
Réseau de neurones récurrent en Python : guide ultime pour les débutants
Publié: 2020-04-27Lorsque vous avez besoin de traiter des séquences - cours de bourse quotidiens, mesures de capteurs, etc. - dans un programme, vous avez besoin d'un réseau de neurones récurrent (RNN).
Les RNN sont une sorte de réseau de neurones où la sortie d'une étape est transférée comme entrée à la nouvelle étape. Dans les systèmes neuronaux conventionnels, toutes les sources de données et les sorties sont autonomes les unes des autres. Cependant, dans des cas comme lorsqu'il est nécessaire d'anticiper l'expression suivante d'une phrase, les mots précédents sont nécessaires, et par conséquent, il est nécessaire de se souvenir des mots passés.
C'est là que RNN entre en scène. Il a créé une couche cachée pour résoudre ces problèmes. L'élément fondamental et le plus important de RNN est l'état caché, qui mémorise certaines données sur une séquence.
Les RNN ont généré des résultats précis dans certaines des applications les plus courantes du monde réel : en raison de leur capacité à gérer efficacement le texte, les RNN sont généralement utilisés dans les tâches de traitement du langage naturel (TAL).
- Reconnaissance de la parole
- Traduction automatique
- Composition musicale
- Reconnaissance de l'écriture manuscrite
- Apprentissage de la grammaire
C'est pourquoi les RNN ont acquis une immense popularité dans l'espace d'apprentissage en profondeur.
Voyons maintenant le besoin de réseaux de neurones récurrents en Python.
Obtenez une certification d'apprentissage automatique en ligne auprès des meilleures universités du monde - Masters, programmes de troisième cycle pour cadres et programme de certificat avancé en ML et IA pour accélérer votre carrière.
Table des matières
Quel est le besoin de RNN en Python ?
Pour répondre à cette question, nous devons d'abord aborder les problèmes associés à un réseau de neurones à convolution (CNN), également appelé réseaux de neurones vanille.
Le problème majeur avec les CNN est qu'ils ne peuvent fonctionner que pour des tailles prédéfinies, c'est-à-dire que s'ils acceptent des entrées de taille fixe, ils donnent également des sorties de taille fixe.
Alors qu'avec les RNN, ce problème est facilement résolu. Les RNN permettent aux développeurs de travailler avec des séquences de longueur variable pour les entrées et les sorties.
Vous trouverez ci-dessous une illustration de ce à quoi ressemblent les RNN :
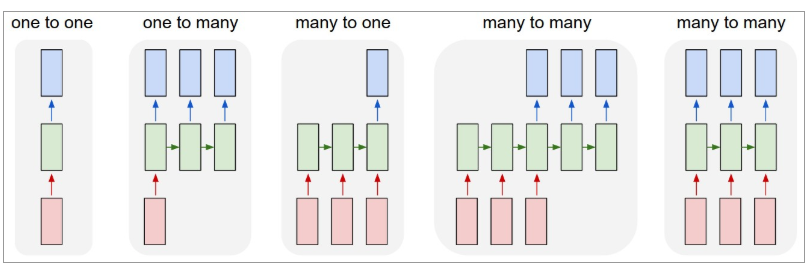
Source : Andrej Karpathy
Ici, la couleur rouge indique les entrées, les RNN verts et les sorties bleues.
Comprenons chacun en détail.
One-to-one : Ceux-ci sont également appelés réseaux de neurones simples ou vanille. Ils fonctionnent avec une taille d'entrée fixe à une taille de sortie fixe et sont indépendants des entrées précédentes.
Exemple : Classement d'images.
One-to-many : alors que les informations en entrée sont de taille fixe, la sortie est une séquence de données.
Exemple : Légende d'image (l'image est une entrée et la sortie est un ensemble de mots).
Many-to-one : L'entrée est une séquence d'informations et la sortie est d'une taille fixe.
Exemple : analyse des sentiments (l'entrée est un ensemble de mots et la sortie indique si l'ensemble de mots reflète un sentiment positif ou négatif).
Plusieurs à plusieurs : L'entrée est une séquence d'informations et la sortie est une séquence de données.
Exemple : Traduction automatique (RNN lit une phrase en anglais et donne une sortie de la phrase dans la langue souhaitée).
Le traitement des séquences avec des longueurs variables rend les RNN si utiles. Voici comment:
- Traduction automatique : Le meilleur exemple en est Google Translate. Cela fonctionne sur plusieurs RNN. Comme vous le savez, le texte original est entré dans un RNN, qui produit le texte traduit.
- Analyse des sentiments : vous savez comment Google sépare les avis négatifs des avis positifs ? Il est réalisé par un RNN plusieurs-à-un. Lorsque le texte est introduit dans le RNN, il donne la sortie, reflétant la classe dans laquelle se trouve l'entrée.
Voyons maintenant comment fonctionnent les RNN.
Comment fonctionnent les RNN ?
Il est préférable de comprendre le fonctionnement d'un réseau de neurones récurrent en Python en regardant un exemple.
Supposons qu'il existe un réseau plus profond contenant une couche de sortie, trois couches cachées et une couche d'entrée.
Tout comme c'est le cas avec d'autres réseaux de neurones, dans ce cas également, chaque couche cachée sera accompagnée de son propre ensemble de poids et de biais.
Pour cet exemple, considérons que les pondérations et les biais de la couche 1 sont (w1, b1), la couche 2 est (w2, b2) et la couche 3 est (w3, b3). Ces trois couches sont indépendantes les unes des autres et ne mémorisent pas les résultats précédents.
