
Rekurencyjna sieć neuronowa w Pythonie: najlepszy przewodnik dla początkujących
Opublikowany: 2020-04-27Kiedy potrzebujesz przetworzyć sekwencje – dzienne ceny akcji, pomiary czujników itp. – w programie, potrzebujesz rekurencyjnej sieci neuronowej (RNN).
RNN są rodzajem sieci neuronowej, w której dane wyjściowe z jednego kroku są przesyłane jako dane wejściowe do nowego kroku. W konwencjonalnych systemach neuronowych wszystkie źródła danych i wyjścia są od siebie autonomiczne. Jednak w przypadkach, gdy wymagane jest uprzedzenie następnego wyrażenia zdania, wymagane są poprzednie słowa, a co za tym idzie, istnieje potrzeba przypomnienia minionych słów.
W tym miejscu pojawia się RNN. Stworzył ukrytą warstwę, aby rozwiązać te problemy. Podstawowym i najważniejszym elementem RNN jest stan ukryty, który zapamiętuje pewne dane o sekwencji.
RNN generują dokładne wyniki w niektórych najpopularniejszych aplikacjach rzeczywistych: Ze względu na ich zdolność do efektywnego przetwarzania tekstu RNN są zwykle używane w zadaniach przetwarzania języka naturalnego (NLP).
- Rozpoznawanie mowy
- Tłumaczenie maszynowe
- Kompozycja muzyczna
- Rozpoznawanie pisma odręcznego
- Nauka gramatyki
Właśnie dlatego RNN zyskały ogromną popularność w przestrzeni uczenia głębokiego.
Zobaczmy teraz potrzebę rekurencyjnych sieci neuronowych w Pythonie.
Uzyskaj certyfikat uczenia maszynowego online z najlepszych światowych uniwersytetów — studiów magisterskich, programów podyplomowych dla kadry kierowniczej i zaawansowanego programu certyfikacji w zakresie uczenia się maszynowego i sztucznej inteligencji, aby przyspieszyć swoją karierę.
Spis treści
Jakie jest zapotrzebowanie na RNN w Pythonie?
Aby odpowiedzieć na to pytanie, najpierw musimy zająć się problemami związanymi z siecią neuronową splotową (CNN), zwaną także waniliowymi sieciami neuronowymi.
Główny problem związany z CNN polega na tym, że mogą one działać tylko dla wcześniej zdefiniowanych rozmiarów, tj. jeśli akceptują dane wejściowe o stałym rozmiarze, dają również dane wyjściowe o stałym rozmiarze.
Natomiast w przypadku sieci RNN problem ten można łatwo rozwiązać. RNN umożliwiają programistom pracę z sekwencjami o zmiennej długości zarówno dla danych wejściowych, jak i wyjściowych.
Poniżej znajduje się ilustracja tego, jak wyglądają RNN:
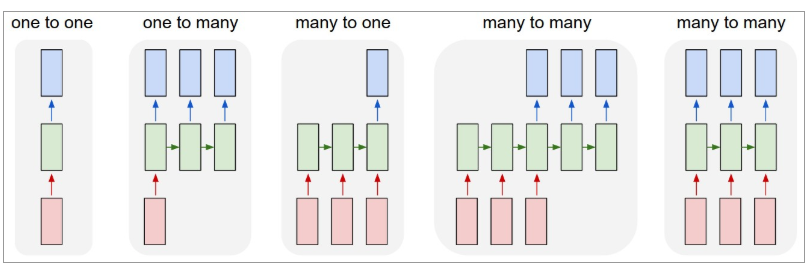
Źródło: Andrej Karpathy
Tutaj kolor czerwony oznacza wejścia, zielone RNN i niebieskie wyjścia.
Przyjrzyjmy się każdemu szczegółowo.
Jeden do jednego : są one również nazywane zwykłymi lub waniliowymi sieciami neuronowymi. Pracują ze stałym rozmiarem wejściowym do stałego rozmiaru wyjściowego i są niezależne od poprzednich danych wejściowych.
Przykład : klasyfikacja obrazu.
Jeden-do-wielu : podczas gdy informacje jako dane wejściowe mają stały rozmiar, dane wyjściowe są sekwencją danych.
