
Rețeaua neuronală recurentă în Python: Ghid definitiv pentru începători
Publicat: 2020-04-27Când trebuie să procesați secvențe – prețurile zilnice ale acțiunilor, măsurătorile senzorilor etc. – într-un program, aveți nevoie de o rețea neuronală recurentă (RNN).
RNN-urile sunt un fel de rețea neuronală în care ieșirea dintr-un pas este transferată ca intrare în noua etapă. În sistemele neuronale convenționale, toate sursele și ieșirile de date sunt autonome unele față de altele. Cu toate acestea, în cazuri cum ar fi atunci când este necesară anticiparea următoarei expresii a unei propoziții, sunt necesare cuvintele anterioare și, în consecință, este nevoie să ne amintim cuvintele trecute.
Aici intervine RNN. A creat un strat ascuns pentru a rezolva aceste probleme. Elementul fundamental și cel mai semnificativ al RNN este starea ascunsă, care reține unele date despre o secvență.
RNN-urile au generat rezultate precise în unele dintre cele mai comune aplicații din lumea reală: Datorită capacității lor de a gestiona textul în mod eficient, RNN-urile sunt în general utilizate în sarcinile de procesare a limbajului natural (NLP).
- Recunoaștere a vorbirii
- Traducere automată
- Compoziție muzicală
- Scris de mana recunoscut
- Învățarea gramaticii
Acesta este motivul pentru care RNN-urile au câștigat o popularitate imensă în spațiul de învățare profundă.
Acum să vedem necesitatea rețelelor neuronale recurente în Python.
Obțineți certificare de învățare automată online de la cele mai bune universități din lume – masterat, programe executive postuniversitare și program de certificat avansat în ML și AI pentru a vă accelera cariera.
Cuprins
Care este nevoie de RNN-uri în Python?
Pentru a răspunde la această întrebare, trebuie mai întâi să abordăm problemele asociate cu o rețea neuronală de convoluție (CNN), numită și rețele neuronale vanilie.
Problema majoră cu CNN-urile este că pot funcționa doar pentru dimensiuni predefinite, adică dacă acceptă intrări de dimensiune fixă, oferă și ieșiri de dimensiune fixă.
În timp ce, cu RNN, această problemă este ușor de rezolvat. RNN-urile permit dezvoltatorilor să lucreze cu secvențe de lungime variabilă atât pentru intrări, cât și pentru ieșiri.
Mai jos este o ilustrare a cum arată RNN-urile:
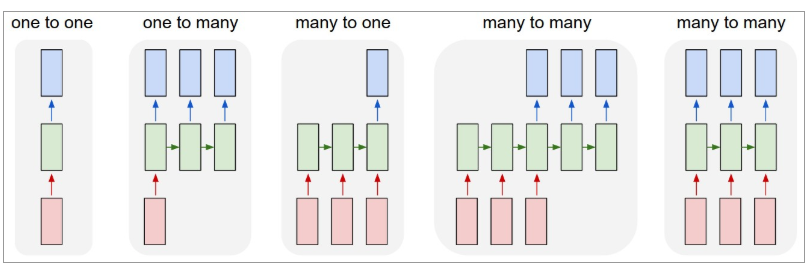
Sursa: Andrej Karpathy
Aici, culoarea roșie denotă intrările, RNN-urile verzi și ieșirile albastre.
Să înțelegem fiecare în detaliu.
One-to-one : Acestea sunt numite și rețele neuronale simple sau vanilie. Acestea funcționează cu dimensiunea de intrare fixă la dimensiunea de ieșire fixă și sunt independente de intrările anterioare.
Exemplu : Clasificarea imaginilor.
One-to-many : în timp ce informațiile de intrare sunt de dimensiune fixă, rezultatul este o secvență de date.
Exemplu : Subtitrărea imaginii (imaginea este introdusă, iar ieșirea este un set de cuvinte).
Multi-la-unu : intrarea este o secvență de informații, iar ieșirea are o dimensiune fixă.
Exemplu : Analiza sentimentelor (intrarea este un set de cuvinte, iar ieșirea indică dacă setul de cuvinte reflectă un sentiment pozitiv sau negativ).
Many-to-many : intrarea este o secvență de informații, iar ieșirea este o secvență de date.
Exemplu : Traducere automată (RNN citește o propoziție în engleză și oferă o ieșire a propoziției în limba dorită).
Procesarea secvenței cu lungimi variabile face RNN-urile atât de utile. Iată cum:
- Traducere automată : cel mai bun exemplu în acest sens este Google Translate. Funcționează pe mai multe-la-multe RNN. După cum știți, textul original este introdus într-un RNN, care produce text tradus.
- Analiza sentimentelor : Știți cum Google separă recenziile negative de cele pozitive? Este realizat printr-un RNN multi-la-unu. Când textul este introdus în RNN, acesta oferă rezultatul, reflectând clasa în care se află intrarea.
Acum să vedem cum funcționează RNN-urile.
Cum funcționează RNN-urile?
Cel mai bine este să înțelegeți funcționarea unei rețele neuronale recurente în Python, uitându-vă la un exemplu.
Să presupunem că există o rețea mai profundă care conține un strat de ieșire, trei straturi ascunse și un strat de intrare.
Așa cum este cu alte rețele neuronale, și în acest caz, fiecare strat ascuns va veni cu propriul său set de greutăți și părtiniri.
De dragul acestui exemplu, să considerăm că ponderile și prejudecățile pentru stratul 1 sunt (w1, b1), stratul 2 sunt (w2, b2), iar stratul 3 sunt (w3, b3). Aceste trei straturi sunt independente unele de altele și nu-și amintesc rezultatele anterioare.