Maintenant, voici ce que le RNN fera :
- Il convertira les activations indépendantes en activations dépendantes en faisant en sorte que toutes les couches contiennent les mêmes poids et biais. Cela réduira à son tour la complexité de l'augmentation des paramètres et de la mémorisation de chacun des résultats précédents en donnant la sortie comme entrée à la couche cachée suivante.
- Ainsi, les trois couches seront entrelacées en une seule couche récurrente pour contenir les mêmes poids et biais.
- Pour calculer l'état actuel, vous pouvez utiliser la formule suivante :
Où,

= état actuel
= état précédent
= état d'entrée
- Pour appliquer la fonction d'activation (tanh), utilisez la formule suivante :
Où,
= poids au niveau du neurone récurrent
= poids au neurone d'entrée
- Pour calculer la sortie, utilisez la formule suivante :
Où,
= sortie
= poids à la couche de sortie
Voici une explication étape par étape de la façon dont un RNN peut être formé.
- À un moment donné, une entrée est donnée au réseau.
- Maintenant, vous devez calculer son état actuel en utilisant le jeu d'entrée actuel et l'état précédent.
- Le courant deviendra pour la prochaine étape du temps.
- Vous pouvez parcourir autant de pas de temps que vous le souhaitez et combiner les données de tous les états précédents.
- Dès que toutes les étapes de temps sont terminées, utilisez l'état actuel final pour calculer la sortie finale.
- Comparez cette sortie à la sortie réelle, c'est-à-dire la sortie cible et l'erreur entre les deux.
- Propager l'erreur sur le réseau et mettre à jour les pondérations pour former le RNN.
Conclusion
Pour conclure, je voudrais d'abord souligner les avantages d'un réseau de neurones récurrent en Python :
- Un RNN peut mémoriser toutes les informations qu'il reçoit. C'est la caractéristique la plus utilisée dans la prédiction de séries car elle peut mémoriser les entrées précédentes.
- Dans RNN, la même fonction de transition avec les mêmes paramètres peut être utilisée à chaque pas de temps.
Il est essentiel de comprendre que le réseau neuronal récurrent en Python n'a aucune compréhension du langage. C'est à juste titre une machine de reconnaissance de formes avancée. Dans tous les cas, contrairement aux méthodes telles que les chaînes de Markov ou l'analyse fréquentielle, le RNN rend les prédictions dépendantes de l'ordre des composants dans la séquence.
Fondamentalement, si vous dites que les gens ne sont que des machines de reconnaissance de formes extraordinaires et que, de cette manière, le système neuronal récurrent agit simplement comme une machine humaine.
Les utilisations des RNN vont bien au-delà de la génération de contenu jusqu'à la traduction automatique, le sous-titrage d'images et l'identification de l'auteur. Même si les RNN ne peuvent pas remplacer les humains, il est possible qu'avec plus d'informations de formation et un modèle plus grand, un système neuronal ait la possibilité d'intégrer de nouveaux abrégés de brevets sensés.
De plus, si vous souhaitez en savoir plus sur l'apprentissage automatique, consultez le programme Executive PG d'IIIT-B & upGrad en apprentissage automatique et IA , conçu pour les professionnels en activité et offrant plus de 450 heures de formation rigoureuse, plus de 30 études de cas et missions. , statut IIIT-B Alumni, plus de 5 projets de synthèse pratiques et aide à l'emploi avec les meilleures entreprises.
CNN est-il plus rapide que RNN ?
Si nous examinons le temps de calcul de CNN et de RNN, CNN s'avère très rapide (~ 5x) par rapport à RNN. Essayons de mieux comprendre cela avec un exemple.
Si une critique de restaurant est : « Le service a été incroyablement lent, et je suis assez déçu de ce restaurant. La qualité de la nourriture était également médiocre. Ici, il y a des données séquentielles présentes dans la déclaration, où vous pourriez essayer de savoir si les sentiments sont bons ou mauvais. Le modèle CNN sera en mesure d'accélérer les calculs ici car il ne regarderait que certaines phrases, telles que "incroyablement lent", "médiocre" et "déçu". Ici, RNN pourrait simplement vous confondre en regardant plusieurs autres paramètres. CNN est un modèle plus simple, ce qui le rend plus efficace que RNN.
Quelles sont les applications du RNN ?
Les RNN sont des modèles d'apprentissage automatique assez puissants qui sont utilisés dans de nombreux domaines. L'objectif principal de RNN est de traiter les données séquentielles qui sont mises à sa disposition. La disponibilité des données séquentielles se retrouve dans divers domaines. Certaines de ses applications dans différents domaines incluent la traduction automatique, la reconnaissance vocale, l'analyse des centres d'appels, les problèmes de prédiction, le résumé de texte, le marquage vidéo, la détection de visage, la reconnaissance d'image, les applications OCR et la composition musicale.
Quelles sont les principales différences entre RNN et CNN ?
Les RNN sont utiles pour analyser des données séquentielles et temporelles comme des vidéos ou du texte. D'autre part, CNN est utile pour résoudre des problèmes liés à des données spatiales telles que des images. Dans RNN, les tailles des entrées et des sorties peuvent varier, tandis que dans CNN, il existe une taille fixe pour l'entrée ainsi que la sortie résultante. Certains cas d'utilisation des RNN sont la traduction automatique, l'analyse de la parole, l'analyse des sentiments et les problèmes de prédiction, tandis que les CNN sont utiles dans l'analyse médicale, la classification et la reconnaissance faciale.