Przykład : napisy do obrazów (obraz to wejście, a wyjście to zestaw słów).
Wiele do jednego : dane wejściowe to sekwencja informacji, a dane wyjściowe mają stały rozmiar.
Przykład : analiza sentymentu (dane wejściowe to zestaw słów, a dane wyjściowe określają, czy zestaw słów odzwierciedla sentyment pozytywny, czy negatywny).
Wiele do wielu : dane wejściowe to sekwencja informacji, a dane wyjściowe to sekwencja danych.
Przykład : Tłumaczenie maszynowe (RNN czyta zdanie w języku angielskim i podaje zdanie w żądanym języku).
Przetwarzanie sekwencji o zmiennej długości sprawia, że RNN są tak przydatne. Oto jak:
- Tłumaczenie maszynowe : najlepszym tego przykładem jest Tłumacz Google. Działa na RNN typu „wiele do wielu”. Jak wiecie, oryginalny tekst jest wprowadzany do RNN, co daje przetłumaczony tekst.
- Analiza nastrojów : wiesz, jak Google oddziela negatywne recenzje od pozytywnych? Osiąga się to za pomocą RNN typu „wiele do jednego”. Gdy tekst jest wprowadzany do RNN, daje wynik, odzwierciedlając klasę, w której znajduje się dane wejściowe.
Zobaczmy teraz, jak działają RNN.
Jak działają sieci RNN?
Najlepiej jest zrozumieć działanie powtarzalnej sieci neuronowej w Pythonie, patrząc na przykład.
Załóżmy, że istnieje głębsza sieć zawierająca jedną warstwę wyjściową, trzy warstwy ukryte i jedną warstwę wejściową.
Podobnie jak w przypadku innych sieci neuronowych, również w tym przypadku każda ukryta warstwa będzie miała własny zestaw wag i odchyleń.
Na potrzeby tego przykładu rozważmy, że wagi i odchylenia dla warstwy 1 to (w1, b1), warstwy 2 to (w2, b2), a warstwy 3 to (w3, b3). Te trzy warstwy są od siebie niezależne i nie zapamiętują poprzednich wyników.
A oto, co zrobi RNN:
- Przekształci niezależne aktywacje w zależne, sprawiając, że wszystkie warstwy będą zawierały te same wagi i obciążenia. To z kolei zmniejszy złożoność zwiększania parametrów i zapamiętywania każdego z poprzednich wyników, dając dane wyjściowe jako dane wejściowe do następnej ukrytej warstwy.
- W ten sposób wszystkie trzy warstwy zostaną splecione w jedną warstwę powtarzalną, aby zawierać te same wagi i odchylenia.
- Aby obliczyć aktualny stan, możesz skorzystać z następującego wzoru:
Gdzie,

= stan obecny
= poprzedni stan
= stan wejścia
- Aby zastosować funkcję Activation (tanh), użyj następującego wzoru:
Gdzie,
= waga w neuronie rekurencyjnym
= waga w neuronie wejściowym
- Aby obliczyć wydajność, użyj następującego wzoru:
Gdzie,
= wyjście
= waga na warstwie wyjściowej
Oto wyjaśnienie krok po kroku, jak można trenować RNN.
- W pewnym momencie dane wejściowe są przekazywane do sieci.
- Teraz musisz obliczyć jego aktualny stan przy użyciu bieżącego zestawu wejść i poprzedniego stanu.
- Prąd stanie się kolejnym krokiem czasu.
- Możesz przejść dowolną liczbę kroków czasowych i połączyć dane ze wszystkich poprzednich stanów.
- Jak tylko wszystkie kroki czasowe zostaną zakończone, użyj końcowego stanu prądu do obliczenia końcowego wyjścia.
- Porównaj to wyjście z rzeczywistym wyjściem, tj. wyjściem docelowym i błędem między nimi.
- Roześlij błąd z powrotem do sieci i zaktualizuj wagi, aby trenować RNN.
Wniosek
Na zakończenie chciałbym najpierw zwrócić uwagę na zalety cyklicznej sieci neuronowej w Pythonie:
- RNN może zapamiętać wszystkie otrzymane informacje. Jest to cecha najczęściej używana w przewidywaniu szeregów, ponieważ umożliwia zapamiętywanie poprzednich danych wejściowych.
