
Recurrent Neural Network in Python: Ultimativer Leitfaden für Anfänger
Veröffentlicht: 2020-04-27Wenn Sie Sequenzen – tägliche Aktienkurse, Sensormessungen usw. – in einem Programm verarbeiten müssen, benötigen Sie ein rekurrentes neuronales Netzwerk (RNN).
RNNs sind eine Art neuronales Netzwerk, bei dem die Ausgabe eines Schritts als Eingabe für den neuen Schritt übertragen wird. Bei herkömmlichen neuronalen Systemen sind alle Datenquellen und -ausgaben voneinander unabhängig. In Fällen jedoch, in denen es erforderlich ist, den folgenden Ausdruck eines Satzes zu antizipieren, sind die vorherigen Wörter erforderlich, und folglich besteht die Notwendigkeit, sich an die vergangenen Wörter zu erinnern.
Hier kommt RNN ins Spiel. Es hat eine versteckte Schicht erstellt, um diese Probleme zu lösen. Das grundlegende und wichtigste Element von RNN ist der verborgene Zustand, der sich an einige Daten zu einer Sequenz erinnert.
RNNs haben in einigen der häufigsten realen Anwendungen genaue Ergebnisse generiert: Aufgrund ihrer Fähigkeit, Text effektiv zu verarbeiten, werden RNNs im Allgemeinen in Aufgaben zur Verarbeitung natürlicher Sprache (NLP) verwendet.
- Spracherkennung
- Maschinenübersetzung
- Musik Komposition
- Handschrifterkennung
- Grammatik lernen
Aus diesem Grund haben RNNs im Bereich Deep Learning immense Popularität erlangt.
Sehen wir uns nun die Notwendigkeit wiederkehrender neuronaler Netze in Python an.
Holen Sie sich die Machine Learning-Zertifizierung online von den besten Universitäten der Welt – Master, Executive Post Graduate Programs und Advanced Certificate Program in ML & AI, um Ihre Karriere zu beschleunigen.
Inhaltsverzeichnis
Was ist die Notwendigkeit für RNNs in Python?
Um diese Frage zu beantworten, müssen wir uns zunächst mit den Problemen befassen, die mit einem Convolution Neural Network (CNN), auch Vanilla Neural Nets genannt, verbunden sind.
Das Hauptproblem bei CNNs besteht darin, dass sie nur für vordefinierte Größen arbeiten können, dh wenn sie Eingaben mit fester Größe akzeptieren, geben sie auch Ausgaben mit fester Größe aus.
Mit RNNs lässt sich dieses Problem jedoch leicht lösen. RNNs ermöglichen es Entwicklern, sowohl für Eingaben als auch für Ausgaben mit Sequenzen variabler Länge zu arbeiten.
Unten sehen Sie eine Illustration, wie RNNs aussehen:
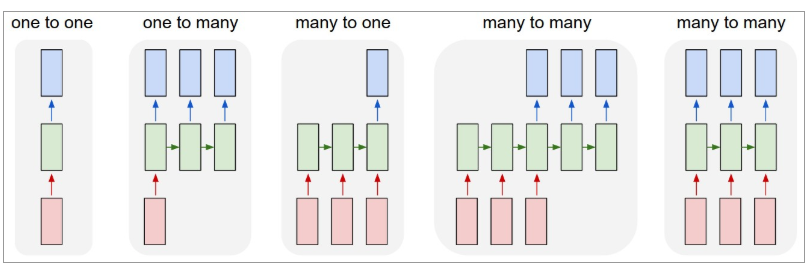
Quelle: Andrej Karpathy
Hier bezeichnet die rote Farbe Eingänge, grüne RNNs und blaue Ausgänge.
Lassen Sie uns jeden im Detail verstehen.
Eins-zu-eins : Diese werden auch als einfache oder einfache neuronale Netze bezeichnet. Sie arbeiten mit fester Eingabegröße zu fester Ausgabegröße und sind unabhängig von vorherigen Eingaben.
Beispiel : Bildklassifizierung.
Eins-zu-viele : Während die Informationen als Eingabe eine feste Größe haben, ist die Ausgabe eine Folge von Daten.
Beispiel : Bildbeschriftung (Bild wird eingegeben, und Ausgabe ist eine Reihe von Wörtern).
Viele-zu-Eins : Die Eingabe ist eine Folge von Informationen und die Ausgabe hat eine feste Größe.
