
Red neuronal recurrente en Python: la guía definitiva para principiantes
Publicado: 2020-04-27Cuando necesita procesar secuencias (precios de acciones diarios, mediciones de sensores, etc.) en un programa, necesita una red neuronal recurrente (RNN).
Los RNN son una especie de red neuronal donde la salida de un paso se transfiere como entrada al nuevo paso. En los sistemas neuronales convencionales, todas las fuentes y salidas de datos son independientes entre sí. Sin embargo, en casos como cuando se requiere anticipar la siguiente expresión de una oración, se requieren las palabras anteriores y, en consecuencia, existe la necesidad de recordar las palabras pasadas.
Aquí es donde RNN entra en escena. Creó una capa oculta para resolver estos problemas. El elemento fundamental y más significativo de RNN es el estado Oculto, que recuerda algunos datos sobre una secuencia.
Los RNN han estado generando resultados precisos en algunas de las aplicaciones más comunes del mundo real: debido a su capacidad para manejar texto de manera efectiva, los RNN generalmente se usan en tareas de procesamiento de lenguaje natural (NLP).
- Reconocimiento de voz
- Máquina traductora
- Composición musical
- Reconocimiento de escritura a mano
- aprendizaje de gramática
Esta es la razón por la que las RNN han ganado una inmensa popularidad en el espacio del aprendizaje profundo.
Ahora veamos la necesidad de redes neuronales recurrentes en Python.
Obtenga la certificación de aprendizaje automático en línea de las principales universidades del mundo: maestrías, programas ejecutivos de posgrado y programa de certificado avanzado en ML e IA para acelerar su carrera.
Tabla de contenido
¿Cuál es la necesidad de RNN en Python?
Para responder a esta pregunta, primero debemos abordar los problemas asociados con una red neuronal de convolución (CNN), también denominada redes neuronales vainilla.
El principal problema de las CNN es que solo pueden funcionar para tamaños predefinidos, es decir, si aceptan entradas de tamaño fijo, también proporcionan salidas de tamaño fijo.
Mientras que, con RNN, este problema se soluciona fácilmente. Los RNN permiten a los desarrolladores trabajar con secuencias de longitud variable tanto para entradas como para salidas.
A continuación se muestra una ilustración de cómo se ven los RNN:
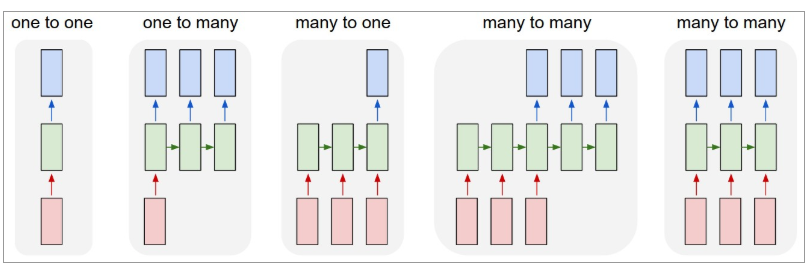
Fuente: Andrej Karpatia
Aquí, el color rojo denota entradas, RNN verdes y salidas azules.
Entendamos cada uno en detalle.
Uno a uno : también se denominan redes neuronales simples o vainilla. Funcionan con un tamaño de entrada fijo a un tamaño de salida fijo y son independientes de las entradas anteriores.
Ejemplo : clasificación de imágenes.
Uno a muchos : mientras que la información de entrada tiene un tamaño fijo, la salida es una secuencia de datos.
Ejemplo : subtítulos de imágenes (la imagen es entrada y la salida es un conjunto de palabras).
Muchos a uno : la entrada es una secuencia de información y la salida tiene un tamaño fijo.
Ejemplo : análisis de sentimiento (la entrada es un conjunto de palabras y la salida indica si el conjunto de palabras refleja un sentimiento positivo o negativo).
Muchos a muchos : la entrada es una secuencia de información y la salida es una secuencia de datos.
Ejemplo : traducción automática (RNN lee una oración en inglés y da una salida de la oración en el idioma deseado).
El procesamiento de secuencias con longitudes variables hace que las RNN sean muy útiles. Así es cómo:
- Traducción automática : el mejor ejemplo de esto es Google Translate. Funciona en RNN de muchos a muchos. Como sabe, el texto original se ingresa en un RNN, que produce el texto traducido.
- Análisis de sentimiento : ¿Sabes cómo Google separa las críticas negativas de las positivas? Se logra mediante un RNN de muchos a uno. Cuando el texto se introduce en el RNN, da la salida, lo que refleja la clase en la que se encuentra la entrada.
Ahora veamos cómo funcionan los RNN.
¿Cómo funcionan los RNN?
Lo mejor es comprender el funcionamiento de una red neuronal recurrente en Python mirando un ejemplo.
Supongamos que hay una red más profunda que contiene una capa de salida, tres capas ocultas y una capa de entrada.
Al igual que con otras redes neuronales, en este caso también cada capa oculta vendrá con su propio conjunto de pesos y sesgos.
Por el bien de este ejemplo, consideremos que los pesos y sesgos para la capa 1 son (w1, b1), la capa 2 son (w2, b2) y la capa 3 son (w3, b3). Estas tres capas son independientes entre sí y no recuerdan los resultados anteriores.
