
Rete neurale ricorrente in Python: guida definitiva per principianti
Pubblicato: 2020-04-27Quando è necessario elaborare sequenze – prezzi azionari giornalieri, misurazioni dei sensori, ecc. – in un programma, è necessaria una rete neurale ricorrente (RNN).
Le RNN sono una sorta di rete neurale in cui l'output di un passaggio viene trasferito come input al nuovo passaggio. Nei sistemi neurali convenzionali, tutte le fonti di dati e gli output sono autonomi l'uno dall'altro. Tuttavia, nei casi come quando è necessario anticipare l'espressione successiva di una frase, sono necessarie le parole precedenti e, di conseguenza, è necessario ricordare le parole passate.
È qui che entra in gioco RNN. Ha creato uno strato nascosto per risolvere questi problemi. L'elemento fondamentale e più significativo di RNN è lo stato Nascosto, che ricorda alcuni dati su una sequenza.
Gli RNN hanno generato risultati accurati in alcune delle più comuni applicazioni del mondo reale: grazie alla loro capacità di gestire il testo in modo efficace, gli RNN sono generalmente utilizzati nelle attività di elaborazione del linguaggio naturale (NLP).
- Riconoscimento vocale
- Traduzione automatica
- Composizione musicale
- Riconoscimento della grafia
- Apprendimento della grammatica
Questo è il motivo per cui le RNN hanno guadagnato un'immensa popolarità nello spazio del deep learning.
Vediamo ora la necessità di reti neurali ricorrenti in Python.
Ottieni la certificazione di machine learning online dalle migliori università del mondo: master, programmi post-laurea per dirigenti e programma di certificazione avanzato in ML e AI per accelerare la tua carriera.
Sommario
Qual è la necessità di RNN in Python?
Per rispondere a questa domanda, dobbiamo prima affrontare i problemi associati a una rete neurale di convoluzione (CNN), chiamata anche reti neurali vaniglia.
Il problema principale con le CNN è che possono funzionare solo per dimensioni predefinite, cioè se accettano input di dimensioni fisse, emettono anche output di dimensioni fisse.
Considerando che, con le RNN, questo problema è facilmente risolvibile. Gli RNN consentono agli sviluppatori di lavorare con sequenze a lunghezza variabile sia per gli input che per gli output.
Di seguito è riportato un'illustrazione dell'aspetto degli RNN:
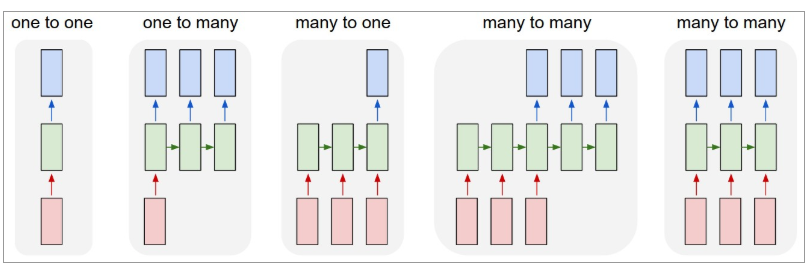
Fonte: Andrej Karpatia
Qui, il colore rosso denota input, RNN verdi e output blu.
Comprendiamo ciascuno in dettaglio.
One-to-one : queste sono anche chiamate reti neurali semplici o vanilla. Funzionano con dimensioni di input fisse a dimensioni di output fisse e sono indipendenti dagli input precedenti.
Esempio : Classificazione dell'immagine.
Uno a molti : mentre le informazioni in input sono di dimensione fissa, l'output è una sequenza di dati.
Esempio : didascalia dell'immagine (l'immagine è in input e l'output è un insieme di parole).
Molti-a-uno : l'input è una sequenza di informazioni e l'output ha una dimensione fissa.
Esempio : Analisi del sentimento (l'input è un insieme di parole e l'output indica se l'insieme di parole riflette un sentimento positivo o negativo).
Molti-a-molti : l'input è una sequenza di informazioni e l'output è una sequenza di dati.
Esempio : traduzione automatica (RNN legge una frase in inglese e fornisce un output della frase nella lingua desiderata).
L'elaborazione di sequenze con lunghezze variabili rende gli RNN così utili. Ecco come:
- Traduzione automatica : il miglior esempio di questo è Google Translate. Funziona su molti-a-molti RNN. Come sapete, il testo originale viene immesso in un RNN, che restituisce il testo tradotto.
- Analisi del sentimento : sai come Google separa le recensioni negative da quelle positive? È ottenuto da un RNN molti-a-uno. Quando il testo viene inserito nell'RNN, fornisce l'output, riflettendo la classe in cui si trova l'input.
Ora vediamo come funzionano gli RNN.
Come funzionano le RNN?
È meglio comprendere il funzionamento di una rete neurale ricorrente in Python guardando un esempio.
Supponiamo che esista una rete più profonda contenente un livello di output, tre livelli nascosti e un livello di input.
Proprio come accade con le altre reti neurali, anche in questo caso ogni livello nascosto avrà il proprio insieme di pesi e distorsioni.
Per il bene di questo esempio, consideriamo che i pesi e le distorsioni per lo strato 1 sono (w1, b1), lo strato 2 sono (w2, b2) e lo strato 3 sono (w3, b3). Questi tre livelli sono indipendenti l'uno dall'altro e non ricordano i risultati precedenti.
