
Рекуррентная нейронная сеть в Python: полное руководство для начинающих
Опубликовано: 2020-04-27Когда вам нужно обрабатывать последовательности — ежедневные курсы акций, измерения датчиков и т. д. — в программе, вам нужна рекуррентная нейронная сеть (RNN).
RNN — это своего рода нейронная сеть, в которой выходные данные одного шага передаются в качестве входных данных для нового шага. В обычных нейронных системах все источники и выходы данных автономны друг от друга. Однако в случаях, когда требуется предвосхитить последующее выражение предложения, требуются предыдущие слова, и, следовательно, возникает необходимость вспомнить прошедшие слова.
Здесь на помощь приходит RNN. Он создал скрытый слой для решения этих проблем. Фундаментальным и наиболее важным элементом RNN является скрытое состояние, которое запоминает некоторые данные о последовательности.
RNN дают точные результаты в некоторых из наиболее распространенных реальных приложений: благодаря своей способности эффективно обрабатывать текст RNN обычно используются в задачах обработки естественного языка (NLP).
- Распознавание речи
- Машинный перевод
- Музыкальная композиция
- Распознавание рукописного ввода
- изучение грамматики
Вот почему RNN приобрели огромную популярность в области глубокого обучения.
Теперь давайте посмотрим на потребность в рекуррентных нейронных сетях в Python.
Получите онлайн-сертификат по машинному обучению в ведущих университетах мира — магистерские программы, программы последипломного образования для руководителей и продвинутые программы сертификации в области машинного обучения и искусственного интеллекта, чтобы ускорить свою карьеру.
Оглавление
Какая потребность в RNN в Python?
Чтобы ответить на этот вопрос, нам сначала нужно решить проблемы, связанные со сверточной нейронной сетью (CNN), также называемой ванильными нейронными сетями.
Основная проблема с CNN заключается в том, что они могут работать только с предварительно определенными размерами, т. е. если они принимают входные данные фиксированного размера, они также выдают выходные данные фиксированного размера.
Принимая во внимание, что с RNN эта проблема легко решается. RNN позволяют разработчикам работать с последовательностями переменной длины как для входных, так и для выходных данных.
Ниже приведена иллюстрация того, как выглядят RNN:
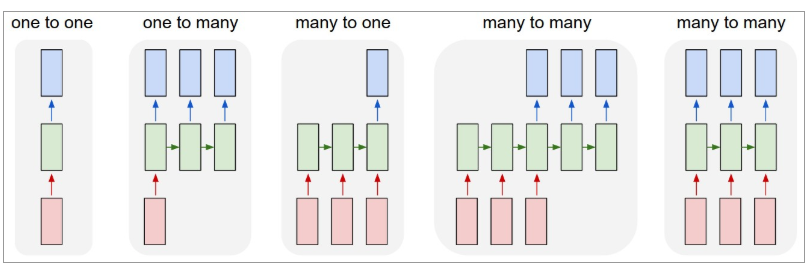
Источник: Андрей Карпаты
Здесь красный цвет обозначает входы, зеленые RNN и синие выходы.
Давайте разберемся в каждом подробно.
Один к одному : их также называют простыми или ванильными нейронными сетями. Они работают с фиксированным размером ввода для фиксированного размера вывода и не зависят от предыдущих входов.
Пример : классификация изображений.
Один ко многим : в то время как информация на входе имеет фиксированный размер, выход представляет собой последовательность данных.
Пример : Подпись к изображению (вводится изображение, а на выходе — набор слов).
Многие к одному : ввод представляет собой последовательность информации, а вывод имеет фиксированный размер.
Пример : анализ настроений (входные данные представляют собой набор слов, а выходные данные говорят о том, отражает ли набор слов положительное или отрицательное настроение).
Многие ко многим : ввод представляет собой последовательность информации, а вывод представляет собой последовательность данных.
Пример : машинный перевод (RNN читает предложение на английском языке и выдает предложение на нужном языке).
Обработка последовательностей с переменной длиной делает RNN такими полезными. Вот как:
- Машинный перевод : лучший пример — Google Translate. Он работает на RNN «многие ко многим». Как вы знаете, исходный текст вводится в RNN, которая дает переведенный текст.
- Анализ настроений . Вы знаете, как Google отделяет отрицательные отзывы от положительных? Это достигается с помощью RNN «многие к одному». Когда текст подается в RNN, он выдает результат, отражающий класс, в котором находится вход.
Теперь давайте посмотрим, как работают RNN.
Как работают RNN?
Лучше всего понять работу рекуррентной нейронной сети в Python на примере.
Предположим, что имеется более глубокая сеть, содержащая один выходной слой, три скрытых слоя и один входной слой.
Как и в случае с другими нейронными сетями, в этом случае каждый скрытый слой будет иметь свой собственный набор весов и смещений.
Для примера предположим, что веса и смещения для слоя 1 равны (w1, b1), слоя 2 (w2, b2) и слоя 3 (w3, b3). Эти три слоя независимы друг от друга и не запоминают предыдущие результаты.