Beispiel : Stimmungsanalyse (Eingabe ist eine Reihe von Wörtern und die Ausgabe gibt an, ob die Wortmenge eine positive oder negative Stimmung widerspiegelt).
Many-to-many : Die Eingabe ist eine Folge von Informationen und die Ausgabe eine Folge von Daten.
Beispiel : Maschinelle Übersetzung (RNN liest einen Satz auf Englisch und gibt den Satz in der gewünschten Sprache aus).
Die Sequenzverarbeitung mit variablen Längen macht RNNs so nützlich. Hier ist wie:
- Maschinelle Übersetzung : Das beste Beispiel dafür ist Google Translate. Es funktioniert auf Many-to-Many-RNNs. Wie Sie wissen, wird der Originaltext in ein RNN eingegeben, das übersetzten Text ergibt.
- Stimmungsanalyse : Sie wissen, wie Google negative Bewertungen von positiven trennt? Es wird durch ein Viele-zu-Eins-RNN erreicht. Wenn der Text in das RNN eingespeist wird, gibt es die Ausgabe, die die Klasse widerspiegelt, in der die Eingabe liegt.
Sehen wir uns nun an, wie RNNs funktionieren.
Wie funktionieren RNNs?
Es ist am besten, die Funktionsweise eines rekurrenten neuronalen Netzwerks in Python anhand eines Beispiels zu verstehen.
Nehmen wir an, dass es ein tieferes Netzwerk gibt, das eine Ausgabeschicht, drei verborgene Schichten und eine Eingabeschicht enthält.
Genau wie bei anderen neuronalen Netzen wird auch in diesem Fall jede verborgene Schicht ihre eigenen Gewichtungen und Vorspannungen haben.
Nehmen wir für dieses Beispiel an, dass die Gewichtungen und Bias für Schicht 1 (w1, b1), Schicht 2 (w2, b2) und Schicht 3 (w3, b3) sind. Diese drei Schichten sind voneinander unabhängig und erinnern sich nicht an die vorherigen Ergebnisse.
Nun, hier ist, was das RNN tun wird:
- Es wandelt die unabhängigen Aktivierungen in abhängige um, indem es dafür sorgt, dass alle Schichten die gleichen Gewichtungen und Vorspannungen enthalten. Dies wiederum reduziert die Komplexität der Erhöhung von Parametern und des Erinnerns an jedes der vorherigen Ergebnisse, indem die Ausgabe als Eingabe an die nächste verborgene Schicht übergeben wird.
- Somit werden alle drei Schichten zu einer einzigen wiederkehrenden Schicht verflochten, um dieselben Gewichtungen und Vorspannungen zu enthalten.
- Um den aktuellen Zustand zu berechnen, können Sie die folgende Formel verwenden:
Woher,

= aktueller Zustand
= vorheriger Zustand
= Eingangszustand
- Um die Aktivierungsfunktion (tanh) anzuwenden, verwenden Sie die folgende Formel:
Woher,
= Gewicht am wiederkehrenden Neuron
= Gewicht am Eingabeneuron
- Um die Ausgabe zu berechnen, verwenden Sie die folgende Formel:
Woher,
= Ausgang
= Gewicht an der Ausgangsschicht
Hier ist eine Schritt-für-Schritt-Erklärung, wie ein RNN trainiert werden kann.
- Zu einem Zeitpunkt wird eine Eingabe an das Netzwerk gegeben.
- Jetzt müssen Sie den aktuellen Zustand anhand des aktuellen Eingabesatzes und des vorherigen Zustands berechnen.
- Der Strom wird für den nächsten Schritt der Zeit.
- Sie können beliebig viele Zeitschritte durchlaufen und die Daten aller vorherigen Zustände kombinieren.
- Sobald alle Zeitschritte abgeschlossen sind, verwenden Sie den endgültigen aktuellen Zustand, um die endgültige Ausgabe zu berechnen.
- Vergleichen Sie diese Ausgabe mit der tatsächlichen Ausgabe, dh der Zielausgabe und dem Fehler zwischen den beiden.
- Geben Sie den Fehler zurück an das Netzwerk weiter und aktualisieren Sie die Gewichtungen, um das RNN zu trainieren.
Fazit
Abschließend möchte ich zunächst auf die Vorteile eines Recurring Neural Network in Python hinweisen:
- Ein RNN kann sich alle empfangenen Informationen merken. Dies ist die Eigenschaft, die bei der Serienvorhersage am häufigsten verwendet wird, da sie sich an die vorherigen Eingaben erinnern kann.