Acum, iată ce va face RNN:
- Va converti activările independente în altele dependente făcând ca toate straturile să conțină aceleași greutăți și părtiniri. Acest lucru va reduce, la rândul său, complexitatea creșterii parametrilor și reamintirea fiecăruia dintre rezultatele anterioare, oferind rezultatul ca intrare pentru următorul strat ascuns.
- Astfel, toate cele trei straturi vor fi împletite într-un singur strat recurent pentru a conține aceleași greutăți și părtiniri.
- Pentru a calcula starea curentă, puteți utiliza următoarea formulă:
Unde,

= starea curentă
= starea anterioară
= starea de intrare
- Pentru a aplica funcția de activare (tanh), utilizați următoarea formulă:
Unde,
= greutatea la neuronul recurent
= greutatea la neuronul de intrare
- Pentru a calcula ieșirea, utilizați următoarea formulă:
Unde,
= ieșire
= greutatea la stratul de ieșire
Iată o explicație pas cu pas a modului în care un RNN poate fi antrenat.
- La un moment dat, intrarea este dată rețelei.
- Acum, trebuie să calculați starea sa actuală folosind setul de intrare curent și starea anterioară.
- Curentul va deveni pentru următorul pas al timpului.
- Poți parcurge câte pași de timp vrei și combina datele din toate stările anterioare.
- De îndată ce toți pașii de timp sunt finalizați, utilizați starea curentă finală pentru a calcula rezultatul final.
- Comparați această ieșire cu ieșirea reală, adică ieșirea țintă și eroarea dintre cele două.
- Propagați eroarea înapoi în rețea și actualizați ponderile pentru a antrena RNN.
Concluzie
Pentru a încheia, aș dori mai întâi să subliniez avantajele unei rețele neuronale recurente în Python:
- Un RNN își poate aminti toate informațiile pe care le primește. Aceasta este caracteristica care este cea mai utilizată în predicția în serie, deoarece își poate aminti intrările anterioare.
- În RNN, aceeași funcție de tranziție cu aceiași parametri poate fi utilizată la fiecare pas de timp.
Este esențial să înțelegem că rețeaua neuronală recurentă din Python nu înțelege limbajul. Este în mod adecvat o mașină avansată de recunoaștere a modelelor. În orice caz, spre deosebire de metode precum lanțurile Markov sau analiza frecvenței, RNN face predicțiile dependente de ordonarea componentelor din secvență.
Practic, dacă spui că oamenii sunt doar niște mașini extraordinare de recunoaștere a modelelor și, în acest fel, sistemul neuronal recurent acționează ca o mașină-om.
Utilizările RNN-urilor merg cu mult dincolo de generarea de conținut până la traducerea automată, subtitrărea imaginilor și identificarea autorului. Chiar dacă RNN-urile nu pot înlocui oamenii, este posibil ca, cu mai multe informații de instruire și un model mai mare, un sistem neuronal să aibă opțiunea de a integra noi rezumate de brevete sensibile.
De asemenea, dacă sunteți interesat să aflați mai multe despre învățarea automată, consultați Programul Executive PG de la IIIT-B și upGrad în Învățare automată și AI, care este conceput pentru profesioniști care lucrează și oferă peste 450 de ore de pregătire riguroasă, peste 30 de studii de caz și sarcini. , statutul de absolvenți IIIT-B, peste 5 proiecte practice practice și asistență pentru locuri de muncă cu firme de top.
Este CNN mai rapid decât RNN?
Dacă ne uităm la timpul de calcul atât al CNN, cât și al RNN, se constată că CNN este foarte rapid (~ 5x) în comparație cu RNN. Să încercăm să înțelegem acest lucru într-un mod mai bun cu un exemplu.
Dacă o recenzie a unui restaurant este: „Serviciul a fost incredibil de lent și sunt destul de dezamăgit de acest restaurant. Calitatea mâncării a fost, de asemenea, mediocră.' Aici, există date secvențiale prezente în declarație, în care s-ar putea să încercați să aflați dacă sentimentele sunt bune sau rele. Modelul CNN va putea face calculele mai rapide aici, deoarece s-ar uita doar la anumite expresii, cum ar fi „incredibil de lent”, „mediocru” și „dezamăgit”. Aici, RNN s-ar putea să vă încurce, uitându-vă la câțiva alți parametri. CNN este un model mai simplu, ceea ce îl face mai eficient decât RNN.
Care sunt aplicațiile RNN?
RNN-urile sunt modele de învățare automată destul de puternice care sunt utilizate în multe domenii. Scopul principal al RNN este de a procesa datele secvențiale care îi sunt puse la dispoziție. Disponibilitatea datelor secvențiale se găsește în diferite domenii. Unele dintre aplicațiile sale în diferite domenii includ traducerea automată, recunoașterea vorbirii, analiza centrului de apeluri, problemele de predicție, rezumarea textului, etichetarea video, detectarea feței, recunoașterea imaginilor, aplicațiile OCR și compoziția muzicală.
Care sunt unele diferențe cheie dintre RNN și CNN?
RNN-urile sunt utile pentru analiza datelor secvențiale și temporale, cum ar fi videoclipuri sau text. Pe de altă parte, CNN este util pentru rezolvarea problemelor legate de date spațiale, cum ar fi imaginile. În RNN, dimensiunile intrărilor și ieșirilor pot varia, în timp ce în CNN, există o dimensiune fixă pentru intrare, precum și pentru ieșirea rezultată. Unele cazuri de utilizare pentru RNN sunt traducerea automată, analiza vorbirii, analiza sentimentelor și problemele de predicție, în timp ce CNN-urile sunt utile în analiza medicală, clasificarea și recunoașterea facială.