
Recurrent Neural Network ใน Python: Ultimate Guide for Beginners
เผยแพร่แล้ว: 2020-04-27เมื่อคุณต้องการประมวลผลตามลำดับ เช่น ราคาหุ้นรายวัน การวัดเซ็นเซอร์ ฯลฯ ในโปรแกรม คุณต้องมีโครงข่ายประสาทเทียมแบบเกิดซ้ำ (RNN)
RNN เป็นโครงข่ายประสาทชนิดหนึ่งที่เอาต์พุตจากขั้นตอนเดียวถูกถ่ายโอนเป็นอินพุตไปยังขั้นตอนใหม่ ในระบบประสาททั่วไป แหล่งข้อมูลและเอาต์พุตทั้งหมดเป็นอิสระจากกัน อย่างไรก็ตาม ในกรณีเช่นเมื่อจำเป็นต้องคาดการณ์นิพจน์ต่อไปนี้ของประโยค จำเป็นต้องใช้คำก่อนหน้า ดังนั้นจึงมีความจำเป็นต้องจำคำในอดีต
นี่คือที่ที่ RNN เข้ามาในรูปภาพ มันสร้างเลเยอร์ที่ซ่อนอยู่เพื่อแก้ปัญหาเหล่านี้ องค์ประกอบพื้นฐานและสำคัญที่สุดของ RNN คือสถานะที่ซ่อนอยู่ ซึ่งจะจดจำข้อมูลบางอย่างเกี่ยวกับลำดับ
RNNs ได้ให้ผลลัพธ์ที่ถูกต้องแม่นยำในแอปพลิเคชันทั่วไปส่วนใหญ่: เนื่องจากความสามารถในการจัดการข้อความอย่างมีประสิทธิภาพ RNN จึงมักใช้ในงานการประมวลผลภาษาธรรมชาติ (NLP)
- การรู้จำเสียง
- เครื่องแปลภาษา
- ดนตรีประกอบ
- การรู้จำลายมือ
- การเรียนรู้ไวยากรณ์
นี่คือเหตุผลที่ RNN ได้รับความนิยมอย่างมากในพื้นที่การเรียนรู้เชิงลึก
ตอนนี้เรามาดูความจำเป็นของโครงข่ายประสาทเทียมใน Python
รับใบรับรองการเรียนรู้ของเครื่องออนไลน์จากมหาวิทยาลัยชั้นนำของโลก – ปริญญาโท โปรแกรม Executive Post Graduate และหลักสูตรประกาศนียบัตรขั้นสูงใน ML & AI เพื่อติดตามอาชีพของคุณอย่างรวดเร็ว
สารบัญ
Need for RNNs ใน Python คืออะไร?
เพื่อตอบคำถามนี้ ก่อนอื่นเราต้องแก้ไขปัญหาที่เกี่ยวข้องกับ Convolution Neural Network (CNN) หรือที่เรียกว่า vanilla neural nets
ปัญหาหลักของ CNN คือสามารถทำงานได้เฉพาะขนาดที่กำหนดไว้ล่วงหน้าเท่านั้น เช่น หากยอมรับอินพุตที่มีขนาดคงที่ ก็จะให้เอาต์พุตที่มีขนาดคงที่ด้วย
ในขณะที่ RNNs ปัญหานี้ได้รับการดูแลอย่างง่ายดาย RNN ช่วยให้นักพัฒนาสามารถทำงานกับลำดับความยาวผันแปรได้สำหรับทั้งอินพุตและเอาต์พุต
ด้านล่างนี้เป็นภาพประกอบว่า RNN มีลักษณะอย่างไร:
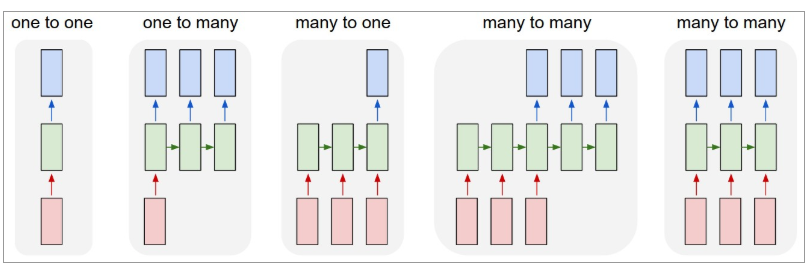
ที่มา: Andrej Karpathy
ในที่นี้ สีแดงหมายถึงอินพุต RNN สีเขียว และเอาต์พุตสีน้ำเงิน
มาทำความเข้าใจกันอย่างละเอียด
