
Jaringan Neural Berulang dengan Python: Panduan Utama untuk Pemula
Diterbitkan: 2020-04-27Saat Anda perlu memproses urutan – harga saham harian, pengukuran sensor, dll. – dalam sebuah program, Anda memerlukan jaringan saraf berulang (RNN).
RNN adalah semacam Neural Network di mana output dari satu langkah ditransfer sebagai input ke langkah baru. Dalam sistem saraf konvensional, semua sumber dan keluaran data bersifat otonom satu sama lain. Namun, dalam kasus seperti ketika diperlukan untuk mengantisipasi ekspresi kalimat berikutnya, kata-kata sebelumnya diperlukan, dan akibatnya, ada kebutuhan untuk mengingat kata-kata masa lalu.
Di sinilah RNN muncul. Itu menciptakan Lapisan Tersembunyi untuk memecahkan masalah ini. Elemen mendasar dan paling signifikan dari RNN adalah status Tersembunyi, yang mengingat beberapa data tentang urutan.
RNN telah menghasilkan hasil yang akurat di beberapa aplikasi dunia nyata yang paling umum: Karena kemampuannya menangani teks secara efektif, RNN umumnya digunakan dalam tugas Pemrosesan Bahasa Alami (NLP).
- Pengenalan suara
- Mesin penerjemah
- Komposisi musik
- Pengenalan tulisan tangan
- Belajar tata bahasa
Inilah sebabnya mengapa RNN telah mendapatkan popularitas luar biasa di ruang pembelajaran yang mendalam.
Sekarang mari kita lihat kebutuhan akan jaringan saraf berulang dengan Python.
Dapatkan Sertifikasi Pembelajaran Mesin secara online dari Universitas top dunia – Magister, Program Pascasarjana Eksekutif, dan Program Sertifikat Tingkat Lanjut di ML & AI untuk mempercepat karier Anda.
Daftar isi
Apa Kebutuhan untuk RNN di Python?
Untuk menjawab pertanyaan ini, pertama-tama kita perlu mengatasi masalah yang terkait dengan Convolution Neural Network (CNN), juga disebut vanilla neural nets.
Masalah utama dengan CNN adalah bahwa mereka hanya dapat bekerja untuk ukuran yang telah ditentukan, yaitu jika mereka menerima input ukuran tetap, mereka juga memberikan output ukuran tetap.
Padahal, dengan RNN, masalah ini mudah diatasi. RNN memungkinkan pengembang untuk bekerja dengan urutan panjang variabel baik untuk input maupun output.
Di bawah ini adalah ilustrasi tampilan RNN:
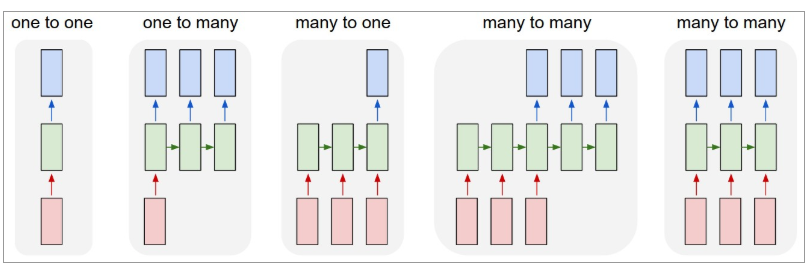
Sumber: Andrej Karpathy
Di sini, warna merah menunjukkan input, RNN hijau, dan output biru.
Mari kita pahami masing-masing secara detail.
Satu-ke-satu : Ini juga disebut jaringan saraf polos atau vanilla. Mereka bekerja dengan ukuran input tetap ke ukuran output tetap dan tidak tergantung pada input sebelumnya.
Contoh : Klasifikasi citra.
Satu-ke-banyak : Sementara informasi sebagai input berukuran tetap, outputnya adalah urutan data.
Contoh : Image captioning (gambar adalah input, dan output adalah kumpulan kata).
