannt ist. Eine Feature Map ist eine Sammlung solcher Neuronen, die verschiedene Bildregionen mit gleichen Gewichtungen betrachten. Alle Neuronen in einer Merkmalskarte versuchen, dasselbe Merkmal zu extrahieren, jedoch aus unterschiedlichen Bereichen des Bildes.
3. Wiederkehrende neuronale Netze (RNNs)
Wiederkehrende neuronale Netze sind für den Umgang mit sequentiellen Daten ausgelegt. Sequenzielle Daten sind Daten, die in irgendeiner Verbindung mit den vorherigen Daten stehen, wie z. B. Text (Folge von Wörtern, Sätzen usw.) oder Videos (Folge von Bildern), Sprache usw.

Es ist sehr wichtig, die Verbindung zwischen diesen sequentiellen Entitäten zu verstehen, sonst würde es keinen Sinn machen, den ganzen Absatz durcheinander zu bringen und zu versuchen, daraus eine Bedeutung abzuleiten. RNNs wurden entwickelt, um diese sequentiellen Entitäten zu verarbeiten. Ein gutes Beispiel für die Verwendung von RNNs ist die automatische Generierung von Untertiteln in YouTube. Es ist nichts anderes als eine automatische Spracherkennung, die mit RNNs implementiert wird.
Der Hauptunterschied zwischen normalen neuronalen Netzwerken und rekurrenten neuronalen Netzwerken besteht darin, dass die Eingabedaten entlang zweier Dimensionen fließen – Zeit (entlang der Länge der Sequenz, um Merkmale daraus zu extrahieren) und Tiefe (normale neuronale Schichten). Es gibt verschiedene Arten von RNNs und ihre Struktur ändert sich entsprechend.
- Many to One RNN: – In dieser Architektur ist die in das Netzwerk eingespeiste Eingabe eine Sequenz und die Ausgabe eine einzelne Entität. Diese Architektur wird verwendet, um Probleme wie die Stimmungsklassifizierung oder die Vorhersage des Stimmungswerts der Eingabedaten (Regressionsproblem) anzugehen. Es kann auch verwendet werden, um Videos in bestimmte Kategorien einzuordnen.
- Many to Many RNN: – Sowohl die Eingabe als auch die Ausgabe sind Sequenzen in dieser Architektur. Sie kann anhand der Länge der Ein- und Ausgabe weiter klassifiziert werden.
- Gleiche Länge: – Das Netzwerk erzeugt bei jedem Zeitschritt eine Ausgabe. Es gibt eine Eins-zu-Eins-Entsprechung zwischen der Eingabe und der Ausgabe in jedem Zeitschritt. Diese Architektur kann als Wortart-Tagger verwendet werden, bei dem jedes Wort der Sequenz in der Eingabe in jedem Zeitschritt mit seiner Wortart als Ausgabe markiert wird.
- Unterschiedliche Länge: – In diesem Fall ist die Länge des Eingangs ungleich der Länge des Ausgangs. Eine der Anwendungen dieser Architektur ist die Sprachübersetzung. Die Länge eines englischen Satzes kann sich von der des entsprechenden Hindi-Satzes unterscheiden.
- One to Many RNN: – Die Eingabe ist hier eine einzelne Entität, während die Ausgabe eine Sequenz ist. Solche neuronalen Netze werden für Aufgaben wie die Generierung von Musik, Bildern usw. verwendet.
- One to One RNN: – Es ist ein traditionelles neuronales Netzwerk, bei dem die Eingabe und Ausgabe einzelne Einheiten sind.
