
الشبكة العصبية المتكررة في Python: الدليل النهائي للمبتدئين
نشرت: 2020-04-27عندما تحتاج إلى معالجة التسلسلات - أسعار الأسهم اليومية ، وقياسات أجهزة الاستشعار ، وما إلى ذلك - في أحد البرامج ، فأنت بحاجة إلى شبكة عصبية متكررة (RNN).
RNNs هي نوع من الشبكات العصبية حيث يتم نقل الإخراج من خطوة واحدة كمدخل إلى الخطوة الجديدة. في الأنظمة العصبية التقليدية ، تكون جميع مصادر البيانات والمخرجات مستقلة عن بعضها البعض. ومع ذلك ، في حالات مثل عندما يكون مطلوبًا توقع التعبير التالي للجملة ، تكون الكلمات السابقة مطلوبة ، وبالتالي ، هناك حاجة لتذكر الكلمات السابقة.
هذا هو المكان الذي تأتي فيه RNN في الصورة. لقد أنشأت طبقة خفية لحل هذه المشكلات. العنصر الأساسي والأكثر أهمية في RNN هو Hidden state ، الذي يتذكر بعض البيانات حول التسلسل.
تعمل RNNs على إنشاء نتائج دقيقة في بعض أكثر تطبيقات العالم الحقيقي شيوعًا: نظرًا لقدرتها على التعامل مع النص بفعالية ، تُستخدم RNNs بشكل عام في مهام معالجة اللغة الطبيعية (NLP).
- التعرف على الكلام
- الترجمة الآلية
- التأليف الموسيقي
- التعرف على خط اليد
- تعلم القواعد
هذا هو السبب في أن RNNs اكتسبت شعبية هائلة في مجال التعلم العميق.
الآن دعونا نرى الحاجة إلى الشبكات العصبية المتكررة في بايثون.
احصل على شهادة التعلم الآلي عبر الإنترنت من أفضل الجامعات في العالم - الماجستير ، وبرامج الدراسات العليا التنفيذية ، وبرنامج الشهادة المتقدم في ML & AI لتسريع حياتك المهنية.
جدول المحتويات
ما هي الحاجة إلى RNNs في بايثون؟
للإجابة على هذا السؤال ، نحتاج أولاً إلى معالجة المشكلات المرتبطة بالشبكة العصبية الالتفافية (CNN) ، والتي تسمى أيضًا شبكات الفانيليا العصبية.
تكمن المشكلة الرئيسية في شبكات CNN في أنها لا يمكنها العمل إلا للأحجام المحددة مسبقًا ، أي إذا كانت تقبل مدخلات ذات حجم ثابت ، فإنها تقدم أيضًا مخرجات ذات حجم ثابت.
بينما ، مع RNNs ، يتم التعامل مع هذه المشكلة بسهولة. تسمح RNNs للمطورين بالعمل مع متواليات متغيرة الطول لكل من المدخلات والمخرجات.
يوجد أدناه رسم توضيحي لشكل RNNs:
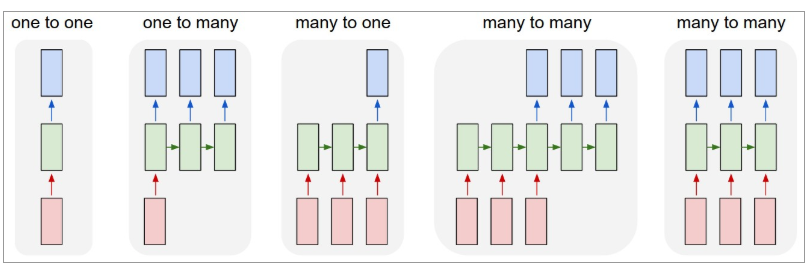
المصدر: أندريه كارباثي
هنا ، يشير اللون الأحمر إلى المدخلات و RNNs الخضراء والمخرجات الزرقاء.
دعونا نفهم كل منها بالتفصيل.
واحد لواحد : تسمى هذه أيضًا الشبكات العصبية العادية أو الفانيليا. إنها تعمل بحجم إدخال ثابت إلى حجم إخراج ثابت وتكون مستقلة عن المدخلات السابقة.
مثال : تصنيف الصورة.
واحد لأكثر : بينما المعلومات كمدخلات ذات حجم ثابت ، فإن المخرجات عبارة عن سلسلة من البيانات.
مثال : شرح الصورة (الصورة هي إدخال ، والإخراج عبارة عن مجموعة من الكلمات).