ตัวต่อตัว : สิ่งเหล่านี้เรียกอีกอย่างว่าโครงข่ายประสาทธรรมดาหรือวานิลลา โดยทำงานกับขนาดอินพุตคงที่ไปจนถึงขนาดเอาต์พุตคงที่และไม่ขึ้นกับอินพุตก่อนหน้า
ตัวอย่าง : การจำแนกรูปภาพ
One-to-many : แม้ว่าข้อมูลที่เป็นอินพุตจะมีขนาดคงที่ เอาต์พุตจะเป็นลำดับของข้อมูล
ตัวอย่าง : คำบรรยายภาพ (รูปภาพคืออินพุต และเอาต์พุตคือชุดคำ)
หลายต่อหนึ่ง : อินพุตคือลำดับของข้อมูลและเอาต์พุตมีขนาดคงที่
ตัวอย่าง : การวิเคราะห์ความรู้สึก (อินพุตคือชุดของคำและผลลัพธ์จะบอกว่าชุดของคำสะท้อนถึงความรู้สึกเชิงบวกหรือเชิงลบ)
Many-to-many : อินพุตคือลำดับของข้อมูลและเอาต์พุตคือลำดับของข้อมูล
ตัวอย่าง : เครื่องแปลภาษา (RNN อ่านประโยคภาษาอังกฤษและให้ผลลัพธ์ของประโยคในภาษาที่ต้องการ)
การประมวลผลลำดับที่มีความยาวแปรผันทำให้ RNN มีประโยชน์มาก โดยใช้วิธีดังนี้:
- การ แปล ด้วยคอมพิวเตอร์ : ตัวอย่างที่ดีที่สุดคือ Google Translate ใช้งานได้กับ RNN แบบหลายต่อหลายรายการ อย่างที่คุณทราบ ข้อความต้นฉบับจะถูกป้อนลงใน RNN ซึ่งจะทำให้ได้ข้อความที่แปลแล้ว
- การ วิเคราะห์ความคิดเห็น : คุณทราบหรือไม่ว่า Google แยกบทวิจารณ์เชิงลบออกจากบทวิจารณ์เชิงบวกได้อย่างไร ทำได้โดย RNN แบบหลายต่อหนึ่ง เมื่อข้อความถูกป้อนเข้าสู่ RNN จะให้ผลลัพธ์ซึ่งสะท้อนถึงคลาสที่อินพุตอยู่
ตอนนี้เรามาดูกันว่า RNN ทำงานอย่างไร
RNN ทำงานอย่างไร
เป็นการดีที่สุดที่จะเข้าใจการทำงานของโครงข่ายประสาทเทียมที่เกิดซ้ำใน Python โดยดูตัวอย่าง
สมมติว่ามีเครือข่ายที่ลึกกว่าซึ่งประกอบด้วยเลเยอร์เอาต์พุตหนึ่งเลเยอร์ เลเยอร์ที่ซ่อนอยู่ 3 เลเยอร์ และเลเยอร์อินพุต 1 เลเยอร์
เช่นเดียวกับที่เป็นกับโครงข่ายประสาทเทียมอื่นๆ ในกรณีนี้ แต่ละเลเยอร์ที่ซ่อนอยู่จะมาพร้อมกับชุดน้ำหนักและอคติของตัวเอง
เพื่อประโยชน์ของตัวอย่างนี้ ให้พิจารณาว่าน้ำหนักและอคติสำหรับเลเยอร์ 1 คือ (w1, b1), เลเยอร์ 2 คือ (w2, b2) และเลเยอร์ 3 คือ (w3, b3) ทั้งสามชั้นนี้ไม่ขึ้นกับแต่ละอื่น ๆ และจำผลลัพธ์ก่อนหน้านี้ไม่ได้
นี่คือสิ่งที่ RNN จะทำ:
- มันจะแปลงการเปิดใช้งานที่เป็นอิสระให้เป็นอิสระโดยทำให้เลเยอร์ทั้งหมดมีน้ำหนักและอคติเหมือนกัน ในทางกลับกัน จะลดความซับซ้อนของการเพิ่มพารามิเตอร์และจดจำผลลัพธ์ก่อนหน้าแต่ละรายการโดยให้เอาต์พุตเป็นอินพุตไปยังเลเยอร์ที่ซ่อนอยู่ถัดไป
