
Pythonのリカレントニューラルネットワーク:初心者のための究極のガイド
公開: 2020-04-27プログラムでシーケンス(毎日の株価、センサー測定など)を処理する必要がある場合は、リカレントニューラルネットワーク(RNN)が必要です。
RNNは一種のニューラルネットワークであり、1つのステップからの出力が新しいステップへの入力として転送されます。 従来のニューラルシステムでは、すべてのデータソースと出力は互いに自律しています。 ただし、次の文の表現を予想する必要がある場合などは、前の単語が必要になるため、過去の単語を思い出す必要があります。
ここでRNNが登場します。 これらの問題を解決するために隠しレイヤーを作成しました。 RNNの基本的で最も重要な要素は、シーケンスに関するいくつかのデータを記憶する非表示状態です。
RNNは、最も一般的な実際のアプリケーションのいくつかで正確な結果を生成しています。テキストを効果的に処理できるため、RNNは一般に自然言語処理(NLP)タスクで使用されます。
- 音声認識
- 機械翻訳
- 作曲
- 手書き認識
- 文法学習
これが、RNNがディープラーニングの分野で絶大な人気を博している理由です。
それでは、Pythonでリカレントニューラルネットワークの必要性を見てみましょう。
世界のトップ大学(修士、エグゼクティブ大学院プログラム、ML&AIの高度な証明書プログラム)からオンラインで機械学習認定を取得して、キャリアを早急に進めましょう。
目次
PythonでのRNNの必要性は何ですか?
この質問に答えるには、まず、バニラニューラルネットとも呼ばれる畳み込みニューラルネットワーク(CNN)に関連する問題に対処する必要があります。
CNNの主な問題は、事前定義されたサイズでのみ機能することです。つまり、CNNが固定サイズの入力を受け入れる場合、固定サイズの出力も提供します。
一方、RNNを使用すると、この問題は簡単に解決できます。 RNNを使用すると、開発者は入力と出力の両方で可変長シーケンスを操作できます。
以下は、RNNがどのように見えるかを示しています。
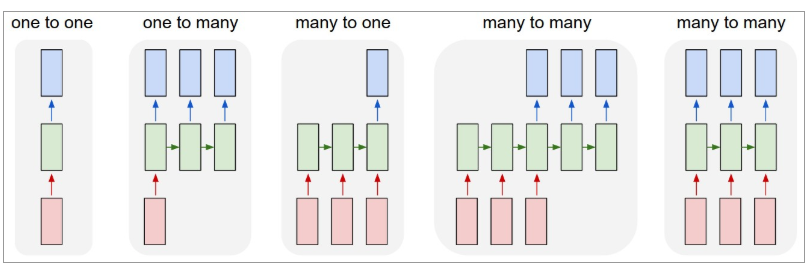
出典: Andrej Karpathy
ここで、赤色は入力、緑色のRNN、および青色の出力を示します。
それぞれを詳しく理解しましょう。
1対1 :これらはプレーンまたはバニラニューラルネットワークとも呼ばれます。 これらは固定入力サイズから固定出力サイズで動作し、以前の入力から独立しています。
例:画像の分類。
1対多:入力としての情報は固定サイズですが、出力は一連のデータです。
例:画像のキャプション(画像は入力され、出力は単語のセットです)。
多対1 :入力は一連の情報であり、出力は固定サイズです。
例:感情分析(入力は単語のセットであり、出力は単語のセットが肯定的または否定的な感情を反映しているかどうかを示します)。
多対多:入力は一連の情報であり、出力は一連のデータです。
例:機械翻訳(RNNは英語で文を読み取り、目的の言語で文を出力します)。
可変長のシーケンス処理により、RNNは非常に便利になります。 方法は次のとおりです。
- 機械翻訳:これの最も良い例はGoogle翻訳です。 多対多のRNNで機能します。 ご存知のように、元のテキストはRNNに入力され、翻訳されたテキストが生成されます。
- 感情分析:Googleが否定的なレビューを肯定的なレビューからどのように分離するか知っていますか? これは、多対1のRNNによって実現されます。 テキストがRNNに供給されると、入力が存在するクラスを反映して出力が提供されます。
次に、RNNがどのように機能するかを見てみましょう。
RNNはどのように機能しますか?