متعدد إلى واحد : الإدخال عبارة عن سلسلة من المعلومات والإخراج بحجم ثابت.
مثال : تحليل المشاعر (المدخلات عبارة عن مجموعة من الكلمات والمخرجات توضح ما إذا كانت مجموعة الكلمات تعكس شعورًا إيجابيًا أم سلبيًا).
متعدد إلى متعدد : الإدخال عبارة عن سلسلة من المعلومات والإخراج عبارة عن سلسلة من البيانات.
مثال : الترجمة الآلية (يقرأ RNN جملة باللغة الإنجليزية ويعطي ناتجًا للجملة باللغة المرغوبة).
معالجة التسلسل بأطوال متغيرة تجعل RNNs مفيدة للغاية. إليك الطريقة:
- الترجمة الآلية : أفضل مثال على ذلك هو الترجمة من Google. إنه يعمل على RNNs متعدد إلى كثير. كما تعلم ، يتم إدخال النص الأصلي إلى RNN ، والذي ينتج عنه نص مترجم.
- تحليل المشاعر : هل تعرف كيف تفصل Google المراجعات السلبية عن الإيجابية؟ يتم تحقيقه من خلال RNN متعدد إلى واحد. عندما يتم إدخال النص في RNN ، فإنه يعطي الإخراج ، مما يعكس الفئة التي يكمن فيها الإدخال.
الآن دعنا نرى كيف تعمل RNNs.
كيف تعمل RNNs؟
من الأفضل فهم عمل الشبكة العصبية المتكررة في بايثون من خلال النظر إلى مثال.
لنفترض أن هناك شبكة أعمق تحتوي على طبقة إخراج واحدة وثلاث طبقات مخفية وطبقة إدخال واحدة.
تمامًا كما هو الحال مع الشبكات العصبية الأخرى ، في هذه الحالة أيضًا ، ستأتي كل طبقة مخفية بمجموعتها الخاصة من الأوزان والتحيزات.
من أجل هذا المثال ، لنفترض أن الأوزان والتحيزات للطبقة 1 هي (w1 ، b1) ، والطبقة 2 هي (w2 ، b2) ، والطبقة 3 هي (w3 ، b3). هذه الطبقات الثلاث مستقلة عن بعضها البعض ولا تتذكر النتائج السابقة.
الآن ، إليك ما ستفعله RNN:
- سيحول عمليات التنشيط المستقلة إلى عمليات تابعة عن طريق جعل جميع الطبقات تحتوي على نفس الأوزان والتحيزات. سيؤدي هذا بدوره إلى تقليل تعقيد زيادة المعلمات وتذكر كل نتيجة من النتائج السابقة من خلال إعطاء الإخراج كمدخل للطبقة المخفية التالية.
- وهكذا ، سوف تتشابك الطبقات الثلاث في طبقة واحدة متكررة لتحتوي على نفس الأوزان والتحيزات.
- لحساب الحالة الحالية ، يمكنك استخدام الصيغة التالية:
أين،

= الحالة الحالية
= الحالة السابقة
= حالة الإدخال
- لتطبيق وظيفة التنشيط (tanh) ، استخدم الصيغة التالية:
أين،
= الوزن عند العصبون الراجع
= الوزن عند إدخال الخلايا العصبية
- لحساب الإخراج ، استخدم الصيغة التالية:
أين،
= الإخراج
= الوزن عند طبقة الإخراج
إليك شرحًا تفصيليًا لكيفية تدريب RNN.
- في وقت واحد ، يتم إدخال المدخلات إلى الشبكة.
- الآن ، تحتاج إلى حساب حالتها الحالية باستخدام مجموعة الإدخال الحالية والحالة السابقة.
- سيصبح التيار للخطوة التالية في الوقت.
- يمكنك متابعة العديد من الخطوات الزمنية كما تريد ودمج البيانات من جميع الحالات السابقة.
- بمجرد اكتمال جميع الخطوات الزمنية ، استخدم الحالة الحالية النهائية لحساب الناتج النهائي.
- قارن هذا الناتج بالمخرجات الفعلية ، أي الناتج المستهدف والخطأ بين الاثنين.
- انشر الخطأ مرة أخرى إلى الشبكة وقم بتحديث الأوزان لتدريب ال RNN.
خاتمة
في الختام ، أود أولاً أن أشير إلى مزايا الشبكة العصبية المتكررة في بايثون:
- يمكن لـ RNN تذكر جميع المعلومات التي تتلقاها. هذه هي الخاصية الأكثر استخدامًا في التنبؤ المتسلسل حيث يمكنها تذكر المدخلات السابقة.