- ดังนั้น ทั้งสามเลเยอร์จะพันกันเป็นเลเยอร์ที่เกิดซ้ำเดียวเพื่อให้มีน้ำหนักและอคติเหมือนกัน
- ในการคำนวณสถานะปัจจุบัน คุณสามารถใช้สูตรต่อไปนี้:
ที่ไหน,
= สถานะปัจจุบัน

= สถานะก่อนหน้า
= สถานะอินพุต
- ในการใช้ฟังก์ชันการเปิดใช้งาน (tanh) ให้ใช้สูตรต่อไปนี้:
ที่ไหน,
= น้ำหนักที่เซลล์ประสาทกำเริบ
= น้ำหนักที่เซลล์ประสาทอินพุต
- ในการคำนวณผลลัพธ์ ให้ใช้สูตรต่อไปนี้:
ที่ไหน,
= ผลลัพธ์
= น้ำหนักที่ชั้นเอาต์พุต
ต่อไปนี้เป็นคำอธิบายทีละขั้นตอนเกี่ยวกับวิธีการฝึกอบรม RNN
- ในครั้งเดียว อินพุตจะถูกส่งไปยังเครือข่าย
- ตอนนี้ คุณต้องคำนวณสถานะปัจจุบันโดยใช้ชุดอินพุตปัจจุบันและสถานะก่อนหน้า
- กระแสจะกลายเป็นขั้นตอนต่อไปของเวลา
- คุณสามารถทำตามขั้นตอนต่างๆ ได้มากเท่าที่ต้องการ และรวมข้อมูลจากสถานะก่อนหน้าทั้งหมด
- ทันทีที่ขั้นตอนเวลาทั้งหมดเสร็จสิ้น ให้ใช้สถานะปัจจุบันสุดท้ายเพื่อคำนวณผลลัพธ์สุดท้าย
- เปรียบเทียบผลลัพธ์นี้กับผลลัพธ์จริง เช่น ผลลัพธ์เป้าหมายและข้อผิดพลาดระหว่างทั้งสอง
- เผยแพร่ข้อผิดพลาดกลับไปที่เครือข่ายและอัปเดตน้ำหนักเพื่อฝึก RNN
บทสรุป
โดยสรุป ก่อนอื่น ฉันต้องการจะชี้ให้เห็นถึงข้อดีของ Recurring Neural Network ใน Python:
- RNN สามารถจดจำข้อมูลทั้งหมดที่ได้รับ นี่คือลักษณะเฉพาะที่ใช้มากที่สุดในการคาดการณ์อนุกรมเนื่องจากสามารถจดจำอินพุตก่อนหน้าได้
- ใน RNN สามารถใช้ฟังก์ชันการเปลี่ยนแปลงเดียวกันกับพารามิเตอร์เดียวกันในทุกขั้นตอนของเวลา
จำเป็นต้องเข้าใจว่าโครงข่ายประสาทเทียมที่เกิดซ้ำใน Python ไม่มีความเข้าใจภาษา เป็นเครื่องจดจำรูปแบบขั้นสูงอย่างเพียงพอ ไม่ว่าในกรณีใด RNN จะทำการคาดการณ์ขึ้นอยู่กับการเรียงลำดับของส่วนประกอบในลำดับ ซึ่งไม่เหมือนกับวิธีการต่างๆ เช่น Markov chains หรือการวิเคราะห์ความถี่
โดยพื้นฐานแล้ว ถ้าคุณบอกว่าผู้คนเป็นเพียงเครื่องจดจำรูปแบบที่ไม่ธรรมดา และในลักษณะนี้ ระบบประสาทที่เกิดซ้ำก็ทำหน้าที่เหมือนเครื่องจักรของมนุษย์
การใช้ RNN ไปไกลกว่าการสร้างเนื้อหาไปจนถึงการแปลด้วยคอมพิวเตอร์ คำบรรยายภาพ และการระบุผู้แต่ง แม้ว่า RNNs จะไม่สามารถแทนที่มนุษย์ได้ แต่ก็เป็นไปได้ว่าด้วยข้อมูลการฝึกอบรมที่มากขึ้นและแบบจำลองที่ใหญ่กว่า ระบบประสาทจะมีตัวเลือกในการรวมบทคัดย่อสิทธิบัตรใหม่ ๆ ที่สมเหตุสมผล
