จาก Jr Data Scientist/Machine learning ถึง Data Scientist/Machine Learning Engineer ผู้เชี่ยวชาญ
เผยแพร่แล้ว: 2020-12-07จาก Jr Data Scientist/Machine learning ถึง Full-stack Data Scientist/Machine learning engineer
แนวโน้มปัจจุบันในสาขา Data Science เปลี่ยนไปอย่างมากเมื่อเทียบกับเมื่อสามหรือสองปีที่แล้ว เส้นโค้งการเรียนรู้ไม่ควรสิ้นสุด ดังนั้นเพื่อที่จะเติบโต เราต้องพัฒนาชุดทักษะที่เหมาะสมเพื่อตอบสนองความคาดหวังของอุตสาหกรรมในปัจจุบัน
“การปรับตัวเป็นเรื่องเกี่ยวกับความแตกต่างอันทรงพลังระหว่างการปรับตัวเพื่อรับมือและปรับตัวเพื่อชัยชนะ” — แม็กซ์แมคคีโอว์น
ให้เราดูองค์ประกอบสำคัญที่สามารถช่วยเราในการย้ายจาก Jr Data Scientist / Machine learning ไปเป็น Full stack Data Scientist/Machine learning
สารบัญ
ความคาดหวังในอดีต
สิ่งสำคัญคือต้องเข้าใจความรับผิดชอบในอดีตในการปรับตัวให้เข้ากับความคาดหวังในปัจจุบันของอุตสาหกรรม โดยสรุปแล้ว บทบาทในแต่ละวันของนักวิทยาศาสตร์ข้อมูลในอดีตมักเกี่ยวข้องกับ:
- พื้นที่ AI ยังค่อนข้างใหม่ (แต่ไม่ใช่ในด้านวิชาการ) และหลายบริษัท สตาร์ทอัพกำลังวิเคราะห์แอปพลิเคชันและกรณีการใช้งานที่ถูกต้อง
- การวิจัยเป็นจุดสนใจหลัก ข้อแม้คืองานวิจัยนี้หลายครั้งไม่สอดคล้องกับแกนหลักขององค์กรโดยตรง ดังนั้นในตอนแรกจึงไม่คาดหวังความน่าเชื่อถือมากนัก
- โดยทั่วไป บริษัทต่างๆ เคยผสมผสานบทบาทของนักวิทยาศาสตร์ข้อมูลกับนักวิเคราะห์ข้อมูลหรือวิศวกรข้อมูล อีกครั้งเนื่องจากความคลุมเครือของแอปพลิเคชันระดับองค์กร AI
- บุคคลก็มีภาวะที่กลืนไม่เข้าคายไม่ออกเช่นเดียวกัน งานวิจัยหรืองานจำนวนมากของพวกเขาไม่ได้เกี่ยวข้องโดยตรง ในทางปฏิบัติไม่สามารถทำหน้าที่เป็นผลิตภัณฑ์ได้
แนวโน้มปัจจุบัน
การทำให้เป็นประชาธิปไตยของ AI ได้เห็นการพัฒนาที่โดดเด่นจากบริษัทและสตาร์ทอัพ เรามาลองทำความเข้าใจกัน
- อุตสาหกรรมนี้ทำให้บทบาทของนักวิทยาศาสตร์ข้อมูล วิศวกรการเรียนรู้ของเครื่องจักร นักวิเคราะห์ข้อมูล วิศวกรข้อมูล หรือแม้แต่วิศวกร MLops แตกต่างออกไป
- ธุรกิจต่างๆ ไม่อนุญาตให้มีการวิจัยอย่างดุเดือดอีกต่อไป เนื่องจากพวกเขารู้ว่าพวกเขากำลังใช้กรณีการใช้งานใดอยู่ จำเป็นต้องมีกรอบความคิดที่ชัดเจนและแนวทางที่ไม่ต่อเนื่องที่คล้ายกันจากแต่ละบุคคล
- ทุกการวิจัยหรือ POC ต้องมีผลิตภัณฑ์ที่เป็นรูปธรรมและแสดงผลได้
อ่านเพิ่มเติม: อาชีพในการเรียนรู้ของเครื่อง
การผ่าอย่างถี่ถ้วนของบทบาททั้งหมด
หากเราต้องเลือกด้านใดด้านหนึ่งที่ธุรกิจมีความเป็นเลิศในด้าน AI ไม่ต้องสงสัยเลยว่าบทบาทต่างๆ ที่หลากหลายจะมีความคาดหวังอย่างชัดเจน โดยสรุป:
- นักวิทยาศาสตร์ข้อมูล: Data Scientist คือบุคคลที่ (โดยทั่วไปมาจากพื้นฐานทางสถิติ/คณิตศาสตร์) ใช้วิธีการต่างๆ รวมถึง AI เพื่อดึงข้อมูลที่มีค่าจากข้อมูล
- ความแตกต่างพื้นฐานระหว่าง Data Analyst และ Data Scientist คือ โดยทั่วไปแล้วจะใช้ความรู้ในโดเมนและวิธีแบบเก่าที่ใช้เองในการทำความเข้าใจข้อมูลในระดับขนาดเล็กถึงขนาดกลาง ในขณะที่ส่วนหลังมีหน้าที่รับผิดชอบในการรวบรวม วิเคราะห์ และตีความข้อมูลในขนาดที่ใหญ่ขึ้น โดยใช้เครื่องมือต่างๆ เช่น AI, SQL, คู่มือแบบเก่า เป็นต้น
- ความรู้ด้านโดเมนไม่จำเป็นแต่การมีไว้เพื่อเป็นประโยชน์
- งานหลักคือการรักษาและดึงข้อมูลเชิงลึกของธุรกิจจากข้อมูล ไม่ใช่เพื่อพัฒนาซอฟต์แวร์หรือผลิตภัณฑ์
- นักสถิติหรือนักคณิตศาสตร์สามารถเป็นนักวิทยาศาสตร์ข้อมูลที่ดีได้
2. Machine Learning Engineer: วิศวกรซอฟต์แวร์เฉพาะกลุ่มที่พัฒนาผลิตภัณฑ์หรือบริการโดยใช้ AI
- วิศวกร ML จำเป็นต้องมีความเชี่ยวชาญด้านวิศวกรรมซอฟต์แวร์แบบเดิมทั้งหมดพร้อมกับความรู้ด้าน AI เพราะเขา/เธอกำลังจะสร้างซอฟต์แวร์ที่มี AI เป็นหัวใจหลักในที่สุด
- งานหลักไม่ใช่การดึงข้อมูล แต่เพื่อพัฒนาเครื่องมือ AI ที่สามารถทำงานเดียวกันได้
- นักพัฒนาที่มีความรู้ดีเกี่ยวกับแมชชีนเลิร์นนิง/การเรียนรู้เชิงลึก รวมถึงวิศวกรรมซอฟต์แวร์สามารถเป็นวิศวกรแมชชีนเลิร์นนิงที่ดีได้
3. Machine Learning Operation Engineer: วิศวกรซอฟต์แวร์เฉพาะที่ดูแลและทำให้ไปป์ไลน์ที่ใช้โดยระบบ ML เป็นไปโดยอัตโนมัติ
- ฟิลด์ที่ค่อนข้างใหม่ที่ได้รับแรงบันดาลใจจาก DevOps แม้ว่าจะแตกต่างจากบทบาท DevOps แบบดั้งเดิม
- ไม่เหมือนกับวิศวกรรมซอฟต์แวร์ทั่วไป การพัฒนาผลิตภัณฑ์/ซอฟต์แวร์/บริการใดๆ ที่ใช้ AI ไม่ได้หยุดอยู่ที่การสร้างซอฟต์แวร์ให้เสร็จสมบูรณ์ จะต้องมีการอัปเดตเป็นประจำด้วยข้อมูลใหม่ ซึ่งก็คือ 'Data-Drift'
- งานหลักรวมถึงงาน DevOps แบบเดิมๆ ทั้งหมด รวมถึงการดูแล/ทำให้ไปป์ไลน์อัตโนมัติและ Data-Drift
- นักพัฒนาที่มีความรู้ดีเกี่ยวกับแมชชีนเลิร์นนิง/การเรียนรู้เชิงลึก วิศวกรรมซอฟต์แวร์ และเทคโนโลยีคลาวด์สามารถเป็นวิศวกร MlOps ที่ดีได้
สำหรับผู้หางานใหม่หรือผู้ที่ต้องการความก้าวหน้าในอาชีพการงาน บทบาทและความคาดหวังเหล่านี้ต้องเข้าใจเป็นอย่างดี เนื่องจากบริษัทต่างๆ ได้แยกแยะบทบาทนี้อย่างชัดเจน จึงคาดว่าจะเป็นกรณีนี้สำหรับบุคคล ความคิดที่คลุมเครือนั้นไร้ประโยชน์โดยสิ้นเชิง
สแต็คของระบบการเรียนรู้ของเครื่องแบบเต็มสแต็ก
ตอนนี้ให้เราย้ายไปยังจุดสำคัญ ในการเป็น Full stack Machine Learning Engineer จำเป็นต้องเข้าใจแนวคิดเบื้องหลัง Stack

Full stack คืออะไร?