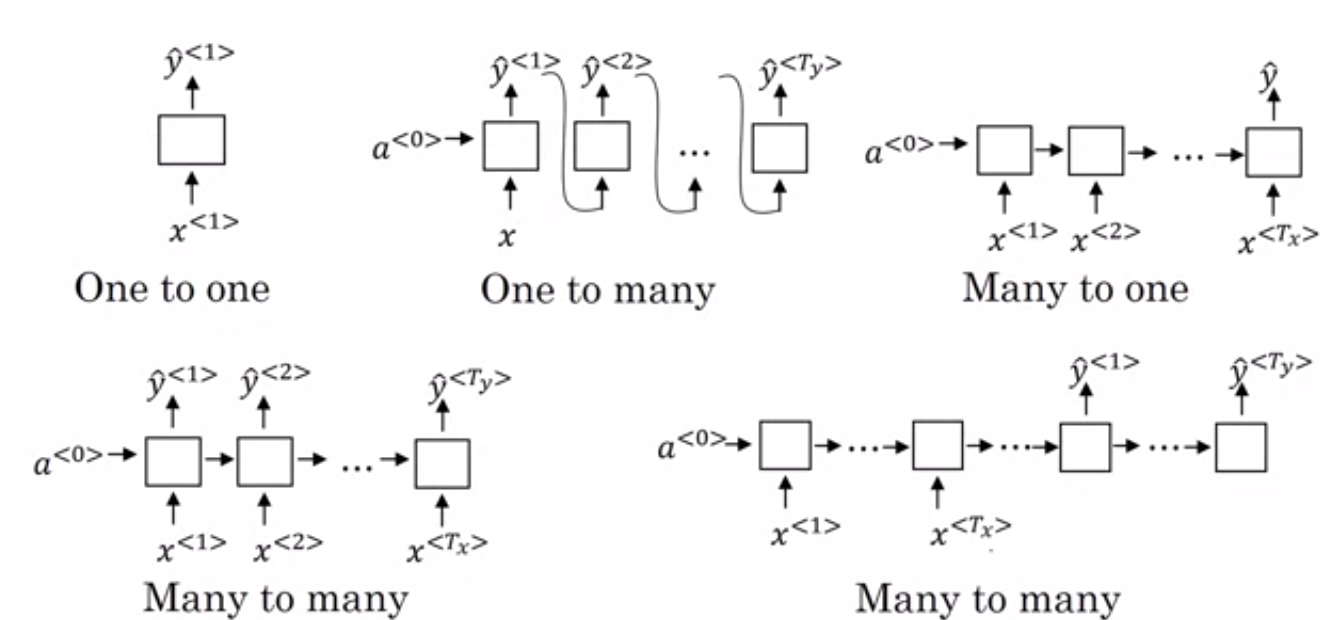
Arten von RNNs (Quelle: iq.opengenus.org)
4. Lang-Kurzzeit-Gedächtnisnetzwerke (LSTM)
Einer der Nachteile von Recurrent Neural Networks ist das Problem des verschwindenden Gradienten. Dieses Problem tritt auf, wenn wir neuronale Netze mit gradientenbasierten Lernmethoden wie stochastischem Gradientenabstieg und Backpropagation trainieren. Die Gradienten der Aktivierungsfunktion sind für die Aktualisierung der Gewichte der Netzwerke verantwortlich.
Sie werden so klein, dass es kaum Auswirkungen auf die Gewichte der neuronalen Netze hat, sich zu ändern. Dies verhindert, dass die neuronalen Netze trainieren. RNNs stehen vor diesem Problem, wenn sie Schwierigkeiten haben, langfristige Abhängigkeiten zu lernen.
Long – Short Term Memory Networks (LSTM) wurden entwickelt, um genau diesem Problem zu begegnen. LSTM besteht aus einer Speichereinheit, die die Informationen speichern kann, die für die vorherigen Informationen relevant sind. Gated Recurrent Units (GRUs) sind ebenfalls eine Variante von RNNs, die beim Verschwinden von Gradientenproblemen helfen.
Beide verwenden einen Gating-Mechanismus, um dieses Problem zu lösen. GRU verwendet weniger Trainingsparameter und damit weniger Speicher als LSTM. Dadurch können GRUs schneller trainieren, aber LSTM liefert genauere Ergebnisse, wenn die Eingabesequenzen lang sind.
5. Generative Adversarial Networks (GAN)
Generative Adversarial Networks (GAN) ist ein unüberwachter Lernalgorithmus, der automatisch die Muster aus den Daten entdeckt und lernt. Nach dem Lernen dieser Muster generiert es neue Daten als Ausgabe, die dieselben Eigenschaften wie die Eingabe haben. Es erstellt ein Modell, das in zwei Teilmodelle unterteilt ist – Generator und Diskriminator.
Das Generatormodell versucht, aus der Eingabe neue Bilder zu generieren, während die Rolle des Diskriminatormodells darin besteht, zu klassifizieren, ob es sich bei den Daten um ein echtes Bild aus dem Datensatz oder um künstlich generierte Bilder (Bilder aus dem generierten Modell) handelt.
Das Diskriminatormodell fungiert im Allgemeinen als binärer Klassifikator in Form eines konvolutionellen neuronalen Netzwerks. Mit jeder Iteration versuchen beide Modelle, ihre Ergebnisse zu verbessern, da das Ziel des Generatormodells darin besteht, das Diskriminatormodell bei der Identifizierung des Bildes zu täuschen, und das Ziel des Diskriminators darin besteht, die gefälschten Bilder korrekt zu identifizieren.