นอกจากนี้ หากคุณสนใจที่จะเรียนรู้เพิ่มเติมเกี่ยวกับแมชชีนเลิร์นนิง โปรดดูที่ IIIT-B & upGrad's Executive PG Program ใน Machine Learning & AI ซึ่งออกแบบมาสำหรับมืออาชีพที่ทำงานและมีการฝึกอบรมอย่างเข้มงวดมากกว่า 450 ชั่วโมง กรณีศึกษาและการมอบหมายมากกว่า 30 รายการ , สถานะศิษย์เก่า IIIT-B, 5+ โครงการหลักที่ใช้งานได้จริง & ความช่วยเหลือด้านงานกับบริษัทชั้นนำ
CNN เร็วกว่า RNN หรือไม่
หากเราดูเวลาคำนวณของทั้ง CNN และ RNN พบว่า CNN นั้นเร็วมาก (~ 5x) เมื่อเทียบกับ RNN ให้เราพยายามทำความเข้าใจสิ่งนี้ให้ดีขึ้นด้วยตัวอย่าง
หากรีวิวร้านอาหารคือ: 'บริการช้าอย่างไม่น่าเชื่อ และฉันค่อนข้างผิดหวังกับร้านอาหารนี้มาก คุณภาพของอาหารก็ปานกลางเช่นกัน' มีข้อมูลตามลำดับอยู่ในคำสั่ง ซึ่งคุณอาจพยายามค้นหาว่าความรู้สึกนั้นดีหรือไม่ดี โมเดล CNN จะทำให้การคำนวณเร็วขึ้นที่นี่ เนื่องจากจะดูเฉพาะบางวลี เช่น 'ช้าอย่างไม่น่าเชื่อ' 'ปานกลาง' และ 'ผิดหวัง' ที่นี่ RNN อาจทำให้คุณสับสนโดยดูจากพารามิเตอร์อื่นๆ หลายตัว CNN เป็นรูปแบบที่เรียบง่าย ซึ่งทำให้มีประสิทธิภาพมากกว่า RNN
แอปพลิเคชั่นของ RNN คืออะไร?
RNN เป็นโมเดลแมชชีนเลิร์นนิงที่ค่อนข้างทรงพลังซึ่งถูกใช้ในหลายพื้นที่ เป้าหมายหลักของ RNN คือการประมวลผลข้อมูลตามลำดับที่มีให้ ความพร้อมใช้งานของข้อมูลตามลำดับพบได้ในโดเมนต่างๆ แอปพลิเคชันบางตัวในโดเมนต่างๆ ได้แก่ การแปลด้วยเครื่อง การรู้จำเสียง การวิเคราะห์คอลเซ็นเตอร์ ปัญหาการคาดการณ์ การสรุปข้อความ การติดแท็กวิดีโอ การตรวจจับใบหน้า การจดจำภาพ แอปพลิเคชัน OCR และการแต่งเพลง
อะไรคือความแตกต่างที่สำคัญระหว่าง RNN และ CNN?
RNN มีประโยชน์สำหรับการวิเคราะห์ข้อมูลตามลำดับและชั่วคราว เช่น วิดีโอหรือข้อความ ในทางกลับกัน CNN มีประโยชน์ในการแก้ปัญหาที่เกี่ยวข้องกับข้อมูลเชิงพื้นที่ เช่น รูปภาพ ใน RNN ขนาดของอินพุตและเอาต์พุตอาจแตกต่างกันไป ในขณะที่ใน CNN จะมีขนาดคงที่สำหรับอินพุตและเอาต์พุตที่เป็นผลลัพธ์ กรณีการใช้งาน RNN บางกรณี ได้แก่ การแปลภาษาด้วยเครื่อง การวิเคราะห์คำพูด การวิเคราะห์ความรู้สึก และปัญหาการทำนาย ในขณะที่ CNN มีประโยชน์ในการวิเคราะห์ทางการแพทย์ การจัดประเภท และการจดจำใบหน้า