
Rede neural recorrente em Python: guia definitivo para iniciantes
Publicados: 2020-04-27Quando você precisa processar sequências – preços diários de ações, medições de sensores, etc. – em um programa, você precisa de uma rede neural recorrente (RNN).
As RNNs são uma espécie de Rede Neural onde a saída de uma etapa é transferida como entrada para a nova etapa. Em sistemas neurais convencionais, todas as fontes de dados e saídas são autônomas umas das outras. No entanto, em casos como quando é necessário antecipar a expressão seguinte de uma frase, as palavras anteriores são necessárias e, consequentemente, há a necessidade de relembrar as palavras passadas.
É aqui que o RNN entra em cena. Ele criou uma camada oculta para resolver esses problemas. O elemento fundamental e mais significativo do RNN é o estado oculto, que lembra alguns dados sobre uma sequência.
As RNNs têm gerado resultados precisos em algumas das aplicações mais comuns do mundo real: Devido à sua capacidade de lidar com texto de forma eficaz, as RNNs geralmente são usadas em tarefas de processamento de linguagem natural (NLP).
- Reconhecimento de fala
- Maquina de tradução
- Composição musical
- Reconhecimento de caligrafia
- Aprendizagem de gramática
É por isso que as RNNs ganharam imensa popularidade no espaço de aprendizado profundo.
Agora vamos ver a necessidade de redes neurais recorrentes em Python.
Obtenha a Certificação de Aprendizado de Máquina online das principais universidades do mundo - Mestrados, Programas de Pós-Graduação Executiva e Programa de Certificado Avançado em ML e IA para acelerar sua carreira.
Índice
Qual é a necessidade de RNNs em Python?
Para responder a essa pergunta, primeiro precisamos abordar os problemas associados a uma Rede Neural de Convolução (CNN), também chamada de redes neurais de baunilha.
O grande problema com as CNNs é que elas só funcionam para tamanhos pré-definidos, ou seja, se aceitam entradas de tamanho fixo, também fornecem saídas de tamanho fixo.
Considerando que, com RNNs, esse problema é facilmente resolvido. As RNNs permitem que os desenvolvedores trabalhem com sequências de comprimento variável para entradas e saídas.
Abaixo está uma ilustração de como as RNNs se parecem:
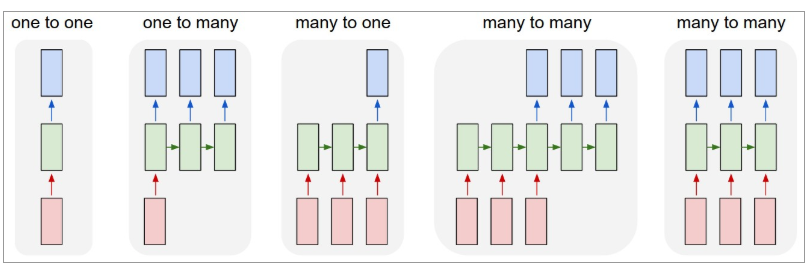
Fonte: Andrej Karpathy
Aqui, a cor vermelha denota entradas, RNNs verdes e saídas azuis.
Vamos entender cada um em detalhes.
Um-para-um : também são chamadas de redes neurais simples ou baunilha. Eles trabalham com tamanho de entrada fixo para tamanho de saída fixo e são independentes das entradas anteriores.
Exemplo : Classificação de imagens.
Um-para-muitos : Enquanto a informação como entrada é de tamanho fixo, a saída é uma sequência de dados.
Exemplo : Legendagem de imagem (a imagem é entrada e a saída é um conjunto de palavras).
Muitos para um : A entrada é uma sequência de informações e a saída é de tamanho fixo.
Exemplo : Análise de sentimento (entrada é um conjunto de palavras e saída informa se o conjunto de palavras reflete um sentimento positivo ou negativo).
Muitos para muitos : A entrada é uma sequência de informações e a saída é uma sequência de dados.
Exemplo : Tradução automática (RNN lê uma frase em inglês e dá uma saída da frase no idioma desejado).
O processamento de sequência com comprimentos variáveis torna as RNNs tão úteis. Veja como:
- Tradução automática : O melhor exemplo disso é o Google Tradutor. Funciona em muitos-para-muitos RNNs. Como você sabe, o texto original é inserido em uma RNN, que produz o texto traduzido.
- Análise de sentimento : Você sabe como o Google separa as avaliações negativas das positivas? É alcançado por um RNN muitos-para-um. Quando o texto é alimentado no RNN, ele fornece a saída, refletindo a classe na qual a entrada se encontra.
Agora vamos ver como as RNNs funcionam.
Como funcionam as RNNs?
É melhor entender o funcionamento de uma rede neural recorrente em Python observando um exemplo.
Vamos supor que haja uma rede mais profunda contendo uma camada de saída, três camadas ocultas e uma camada de entrada.
Assim como acontece com outras redes neurais, também neste caso, cada camada oculta virá com seu próprio conjunto de pesos e vieses.
Para este exemplo, vamos considerar que os pesos e desvios para a camada 1 são (w1, b1), a camada 2 é (w2, b2) e a camada 3 é (w3, b3). Essas três camadas são independentes umas das outras e não lembram dos resultados anteriores.