- في RNN ، يمكن استخدام نفس وظيفة الانتقال مع نفس المعلمات في كل خطوة زمنية.
من المهم أن نفهم أن الشبكة العصبية المتكررة في بايثون ليس لديها فهم لغوي. إنها آلة متطورة للتعرف على الأنماط بشكل كاف. على أي حال ، على عكس طرق مثل سلاسل ماركوف أو تحليل التردد ، فإن RNN تقدم تنبؤات تعتمد على ترتيب المكونات في التسلسل.
في الأساس ، إذا قلت إن الناس مجرد آلات غير عادية للتعرف على الأنماط ، وبهذه الطريقة ، فإن النظام العصبي المتكرر يتصرف مثل آلة الإنسان.
تقطع استخدامات RNNs شوطًا طويلاً في إنشاء المحتوى إلى الترجمة الآلية ، والتعليق على الصور ، وتحديد هوية المؤلف. على الرغم من أن RNNs لا يمكن أن تحل محل البشر ، فمن الممكن أنه مع المزيد من المعلومات التدريبية والنموذج الأكبر ، سيكون لدى النظام العصبي خيار دمج مستخلصات براءات الاختراع الجديدة المعقولة.
أيضًا ، إذا كنت مهتمًا بمعرفة المزيد حول التعلم الآلي ، فراجع برنامج IIIT-B & upGrad التنفيذي PG في التعلم الآلي والذكاء الاصطناعي المصمم للمهنيين العاملين ويقدم أكثر من 450 ساعة من التدريب الصارم ، وأكثر من 30 دراسة حالة ومهمة ، حالة خريجي IIIT-B ، أكثر من 5 مشاريع تتويجا عملية ومساعدة وظيفية مع كبرى الشركات.
هل CNN أسرع من RNN؟
إذا نظرنا إلى وقت الحساب لكل من CNN و RNN ، فقد وجد أن CNN سريع جدًا (حوالي 5x) مقارنةً بـ RNN. دعونا نحاول فهم هذا بطريقة أفضل بمثال.
إذا كان تقييم المطعم هو: "كانت الخدمة بطيئة بشكل لا يصدق ، وأشعر بخيبة أمل كبيرة في هذا المطعم. كانت جودة الطعام متواضعة أيضًا. هنا ، توجد بيانات متسلسلة موجودة في البيان ، حيث قد تحاول معرفة ما إذا كانت المشاعر جيدة أم سيئة. سيكون نموذج CNN قادرًا على جعل العمليات الحسابية أسرع هنا لأنه سينظر فقط في عبارات معينة ، مثل "بطيء بشكل لا يصدق" و "متوسط" و "محبط". هنا ، قد تربكك RNN بالنظر إلى العديد من المعلمات الأخرى. CNN هو نموذج أبسط ، مما يجعله أكثر كفاءة من RNN.
ما هي تطبيقات ال RNN؟
تعد شبكات RNN نماذج قوية جدًا للتعلم الآلي يتم استخدامها في العديد من المجالات. الهدف الرئيسي من RNN هو معالجة البيانات المتسلسلة التي يتم توفيرها لها. تم العثور على توافر البيانات المتسلسلة في مجالات مختلفة. تتضمن بعض تطبيقاته في مجالات مختلفة الترجمة الآلية ، والتعرف على الكلام ، وتحليل مركز الاتصال ، ومشاكل التنبؤ ، وتلخيص النص ، وعلامات الفيديو ، واكتشاف الوجه ، والتعرف على الصور ، وتطبيقات التعرف الضوئي على الحروف ، وتكوين الموسيقى.
ما هي بعض الاختلافات الرئيسية بين RNN و CNN؟
RNNs مفيدة لتحليل البيانات المتسلسلة والزمنية مثل مقاطع الفيديو أو النص. من ناحية أخرى ، تعد CNN مفيدة في حل المشكلات المتعلقة بالبيانات المكانية مثل الصور. في RNN ، قد تختلف أحجام المدخلات والمخرجات ، بينما في CNN ، يوجد حجم ثابت للإدخال وكذلك الإخراج الناتج. بعض حالات الاستخدام لـ RNNs هي الترجمة الآلية ، وتحليل الكلام ، وتحليل المشاعر ، والتنبؤ ، بينما تعد شبكات CNN مفيدة في التحليل الطبي ، والتصنيف ، والتعرف على الوجه.