例を見て、Pythonでのリカレントニューラルネットワークの動作を理解するのが最善です。
1つの出力層、3つの隠れ層、および1つの入力層を含むより深いネットワークがあると仮定します。
他のニューラルネットワークの場合と同様に、この場合も、各隠れ層には独自の重みとバイアスのセットが付属します。
この例のために、レイヤー1の重みとバイアスが(w1、b1)、レイヤー2が(w2、b2)、レイヤー3が(w3、b3)であると考えてみましょう。 これらの3つのレイヤーは互いに独立しており、以前の結果を記憶していません。
さて、これがRNNが行うことです:
- すべてのレイヤーに同じ重みとバイアスが含まれるようにすることで、独立したアクティベーションを依存するアクティベーションに変換します。 これにより、次の非表示レイヤーへの入力として出力を提供することにより、パラメーターを増やし、以前の各結果を記憶するという複雑さが軽減されます。
- したがって、3つのレイヤーすべてが1つの繰り返しレイヤーに絡み合って、同じ重みとバイアスが含まれます。
- 現在の状態を計算するには、次の式を使用できます。
どこ、
=現在の状態
=前の状態
=入力状態
- 活性化関数(tanh)を適用するには、次の式を使用します。
どこ、

=リカレントニューロンでの重み
=入力ニューロンでの重み
- 出力を計算するには、次の式を使用します。
どこ、
=出力
=出力層での重み
これは、RNNをトレーニングする方法の段階的な説明です。
- 一度に、入力はネットワークに与えられます。
- 次に、現在の入力セットと前の状態を使用して、現在の状態を計算する必要があります。
- 電流は時間の次のステップになります。
- 必要な数のタイムステップを実行して、以前のすべての状態のデータを組み合わせることができます。
- すべてのタイムステップが完了したらすぐに、最終的な現在の状態を使用して最終的な出力を計算します。
- この出力を実際の出力、つまりターゲット出力と2つの間のエラーと比較します。
- エラーをネットワークに伝播し、重みを更新してRNNをトレーニングします。
結論
結論として、私は最初にPythonの繰り返しニューラルネットワークの利点を指摘したいと思います。
- RNNは、受信したすべての情報を記憶できます。 これは、前の入力を記憶できるため、系列予測で最もよく使用される特性です。
- RNNでは、同じパラメーターを持つ同じ遷移関数をすべてのタイムステップで使用できます。
Pythonのリカレントニューラルネットワークには言語の理解がないことを理解することが重要です。 十分に高度なパターン認識マシンです。 いずれの場合も、マルコフ連鎖や頻度分析などの方法とは異なり、RNNはシーケンス内のコンポーネントの順序に応じて予測を行います。
基本的に、人はただの異常なパターン認識マシンであり、このように、再発神経系は人間のマシンのように機能していると言えます。
RNNの使用は、コンテンツの生成をはるかに超えて、機械翻訳、画像のキャプション、および作成者の識別にまで及びます。 RNNが人間に取って代わることはできないかもしれませんが、より多くのトレーニング情報とより大きなモデルがあれば、ニューラルシステムに新しい賢明な特許抄録を統合するオプションがある可能性があります。
また、機械学習について詳しく知りたい場合は、機械学習とAIのIIIT-BとupGradのエグゼクティブPGプログラムをご覧ください。このプログラムは、働く専門家向けに設計されており、450時間以上の厳格なトレーニング、30以上のケーススタディと課題を提供しています。 、IIIT-B卒業生のステータス、5つ以上の実践的なキャップストーンプロジェクト、トップ企業との雇用支援。
CNNはRNNよりも高速ですか?
CNNとRNNの両方の計算時間を見ると、CNNはRNNと比較して非常に高速(約5倍)であることがわかります。 例を挙げて、これをよりよく理解してみましょう。
レストランのレビューが次の場合:'サービスは非常に遅く、私はこのレストランにかなり失望しています。 食事の質も平凡でした。」 ここでは、ステートメントにシーケンシャルデータがあり、感情が良いか悪いかを調べようとしている可能性があります。 CNNモデルは、「信じられないほど遅い」、「平凡」、「がっかり」などの特定のフレーズのみを調べるため、ここで計算を高速化できます。 ここで、RNNは、他のいくつかのパラメーターを見て混乱する可能性があります。 CNNはより単純なモデルであるため、RNNよりも効率的です。
RNNのアプリケーションは何ですか?
RNNは非常に強力な機械学習モデルであり、多くの分野で使用されています。 RNNの主な目的は、利用可能になったシーケンシャルデータを処理することです。 シーケンシャルデータの可用性は、さまざまなドメインで見られます。 さまざまなドメインでのアプリケーションには、機械翻訳、音声認識、コールセンター分析、予測の問題、テキストの要約、ビデオのタグ付け、顔検出、画像認識、OCRアプリケーション、音楽の作曲などがあります。
RNNとCNNの主な違いは何ですか?
RNNは、ビデオやテキストなどのシーケンシャルデータと時間データを分析するのに役立ちます。 一方、CNNは、画像などの空間データに関連する問題を解決するのに役立ちます。 RNNでは、入力と出力のサイズが異なる場合がありますが、CNNでは、入力と結果の出力のサイズが固定されています。 RNNのいくつかの使用例は、機械翻訳、音声分析、感情分析、および予測の問題ですが、CNNは、医学的分析、分類、および顔認識に役立ちます。