Agora, aqui está o que o RNN fará:
- Ele converterá as ativações independentes em dependentes, fazendo com que todas as camadas contenham os mesmos pesos e vieses. Isso, por sua vez, reduzirá a complexidade de aumentar os parâmetros e lembrar cada um dos resultados anteriores, fornecendo a saída como entrada para a próxima camada oculta.
- Assim, todas as três camadas serão entrelaçadas em uma única camada recorrente para conter os mesmos pesos e vieses.
- Para calcular o estado atual, você pode usar a seguinte fórmula:
Onde,

= estado atual
= estado anterior
= estado de entrada
- Para aplicar a função de ativação (tanh), use a seguinte fórmula:
Onde,
= peso no neurônio recorrente
= peso no neurônio de entrada
- Para calcular a saída, use a seguinte fórmula:
Onde,
= saída
= peso na camada de saída
Aqui está uma explicação passo a passo de como um RNN pode ser treinado.
- Ao mesmo tempo, a entrada é fornecida à rede.
- Agora, você precisa calcular seu estado atual usando o conjunto de entrada atual e o estado anterior.
- A corrente se tornará para o próximo passo do tempo.
- Você pode ir quantas etapas de tempo quiser e combinar os dados de todos os estados anteriores.
- Assim que todas as etapas de tempo forem concluídas, use o estado atual final para calcular a saída final.
- Compare esta saída com a saída real, ou seja, a saída alvo e o erro entre as duas.
- Propague o erro de volta para a rede e atualize os pesos para treinar o RNN.
Conclusão
Para concluir, primeiro gostaria de apontar as vantagens de uma Rede Neural Recorrente em Python:
- Um RNN pode lembrar de todas as informações que recebe. Esta é a característica mais utilizada na predição em série, pois pode lembrar as entradas anteriores.
- Em RNN, a mesma função de transição com os mesmos parâmetros pode ser usada em cada passo de tempo.
É fundamental entender que a rede neural recorrente em Python não tem compreensão de linguagem. É adequadamente uma máquina avançada de reconhecimento de padrões. De qualquer forma, ao contrário de métodos como cadeias de Markov ou análise de frequência, o RNN faz previsões dependentes da ordenação dos componentes na sequência.
Basicamente, se você disser que as pessoas são apenas máquinas extraordinárias de reconhecimento de padrões e, dessa maneira, o sistema neural recorrente está apenas agindo como um homem-máquina.
Os usos de RNNs vão muito além da geração de conteúdo para tradução automática, legendagem de imagens e identificação de autoria. Embora as RNNs não possam substituir os humanos, é possível que, com mais informações de treinamento e um modelo maior, um sistema neural tenha a opção de integrar novos e sensatos resumos de patentes.
Além disso, se você estiver interessado em aprender mais sobre aprendizado de máquina, confira o Programa PG Executivo do IIIT-B e do upGrad em aprendizado de máquina e IA , projetado para profissionais que trabalham e oferece mais de 450 horas de treinamento rigoroso, mais de 30 estudos de caso e atribuições , IIIT-B Alumni status, mais de 5 projetos práticos práticos e assistência de trabalho com as principais empresas.
A CNN é mais rápida que a RNN?
Se observarmos o tempo de computação da CNN e da RNN, a CNN é muito rápida (~ 5x) em comparação com a RNN. Vamos tentar entender isso de uma maneira melhor com um exemplo.
Se uma avaliação de restaurante for: 'O serviço foi incrivelmente lento e estou bastante decepcionado com este restaurante. A qualidade da comida também era medíocre.' Aqui, há dados sequenciais presentes na declaração, onde você pode estar tentando descobrir se os sentimentos são bons ou ruins. O modelo da CNN será capaz de tornar os cálculos mais rápidos aqui, pois estaria olhando apenas para certas frases, como 'incrivelmente lento', 'medíocre' e 'decepcionado'. Aqui, o RNN pode confundir você ao observar vários outros parâmetros. A CNN é um modelo mais simples, o que a torna mais eficiente que a RNN.
Quais são as aplicações do RNN?
As RNNs são modelos de aprendizado de máquina bastante poderosos que estão sendo usados em muitas áreas. O principal objetivo da RNN é processar os dados sequenciais que lhe são disponibilizados. A disponibilidade de dados sequenciais é encontrada em vários domínios. Algumas de suas aplicações em diferentes domínios incluem tradução automática, reconhecimento de fala, análise de call center, problemas de previsão, resumo de texto, marcação de vídeo, detecção de rosto, reconhecimento de imagem, aplicativos de OCR e composição de música.
Quais são algumas das principais diferenças entre RNN e CNN?
RNNs são úteis para analisar dados sequenciais e temporais, como vídeos ou texto. Por outro lado, a CNN é útil para resolver problemas relacionados a dados espaciais como imagens. Na RNN, os tamanhos das entradas e saídas podem variar, enquanto na CNN, há um tamanho fixo para entrada e saída resultante. Alguns casos de uso para RNNs são tradução automática, análise de fala, análise de sentimentos e problemas de previsão, enquanto as CNNs são úteis em análise médica, classificação e reconhecimento facial.