- W RNN ta sama funkcja przejścia z tymi samymi parametrami może być używana w każdym kroku czasowym.
Niezwykle ważne jest zrozumienie, że cykliczna sieć neuronowa w Pythonie nie rozumie języka. Jest to odpowiednio zaawansowana maszyna do rozpoznawania wzorów. W każdym razie, w przeciwieństwie do metod takich jak łańcuchy Markowa lub analiza częstotliwości, RNN uzależnia przewidywania od kolejności składników w sekwencji.
Zasadniczo, jeśli powiesz, że ludzie są po prostu niezwykłymi maszynami do rozpoznawania wzorców iw ten sposób rekurencyjny system nerwowy zachowuje się jak ludzka maszyna.
Zastosowania RNN znacznie wykraczają poza generowanie treści do tłumaczenia maszynowego, tworzenia podpisów do obrazów i identyfikacji autorstwa. Mimo że RNN nie mogą zastąpić ludzi, możliwe jest, że przy większej ilości informacji szkoleniowych i większym modelu system neuronowy będzie miał możliwość zintegrowania nowych, sensownych abstraktów patentowych.
Ponadto, jeśli chcesz dowiedzieć się więcej o uczeniu maszynowym, sprawdź program PG dla kadry kierowniczej IIIT-B i upGrad w uczeniu maszynowym i sztucznej inteligencji , który jest przeznaczony dla pracujących profesjonalistów i oferuje ponad 450 godzin rygorystycznego szkolenia, ponad 30 studiów przypadków i zadań , status absolwentów IIIT-B, ponad 5 praktycznych praktycznych projektów zwieńczenia i pomoc w pracy z najlepszymi firmami.
Czy CNN jest szybsze niż RNN?
Jeśli spojrzymy na czas obliczeń zarówno CNN, jak i RNN, okazuje się, że CNN jest bardzo szybki (~5x) w porównaniu z RNN. Spróbujmy to lepiej zrozumieć na przykładzie.
Jeśli recenzja restauracji brzmi: „Obsługa jest niesamowicie powolna i jestem bardzo rozczarowany tą restauracją. Jakość jedzenia była również przeciętna”. Tutaj w zestawieniu znajdują się sekwencyjne dane, w których możesz próbować dowiedzieć się, czy nastroje są dobre, czy złe. Model CNN będzie w stanie przyspieszyć obliczenia tutaj, ponieważ uwzględniałby tylko niektóre wyrażenia, takie jak „niesamowicie powolny”, „przeciętny” i „rozczarowany”. W tym przypadku RNN może po prostu wprowadzić w błąd, patrząc na kilka innych parametrów. CNN jest prostszym modelem, co czyni go bardziej wydajnym niż RNN.
Jakie są zastosowania RNN?
RNN to dość potężne modele uczenia maszynowego, które są używane w wielu obszarach. Głównym celem RNN jest przetwarzanie danych sekwencyjnych, które są mu udostępniane. Dostępność danych sekwencyjnych można znaleźć w różnych domenach. Niektóre z jego zastosowań w różnych domenach obejmują tłumaczenie maszynowe, rozpoznawanie mowy, analizę call center, problemy z przewidywaniem, podsumowywanie tekstu, tagowanie wideo, wykrywanie twarzy, rozpoznawanie obrazów, aplikacje OCR i kompozycję muzyki.
Jakie są kluczowe różnice między RNN a CNN?
RNN są przydatne do analizowania danych sekwencyjnych i czasowych, takich jak filmy czy tekst. Z drugiej strony CNN jest przydatne do rozwiązywania problemów związanych z danymi przestrzennymi, takimi jak obrazy. W RNN rozmiary danych wejściowych i wyjściowych mogą się różnić, podczas gdy w CNN istnieje stały rozmiar zarówno wejściowych, jak i wynikowych wyników. Niektóre przypadki użycia RNN to tłumaczenie maszynowe, analiza mowy, analiza sentymentu i problemy z przewidywaniem, podczas gdy CNN są przydatne w analizie medycznej, klasyfikacji i rozpoznawaniu twarzy.