6. Restricted Boltzmann Machine (RBM)
Restricted Boltzmann Machine (RBM) sind nicht deterministische neuronale Netze mit generativen Fähigkeiten und lernen die Wahrscheinlichkeitsverteilung über die Eingabe. Sie sind eine eingeschränkte Form der Boltzmann-Maschine, die in Bezug auf die Verbindungen zwischen den Knoten in der Schicht eingeschränkt ist.
Diese beinhalten nur zwei Schichten, dh sichtbare Schicht und verborgene Schicht. Es gibt keine Ausgangsschicht im RBM und die Schichten sind vollständig miteinander verbunden. RBMs werden jetzt feierlich verwendet, da sie durch die GANs ersetzt wurden. Es können auch mehrere RBMs zusammengesetzt werden, um ein neues Netzwerk zu erstellen, das wie die anderen neuronalen Netzwerke unter Verwendung von Gradientenabstieg und Backpropagation abgestimmt werden kann. Solche Netzwerke werden als Deep Belief Networks bezeichnet.
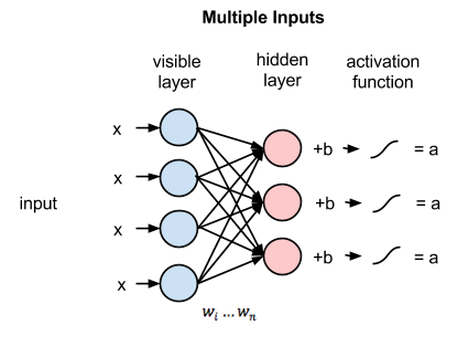
Eingeschränkte Boltzmann-Maschine (Quelle: Medium)
7. Transformatoren
Transformatoren sind eine Art neuronaler Netzwerkarchitektur, die für die neuronale maschinelle Übersetzung entwickelt wurden. Sie beinhalten einen Aufmerksamkeitsmechanismus, der sich auf einen Teil der Informationen konzentriert, die dem Netzwerk bereitgestellt werden. Es umfasst zwei Teile: Encoder und Decoder.
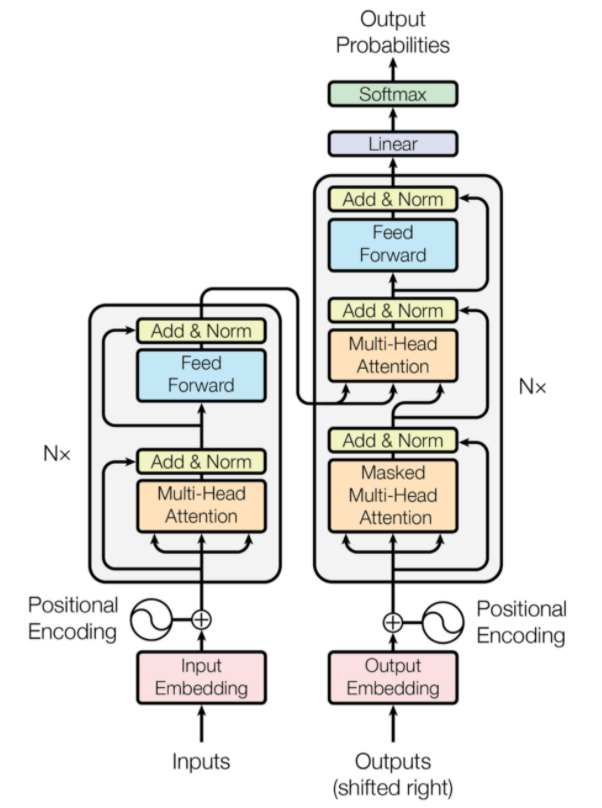
Transformer-Architektur (Quelle: arxiv.org)
Der linke Teil der Abbildung ist der Encoder und der rechte Teil ist der Decoder. Encoder und Decoder können aus mehreren Modulen bestehen, die übereinander gestapelt werden können. Dasselbe wird durch Nx in der Figur vermittelt. Die Funktion jeder Codierschicht besteht darin, herauszufinden, welche Teile der Eingabe füreinander relevant sind, die als Codierungen bezeichnet werden.