Ora, ecco cosa farà la RNN:
- Converte le attivazioni indipendenti in quelle dipendenti facendo in modo che tutti i livelli contengano gli stessi pesi e bias. Ciò, a sua volta, ridurrà la complessità dell'aumento dei parametri e del ricordo di ciascuno dei risultati precedenti fornendo l'output come input al livello nascosto successivo.
- Pertanto, tutti e tre i livelli verranno intrecciati in un unico livello ricorrente per contenere gli stessi pesi e distorsioni.
- Per calcolare lo stato attuale, puoi utilizzare la seguente formula:
Dove,

= stato attuale
= stato precedente
= stato di ingresso
- Per applicare la funzione di Attivazione (tanh), utilizzare la seguente formula:
Dove,
= peso al neurone ricorrente
= peso al neurone di input
- Per calcolare l'output, utilizzare la seguente formula:
Dove,
= uscita
= peso al livello di output
Ecco una spiegazione passo passo di come un RNN può essere addestrato.
- Contemporaneamente, l'input viene fornito alla rete.
- Ora, è necessario calcolare il suo stato corrente utilizzando l'impostazione di input corrente e lo stato precedente.
- La corrente diventerà per il prossimo passo del tempo.
- Puoi eseguire tutti i passaggi temporali che desideri e combinare i dati di tutti gli stati precedenti.
- Non appena tutti i passaggi temporali sono stati completati, utilizzare lo stato corrente finale per calcolare l'uscita finale.
- Confronta questo output con l'output effettivo, ovvero l'output di destinazione e l'errore tra i due.
- Propaga l'errore nella rete e aggiorna i pesi per addestrare l'RNN.
Conclusione
Per concludere, vorrei innanzitutto sottolineare i vantaggi di una rete neurale ricorrente in Python:
- Un RNN può ricordare tutte le informazioni che riceve. Questa è la caratteristica più utilizzata nella previsione in serie in quanto può ricordare gli input precedenti.
- In RNN, la stessa funzione di transizione con gli stessi parametri può essere utilizzata in ogni fase temporale.
È fondamentale capire che la rete neurale ricorrente in Python non ha comprensione del linguaggio. È adeguatamente una macchina avanzata di riconoscimento dei modelli. In ogni caso, a differenza di metodi come le catene di Markov o l'analisi della frequenza, l'RNN fa previsioni dipendenti dall'ordine dei componenti nella sequenza.
Fondamentalmente, se dici che le persone sono solo straordinarie macchine per il riconoscimento di schemi e, in questo modo, il sistema neurale ricorrente si comporta come una macchina umana.
Gli usi delle RNN vanno molto oltre la generazione di contenuti fino alla traduzione automatica, alla didascalia delle immagini e all'identificazione della paternità. Anche se le RNN non possono sostituire gli esseri umani, è possibile che con tutte le più informazioni sull'addestramento e un modello più ampio, un sistema neurale avrebbe la possibilità di integrare nuovi e sensati abstract di brevetti.
Inoltre, se sei interessato a saperne di più sull'apprendimento automatico, dai un'occhiata al programma Executive PG di IIIT-B e upGrad in Machine Learning e AI , progettato per i professionisti che lavorano e offre oltre 450 ore di formazione rigorosa, oltre 30 casi di studio e incarichi , status di Alumni IIIT-B, oltre 5 progetti pratici pratici e assistenza sul lavoro con le migliori aziende.
La CNN è più veloce di RNN?
Se osserviamo il tempo di calcolo di CNN e RNN, la CNN risulta essere molto veloce (~ 5x) rispetto a RNN. Cerchiamo di capirlo meglio con un esempio.
Se una recensione su un ristorante è: "Il servizio è stato incredibilmente lento e sono praticamente deluso da questo ristorante. Anche la qualità del cibo era mediocre.' Qui, ci sono dati sequenziali presenti nella dichiarazione, in cui potresti provare a scoprire se i sentimenti sono buoni o cattivi. Il modello della CNN sarà in grado di rendere i calcoli più veloci qui poiché guarderebbe solo a determinate frasi, come "incredibilmente lento", "mediocre" e "deluso". Qui, RNN potrebbe solo confonderti guardando molti altri parametri. CNN è un modello più semplice, che lo rende più efficiente di RNN.
Quali sono le applicazioni di RNN?
Gli RNN sono modelli di apprendimento automatico piuttosto potenti che vengono utilizzati in molte aree. L'obiettivo principale di RNN è elaborare i dati sequenziali che gli vengono messi a disposizione. La disponibilità di dati sequenziali si trova in vari domini. Alcune delle sue applicazioni in diversi domini includono la traduzione automatica, il riconoscimento vocale, l'analisi del call center, i problemi di previsione, il riepilogo del testo, il tagging dei video, il rilevamento dei volti, il riconoscimento delle immagini, le applicazioni OCR e la composizione musicale.
Quali sono alcune differenze chiave tra RNN e CNN?
Gli RNN sono utili per analizzare dati sequenziali e temporali come video o testo. D'altra parte, la CNN è utile per risolvere problemi relativi a dati spaziali come le immagini. In RNN, le dimensioni di input e output possono variare, mentre in CNN esiste una dimensione fissa per l'input e l'output risultante. Alcuni casi d'uso per le RNN sono la traduzione automatica, l'analisi vocale, l'analisi del sentiment e i problemi di previsione, mentre le CNN sono utili nell'analisi medica, nella classificazione e nel riconoscimento facciale.