Ahora, esto es lo que hará la RNN:
- Convertirá las activaciones independientes en dependientes haciendo que todas las capas contengan los mismos pesos y sesgos. Esto, a su vez, reducirá la complejidad de aumentar los parámetros y recordar cada uno de los resultados anteriores al dar la salida como entrada a la siguiente capa oculta.
- Por lo tanto, las tres capas se entrelazarán en una sola capa recurrente para contener los mismos pesos y sesgos.
- Para calcular el estado actual, puede utilizar la siguiente fórmula:
Donde,

= estado actual
= estado anterior
= estado de entrada
- Para aplicar la función Activación (tanh), utilice la siguiente fórmula:
Donde,
= peso en la neurona recurrente
= peso en la neurona de entrada
- Para calcular la salida, use la siguiente fórmula:
Donde,
= salida
= peso en la capa de salida
Aquí hay una explicación paso a paso de cómo se puede entrenar un RNN.
- En un momento, se da entrada a la red.
- Ahora, debe calcular su estado actual utilizando el conjunto de entrada actual y el estado anterior.
- La corriente se volverá para el próximo paso del tiempo.
- Puede recorrer tantos pasos de tiempo como desee y combinar los datos de todos los estados anteriores.
- Tan pronto como se completen todos los pasos de tiempo, use el estado actual final para calcular la salida final.
- Compare esta salida con la salida real, es decir, la salida objetivo y el error entre las dos.
- Propaga el error a la red y actualiza los pesos para entrenar el RNN.
Conclusión
Para concluir, primero me gustaría señalar las ventajas de una Red Neuronal Recurrente en Python:
- Un RNN puede recordar toda la información que recibe. Esta es la característica que más se utiliza en la predicción de series ya que puede recordar las entradas anteriores.
- En RNN, se puede usar la misma función de transición con los mismos parámetros en cada paso de tiempo.
Es fundamental comprender que la red neuronal recurrente en Python no comprende el idioma. Es adecuadamente una máquina avanzada de reconocimiento de patrones. En cualquier caso, a diferencia de métodos como las cadenas de Markov o el análisis de frecuencia, la RNN hace predicciones que dependen del orden de los componentes en la secuencia.
Básicamente, si dices que las personas son solo máquinas extraordinarias de reconocimiento de patrones y, de esta manera, el sistema neuronal recurrente está actuando como una máquina humana.
Los usos de RNN van mucho más allá de la generación de contenido a la traducción automática, los subtítulos de imágenes y la identificación de autoría. Aunque los RNN no pueden reemplazar a los humanos, es posible que con más información de entrenamiento y un modelo más grande, un sistema neuronal tenga la opción de integrar resúmenes de patentes nuevos y sensatos.
Además, si está interesado en obtener más información sobre el aprendizaje automático, consulte el programa Executive PG de IIIT-B y upGrad en aprendizaje automático e IA, que está diseñado para profesionales que trabajan y ofrece más de 450 horas de capacitación rigurosa, más de 30 estudios de casos y asignaciones. , estado de exalumno de IIIT-B, más de 5 proyectos prácticos finales y asistencia laboral con las mejores empresas.
¿Es la CNN más rápida que la RNN?
Si observamos el tiempo de cálculo de CNN y RNN, se encuentra que CNN es muy rápido (~ 5x) en comparación con RNN. Tratemos de entender esto de una mejor manera con un ejemplo.
Si la reseña de un restaurante es: "El servicio ha sido increíblemente lento y estoy bastante decepcionado con este restaurante". La calidad de la comida también fue mediocre.' Aquí, hay datos secuenciales presentes en la declaración, en los que podría estar tratando de averiguar si los sentimientos son buenos o malos. El modelo CNN podrá hacer que los cálculos sean más rápidos aquí, ya que solo observaría ciertas frases, como 'increíblemente lento', 'mediocre' y 'decepcionado'. Aquí, RNN podría confundirlo al observar varios otros parámetros. CNN es un modelo más simple, lo que lo hace más eficiente que RNN.
¿Cuáles son las aplicaciones de RNN?
Los RNN son modelos de aprendizaje automático bastante potentes que se utilizan en muchas áreas. El objetivo principal de RNN es procesar los datos secuenciales que se le ponen a su disposición. La disponibilidad de datos secuenciales se encuentra en varios dominios. Algunas de sus aplicaciones en diferentes dominios incluyen traducción automática, reconocimiento de voz, análisis de centros de llamadas, problemas de predicción, resumen de texto, etiquetado de video, detección de rostros, reconocimiento de imágenes, aplicaciones OCR y composición musical.
¿Cuáles son algunas diferencias clave entre RNN y CNN?
Los RNN son útiles para analizar datos secuenciales y temporales como videos o texto. Por otro lado, CNN es útil para resolver problemas relacionados con datos espaciales como imágenes. En RNN, los tamaños de entradas y salidas pueden variar, mientras que en CNN, hay un tamaño fijo tanto para la entrada como para la salida resultante. Algunos casos de uso de las RNN son la traducción automática, el análisis del habla, el análisis de sentimientos y los problemas de predicción, mientras que las CNN son útiles en el análisis médico, la clasificación y el reconocimiento facial.