Many-to-one : Input adalah urutan informasi dan output berukuran tetap.
Contoh : Analisis sentimen (input adalah kumpulan kata dan output memberitahu apakah kumpulan kata tersebut mencerminkan sentimen positif atau negatif).
Many-to-many : Input adalah urutan informasi dan output adalah urutan data.
Contoh : Terjemahan mesin (RNN membaca kalimat dalam bahasa Inggris dan memberikan output kalimat dalam bahasa yang diinginkan).
Pemrosesan urutan dengan panjang variabel membuat RNN sangat berguna. Berikut caranya:
- Terjemahan Mesin : Contoh terbaik dari ini adalah Google Terjemahan. Ia bekerja pada banyak-ke-banyak RNN. Seperti yang Anda ketahui, teks asli dimasukkan ke RNN, yang menghasilkan teks terjemahan.
- Analisis Sentimen : Anda tahu bagaimana Google memisahkan ulasan negatif dari yang positif? Hal ini dicapai dengan RNN banyak-ke-satu. Ketika teks dimasukkan ke dalam RNN, ia memberikan output, yang mencerminkan kelas di mana input berada.
Sekarang mari kita lihat bagaimana RNN bekerja.
Bagaimana RNN Bekerja?
Cara terbaik untuk memahami cara kerja jaringan saraf berulang dengan Python dengan melihat sebuah contoh.
Misalkan ada jaringan yang lebih dalam yang berisi satu lapisan keluaran, tiga lapisan tersembunyi, dan satu lapisan masukan.
Seperti halnya dengan jaringan saraf lainnya, dalam hal ini juga, setiap lapisan tersembunyi akan datang dengan bobot dan biasnya sendiri.
Untuk contoh ini, mari kita pertimbangkan bahwa bobot dan bias untuk layer 1 adalah (w1, b1), layer 2 adalah (w2, b2), dan layer 3 adalah (w3, b3). Ketiga lapisan ini independen satu sama lain dan tidak mengingat hasil sebelumnya.
Sekarang, inilah yang akan dilakukan RNN:
- Ini akan mengubah aktivasi independen menjadi dependen dengan membuat semua lapisan memiliki bobot dan bias yang sama. Ini akan, pada gilirannya, mengurangi kompleksitas peningkatan parameter dan mengingat setiap hasil sebelumnya dengan memberikan output sebagai input ke lapisan tersembunyi berikutnya.
- Dengan demikian, ketiga lapisan akan terjalin menjadi satu lapisan berulang yang mengandung bobot dan bias yang sama.
- Untuk menghitung keadaan saat ini, Anda dapat menggunakan rumus berikut:
Di mana,

= keadaan saat ini
= keadaan sebelumnya
= keadaan masukan
- Untuk menerapkan fungsi Aktivasi (tanh), gunakan rumus berikut:
Di mana,
= berat pada neuron rekuren
= bobot pada neuron masukan
- Untuk menghitung output, gunakan rumus berikut:
Di mana,
= keluaran
= berat pada lapisan keluaran
Berikut adalah penjelasan langkah demi langkah tentang bagaimana RNN dapat dilatih.
- Pada satu waktu, input diberikan ke jaringan.
- Sekarang, Anda perlu menghitung status saat ini menggunakan set input saat ini dan status sebelumnya.
- Arus akan menjadi langkah waktu berikutnya.
- Anda dapat melakukan langkah waktu sebanyak yang Anda inginkan dan menggabungkan data dari semua status sebelumnya.
- Segera setelah semua langkah waktu selesai, gunakan status arus akhir untuk menghitung keluaran akhir.
- Bandingkan output ini dengan output aktual, yaitu output target dan kesalahan di antara keduanya.
- Sebarkan kesalahan kembali ke jaringan dan perbarui bobot untuk melatih RNN.
Kesimpulan
Sebagai penutup, pertama-tama saya ingin menunjukkan keuntungan dari Recurring Neural Network dengan Python:
- Sebuah RNN dapat mengingat semua informasi yang diterimanya. Ini adalah karakteristik yang paling banyak digunakan dalam prediksi seri karena dapat mengingat input sebelumnya.