Diese Codierungen werden dann als Eingaben an die nächste Codierungsschicht weitergegeben. Die Decoderschicht nimmt diese Codierungen und verarbeitet sie, um die Ausgangssequenz zu erzeugen. Der aufmerksame Mechanismus wägt die Bedeutung jeder anderen Eingabe ab und extrahiert Informationen aus diesen Beziehungen, um die Ausgabesequenz vorherzusagen. Die Encoder- und Decoder-Schichten bestehen auch aus Feed-Forward-Schichten, die für die weitere Verarbeitung der Ausgaben verwendet werden.
Lesen Sie auch: Deep Learning vs. neuronale Netze
Fazit
Der Artikel gab eine kurze Einführung in die Deep-Learning-Domäne, die in den neuronalen Netzen verwendeten Komponenten, die Idee von Deep-Learning-Algorithmen, Annahmen zur Vereinfachung der neuronalen Netze usw. Dieser Artikel enthält eine eingeschränkte Liste von Deep-Learning-Algorithmen, soweit es sie gibt viele verschiedene Algorithmen, die ständig erstellt werden, um die Einschränkungen bestehender Algorithmen zu überwinden.
Deep-Learning-Algorithmen haben die Art und Weise der Verarbeitung von Videos, Bildern, Texten usw. revolutioniert und können durch Importieren der erforderlichen Pakete einfach implementiert werden. Schließlich ist für alle Deep Learner die Unendlichkeit die Grenze.
Wenn Sie mehr über Deep-Learning-Techniken und maschinelles Lernen erfahren möchten, sehen Sie sich die PG-Zertifizierung von IIIT-B & upGrad für maschinelles Lernen und Deep Learning an, die für Berufstätige konzipiert ist und mehr als 240 Stunden strenge Schulungen und mehr als 5 Fallstudien bietet & Aufgaben, IIIT-B Alumni-Status & Jobassistenz bei Top-Firmen.
Unterschied zwischen CNN und ANN?
Künstliche neuronale Netze (KNNs) konstruieren Netzwerkschichten parallel zu den menschlichen neuronalen Schichten: Eingangs-, verborgene und Ausgangsentscheidungsschichten. ANNs nehmen Fehler wahr und aktualisieren sich selbst, indem sie sich nach einem Mangel neu strukturieren. Convolutional Neural Networks (CNNs) sind hauptsächlich auf die Bildeingabe ausgerichtet. In CNNs extrahiert die erste Schicht das Rohbild. Die nächste Schicht prüft die Informationen, die in der vorherigen Schicht gefunden wurden. Die dritte Schicht identifiziert Merkmale des Bildes und die letzte Schicht erkennt das Bild. CNNs erfordern keine expliziten Eingabebeschreibungen; Sie erkennen Daten anhand räumlicher Merkmale. Sie werden für visuelle Erkennungsaufgaben stark bevorzugt.
Bietet Deep Learning einen Vorteil in der künstlichen Intelligenz?
Künstliche Intelligenz (KI) hat die Technologie genauer und repräsentativer für die Welt gemacht. Als Teil des maschinellen Lernens in der KI kann Deep Learning große Datenmengen effizient verarbeiten. Es hat einen Punkt-zu-Punkt-Ansatz zur Lösung von Problemen. Deep Learning hat effiziente und schnelle Systeme geschaffen, während Machine Learning-Systeme mehrere Schritte für den Einstieg haben. Obwohl Deep Learning viel Trainingszeit benötigt, erfolgt die Testreziprozität sofort. Deep Learning ist unbestreitbar ein fester Bestandteil der künstlichen Intelligenz und hat dazu beigetragen, auditive und visuelle Daten zu erkennen. Es hat automatisierte Sprachassistenten, Fahrzeuge und viele andere Technologien ermöglicht.
Was sind die Grenzen von Deep Learning?
Deep Learning hat Fortschritte in der Maschine-Mensch-Interaktion gemacht und Technologie in vielerlei Hinsicht für die Menschheit nutzbar gemacht. Es hat Hürden in Form von umfangreichem Training, teuren Ausrüstungsanforderungen und großen Datenvoraussetzungen. Es bietet automatisierte Lösungen, trifft aber Entscheidungen, die erst nach der Berechnung zahlreicher Algorithmen und neuronaler Netze klar sind. Der Pfad wird zu den spezifischen Knoten zurückverfolgt, was fast unmöglich ist; Maschinelles Lernen hat einen direkten Weg zur Verfolgung von Prozessen und ist vorzuziehen. Deep Learning hat viele Einschränkungen, aber seine Vorteile überwiegen sie alle.