- เช่นเดียวกับวิศวกรรมซอฟต์แวร์ทั่วไป การพัฒนาระบบที่ใช้ AI ก็ต้องการชุดเครื่องมือเช่นกัน ชุดที่สมบูรณ์นี้สามารถเรียกว่า Full Stack
- โดยทั่วไปแล้ว สแต็กแบบเต็มถูกสร้างขึ้นโดยใช้หน่วยการสร้างสามส่วน ได้แก่ เทคโนโลยีคลาวด์ เทคโนโลยีการกำกับดูแล และเทคโนโลยี AI
- มีองค์ประกอบหลายอย่างสำหรับการสร้างระบบ AI ในหน่วยการสร้างทั้งสาม รายการรวมถึงการกำหนดค่า การแปลงข้อมูล & การตรวจสอบความถูกต้อง รหัส ML (การฝึกอบรม & การตรวจสอบ) เครื่องมือการจัดการทรัพยากร (กระบวนการ & เครื่องจักร) โครงสร้างพื้นฐานการให้บริการ การตรวจสอบ (สามารถรวมเข้ากับ Data Drift) รายการนี้ไม่ครบถ้วนสมบูรณ์ แต่เป็นรายการทั่วไปและอาจแก้ไขได้ตามต้องการ
- ดังนั้น เพื่อให้เป็นไปตามระบบ ML ที่มีประสิทธิภาพดี เราจึงต้องใช้ชุดเครื่องมือเพื่อครอบคลุมส่วนประกอบที่กล่าวถึงข้างต้นทั้งหมด บางครั้งอาจมากกว่าหนึ่งชิ้นสำหรับชิ้นส่วนเดียว
ความสามารถในการออกแบบระบบ Full stack มีความสำคัญอย่างไร?
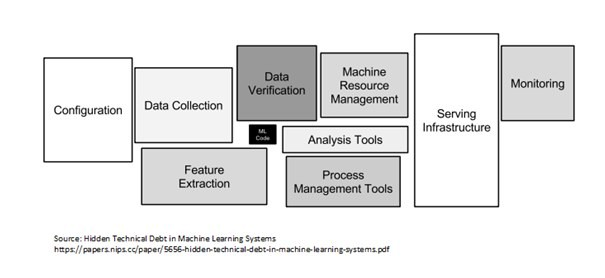
เครดิต Pic: หนี้ทางเทคนิคที่ซ่อนอยู่ในเอกสารระบบการเรียนรู้ของเครื่อง
- ดังที่ได้กล่าวไว้ข้างต้น ธุรกิจในปัจจุบันไม่อนุญาตให้มีการวิจัย/POC โดยไม่มีความยั่งยืนที่เป็นรูปธรรมของผลิตภัณฑ์
- ฉันจะไม่พูดเกินจริงถ้าฉันบอกว่าการฝึกโมเดลไม่ใช่ส่วนที่สำคัญที่สุด อันที่จริง ฉันจะจัดอันดับที่สามหรือสี่ บุคคลที่สามารถออกแบบและบำรุงรักษากองได้มีความสำคัญต่อบริษัทเพราะ
- หากบุคคลคนเดียวกันที่จะฝึกแบบจำลองยังคงรักษาไปป์ไลน์ข้อมูล (หรือมีส่วนร่วม) เขา/เธอสามารถออกแบบให้ตอบสนองความต้องการที่แท้จริงได้
- การทำความเข้าใจ Infra ของการทำให้ใช้งานได้จะช่วยสร้างประสิทธิภาพที่เป็นศูนย์กลางมากขึ้น
- การทำความเข้าใจ Serving infra จะช่วยในส่วนของความเร็วและเวลาแฝง (ซึ่งโดยทั่วไปจะเป็นการร้องไห้สูงสุดสำหรับระบบ ML ใดๆ)