Теперь вот что будет делать RNN:
- Он преобразует независимые активации в зависимые, заставив все слои иметь одинаковые веса и смещения. Это, в свою очередь, уменьшит сложность увеличения параметров и запоминания каждого из предыдущих результатов, предоставляя выходные данные в качестве входных данных для следующего скрытого слоя.
- Таким образом, все три слоя будут переплетены в один повторяющийся слой, содержащий одинаковые веса и смещения.
- Для расчета текущего состояния можно использовать следующую формулу:
Где,

= текущее состояние
= предыдущее состояние
= состояние ввода
- Чтобы применить функцию активации (tanh), используйте следующую формулу:
Где,
= вес рекуррентного нейрона
= вес на входном нейроне
- Для расчета выпуска используйте следующую формулу:
Где,
= выход
= вес на выходном слое
Вот пошаговое объяснение того, как можно обучить RNN.
- В один момент вход дается в сеть.
- Теперь вам нужно рассчитать его текущее состояние, используя текущий набор входных данных и предыдущее состояние.
- Текущий станет для следующего шага времени.
- Вы можете пройти столько временных шагов, сколько хотите, и объединить данные из всех предыдущих состояний.
- Как только все временные шаги будут завершены, используйте конечное текущее состояние для расчета окончательного вывода.
- Сравните этот вывод с фактическим выводом, т.е. целевым выводом и ошибкой между ними.
- Передайте ошибку обратно в сеть и обновите веса для обучения RNN.
Заключение
В заключение я хотел бы сначала указать на преимущества рекуррентной нейронной сети в Python:
- RNN может запоминать всю полученную информацию. Это характеристика, которая чаще всего используется в прогнозировании серий, поскольку она может запоминать предыдущие входные данные.
- В RNN одна и та же функция перехода с одними и теми же параметрами может использоваться на каждом временном шаге.
Очень важно понимать, что рекуррентная нейронная сеть в Python не понимает языка. Это достаточно продвинутая машина для распознавания образов. В любом случае, в отличие от таких методов, как цепи Маркова или частотный анализ, RNN делает прогнозы в зависимости от порядка компонентов в последовательности.
По сути, если вы скажете, что люди — это просто экстраординарные машины для распознавания образов, то рекуррентная нейронная система действует как человеко-машина.
Использование RNN проходит долгий путь от генерации контента до машинного перевода, подписи к изображениям и идентификации авторства. Несмотря на то, что RNN не могут заменить людей, вполне возможно, что с большим количеством обучающей информации и более крупной моделью нейронная система сможет интегрировать новые, разумные рефераты патентов.
Кроме того, если вам интересно узнать больше о машинном обучении, ознакомьтесь с программой Executive PG IIIT-B и upGrad по машинному обучению и искусственному интеллекту , которая предназначена для работающих профессионалов и предлагает более 450 часов тщательного обучения, более 30 тематических исследований и заданий. , статус выпускника IIIT-B, более 5 практических практических проектов и помощь в трудоустройстве в ведущих фирмах.
CNN быстрее, чем RNN?
Если мы посмотрим на время вычисления как CNN, так и RNN, CNN окажется очень быстрой (~ 5x) по сравнению с RNN. Попробуем лучше понять это на примере.
Если отзыв о ресторане: «Обслуживание было невероятно медленным, и я очень разочарован этим рестораном. Качество еды также было посредственным». Здесь в утверждении присутствуют последовательные данные, где вы, возможно, пытаетесь выяснить, хорошие или плохие настроения. Модель CNN сможет ускорить вычисления здесь, поскольку она будет учитывать только определенные фразы, такие как «невероятно медленно», «посредственно» и «разочаровано». Здесь RNN может просто сбить вас с толку, взглянув на несколько других параметров. CNN — более простая модель, что делает ее более эффективной, чем RNN.
Каковы приложения RNN?
RNN — это довольно мощные модели машинного обучения, которые используются во многих областях. Основная цель RNN — обрабатывать последовательные данные, которые ему доступны. Наличие последовательных данных встречается в различных доменах. Некоторые из его приложений в различных областях включают машинный перевод, распознавание речи, анализ колл-центра, проблемы прогнозирования, суммирование текста, маркировку видео, обнаружение лиц, распознавание изображений, приложения OCR и композицию музыки.
Каковы некоторые ключевые различия между RNN и CNN?
RNN полезны для анализа последовательных и временных данных, таких как видео или текст. С другой стороны, CNN полезен для решения проблем, связанных с пространственными данными, такими как изображения. В RNN размеры входных и выходных данных могут различаться, в то время как в CNN существует фиксированный размер как для входных данных, так и для результирующих выходных данных. Некоторыми вариантами использования RNN являются машинный перевод, анализ речи, анализ настроений и проблемы прогнозирования, в то время как CNN полезны в медицинском анализе, классификации и распознавании лиц.