- Di RNN, fungsi transisi yang sama dengan parameter yang sama dapat digunakan pada setiap langkah waktu.
Sangat penting untuk memahami bahwa jaringan saraf berulang di Python tidak memiliki pemahaman bahasa. Ini adalah mesin pengenalan pola yang cukup canggih. Bagaimanapun, tidak seperti metode seperti rantai Markov atau analisis frekuensi, RNN membuat prediksi bergantung pada urutan komponen dalam urutan.
Pada dasarnya, jika Anda mengatakan bahwa orang hanyalah mesin pengenalan pola yang luar biasa dan, dengan cara ini, sistem saraf berulang hanya bertindak seperti mesin manusia.
Penggunaan RNN jauh melampaui pembuatan konten hingga terjemahan mesin, teks gambar, dan identifikasi kepengarangan. Meskipun RNN tidak mungkin menggantikan manusia, ada kemungkinan bahwa dengan lebih banyak informasi pelatihan dan model yang lebih besar, sistem saraf akan memiliki opsi untuk mengintegrasikan abstrak paten baru yang masuk akal.
Juga, Jika Anda tertarik untuk mempelajari lebih lanjut tentang Pembelajaran mesin, lihat Program PG Eksekutif IIIT-B & upGrad dalam Pembelajaran Mesin & AI yang dirancang untuk para profesional yang bekerja dan menawarkan 450+ jam pelatihan ketat, 30+ studi kasus & tugas , Status Alumni IIIT-B, 5+ proyek batu penjuru praktis & bantuan pekerjaan dengan perusahaan-perusahaan top.
Apakah CNN lebih cepat dari RNN?
Jika kita melihat waktu komputasi CNN dan RNN, CNN ditemukan sangat cepat (~ 5x) dibandingkan dengan RNN. Mari kita coba memahami ini dengan cara yang lebih baik dengan sebuah contoh.
Jika ulasan restoran adalah: 'Layanannya sangat lambat, dan saya cukup kecewa dengan restoran ini. Kualitas makanannya juga biasa-biasa saja.' Di sini, ada data berurutan yang ada dalam pernyataan itu, di mana Anda mungkin mencoba mencari tahu apakah sentimen itu baik atau buruk. Model CNN akan dapat membuat perhitungan lebih cepat di sini karena hanya akan melihat frasa tertentu, seperti 'sangat lambat', 'biasa-biasa saja', dan 'kecewa'. Di sini, RNN mungkin hanya membingungkan Anda dengan melihat beberapa parameter lainnya. CNN adalah model yang lebih sederhana, yang membuatnya lebih efisien daripada RNN.
Apa saja aplikasi RNN?
RNN adalah model pembelajaran mesin yang cukup kuat yang digunakan di banyak area. Tujuan utama dari RNN adalah untuk memproses data sekuensial yang tersedia untuk itu. Ketersediaan data sekuensial ditemukan di berbagai domain. Beberapa aplikasinya dalam domain yang berbeda termasuk Terjemahan mesin, Pengenalan ucapan, Analisis pusat panggilan, Masalah prediksi, Peringkasan teks, Penandaan video, Deteksi wajah, Pengenalan gambar, aplikasi OCR, dan Komposisi musik.
Apa perbedaan utama antara RNN dan CNN?
RNN berguna untuk menganalisis data sekuensial dan temporal seperti video atau teks. Di sisi lain, CNN berguna untuk memecahkan masalah yang terkait dengan data spasial seperti gambar. Di RNN, ukuran input dan output dapat bervariasi, sedangkan di CNN, ada ukuran tetap untuk input serta output yang dihasilkan. Beberapa kasus penggunaan untuk RNN adalah terjemahan mesin, analisis ucapan, analisis sentimen, dan masalah prediksi, sedangkan CNN berguna dalam analisis medis, klasifikasi, dan pengenalan wajah.