- In RNN kann bei jedem Zeitschritt dieselbe Übergangsfunktion mit denselben Parametern verwendet werden.
Es ist wichtig zu verstehen, dass das rekurrente neuronale Netzwerk in Python kein Sprachverständnis hat. Es ist angemessen eine fortschrittliche Mustererkennungsmaschine. Im Gegensatz zu Methoden wie Markov-Ketten oder Frequenzanalysen macht das RNN auf jeden Fall Vorhersagen abhängig von der Reihenfolge der Komponenten in der Sequenz.
Wenn Sie im Grunde sagen, dass Menschen nur außergewöhnliche Mustererkennungsmaschinen sind und sich das rekurrente neuronale System auf diese Weise nur wie eine Mensch-Maschine verhält.
Die Verwendung von RNNs geht weit über die Generierung von Inhalten hinaus bis hin zu maschineller Übersetzung, Bilduntertitelung und Identifizierung der Urheberschaft. Auch wenn RNNs unmöglich Menschen ersetzen können, ist es möglich, dass ein neuronales System mit mehr Trainingsinformationen und einem größeren Modell die Möglichkeit hätte, neue, sinnvolle Patentzusammenfassungen zu integrieren.
Wenn Sie mehr über maschinelles Lernen erfahren möchten, sehen Sie sich auch das Executive PG-Programm in maschinellem Lernen und KI von IIIT-B & upGrad an, das für Berufstätige konzipiert ist und mehr als 450 Stunden strenge Schulungen, mehr als 30 Fallstudien und Aufgaben bietet , IIIT-B-Alumni-Status, mehr als 5 praktische Schlusssteinprojekte und Arbeitsunterstützung bei Top-Unternehmen.
Ist CNN schneller als RNN?
Wenn wir uns die Rechenzeit sowohl von CNN als auch von RNN ansehen, stellt sich heraus, dass CNN im Vergleich zu RNN sehr schnell (~ 5x) ist. Versuchen wir, dies anhand eines Beispiels besser zu verstehen.
Wenn eine Restaurantbewertung lautet: „Der Service war unglaublich langsam, und ich bin ziemlich enttäuscht von diesem Restaurant. Auch die Qualität der Speisen war mittelmäßig.“ Hier sind sequentielle Daten in der Aussage vorhanden, bei denen Sie möglicherweise versuchen, herauszufinden, ob die Stimmung gut oder schlecht ist. Das CNN-Modell wird die Berechnungen hier schneller machen können, da es nur bestimmte Ausdrücke wie „unglaublich langsam“, „mittelmäßig“ und „enttäuscht“ betrachten würde. Hier könnte RNN Sie nur verwirren, indem es mehrere andere Parameter betrachtet. CNN ist ein einfacheres Modell, das es effizienter macht als RNN.
Was sind die Anwendungen von RNN?
RNNs sind ziemlich leistungsstarke Modelle für maschinelles Lernen, die in vielen Bereichen eingesetzt werden. Das Hauptziel von RNN ist die Verarbeitung der sequentiellen Daten, die ihm zur Verfügung gestellt werden. Die Verfügbarkeit von sequentiellen Daten findet sich in verschiedenen Bereichen. Einige seiner Anwendungen in verschiedenen Bereichen umfassen maschinelle Übersetzung, Spracherkennung, Call-Center-Analyse, Vorhersageprobleme, Textzusammenfassung, Video-Tagging, Gesichtserkennung, Bilderkennung, OCR-Anwendungen und Musikkomposition.
Was sind einige Hauptunterschiede zwischen RNN und CNN?
RNNs sind nützlich, um sequentielle und zeitliche Daten wie Videos oder Text zu analysieren. Andererseits ist CNN nützlich, um Probleme zu lösen, die mit räumlichen Daten wie Bildern zusammenhängen. Bei RNN können die Größen von Eingaben und Ausgaben variieren, während es bei CNN eine feste Größe für die Eingabe sowie die resultierende Ausgabe gibt. Einige Anwendungsfälle für RNNs sind maschinelle Übersetzung, Sprachanalyse, Stimmungsanalyse und Vorhersageprobleme, während CNNs bei der medizinischen Analyse, Klassifizierung und Gesichtserkennung nützlich sind.