- การทำความเข้าใจการตรวจสอบจะช่วยในเรื่อง Data Drift & ในประสิทธิภาพของแบบจำลองในระยะยาว
- ดังนั้น บุคคลที่รู้ทั้งหมดนี้สามารถทำให้ไปป์ไลน์ทั้งหมดมีประสิทธิภาพมากขึ้นและเพิ่มประสิทธิภาพได้ แต่เหนือสิ่งอื่นใด มันช่วยประหยัดค่าใช้จ่ายสำหรับบริษัท เนื่องจากตอนนี้คนๆ เดียวสามารถจัดการได้หลายบทบาท ซึ่งจะทำให้เพิ่มมูลค่าของแต่ละบุคคลให้กับบริษัทได้
ดังนั้นเพื่อสรุป จึงจำเป็นที่จะไม่เพียงแค่หมกมุ่นอยู่กับความถูกต้องของแบบจำลองเท่านั้น แต่ยังต้องหมกมุ่นอยู่กับตัววัดประสิทธิภาพหลักทั้งหมด เช่น ความเร็ว เวลาแฝง ความแม่นยำ ความต้องการอินฟาเรด คำขอให้บริการ ฯลฯ
อ่านเพิ่มเติม: แนวคิดโครงการการเรียนรู้ของเครื่อง
ภาพรวมวิธีการทำงานของระบบสแต็กแบบเต็ม
ภาพรวมวงจรชีวิตของระบบ ML ในอุดมคติ
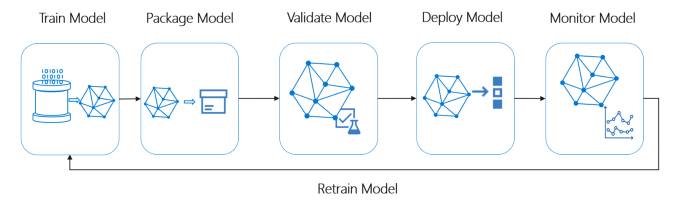
เครดิตภาพ: Microsoft MLOps
ML Pipeline ในอุดมคติต้องเป็นไปตามแนวคิดด้านล่าง:
- ธรรมาภิบาล:
- การกำหนดเวอร์ชันของรหัสโครงการ
- การกำหนดเวอร์ชันของข้อมูล
- การกำหนดเวอร์ชันของรุ่น
- เอกสาร
- ที่เก็บสิ่งประดิษฐ์สากลเพื่อจัดเก็บเนื้อหาที่มีเวอร์ชัน
- พิมพ์เขียวไปป์ไลน์ทั่วไป:
- นโยบายการค้นพบทั่วไป + การทดลอง
- การติดตามการทดสอบ (เช่น ตัวชี้วัด ผลลัพธ์ ประสิทธิภาพ)
- กลยุทธ์ทั่วไปในการเชื่อมต่อส่วนประกอบต่างๆ ของไปป์ไลน์
- ประกาศผล
- กลไกในการทำซ้ำ สร้างใหม่ พอร์ต
- รองรับ CI/CD
- อินฟาเรดที่เพียงพอต่อการพัฒนาและการผลิต
- ดัดแปลงง่ายสำหรับการผลิตและอุปกรณ์ปลายทาง
- อินฟาเรดที่ปรับขนาดได้เพื่อรองรับคำขอที่เพิ่มมากขึ้น
ภาพรวมไปป์ไลน์
- การกำหนดค่าการตั้งค่าครั้งเดียวกับ stack
- ชุดข้อมูลเวอร์ชันพร้อม DVC
- การทดลองติดตาม Strat ด้วย MLflow/Wandb
- บันทึกผลลัพธ์ ตัวชี้วัด ฯลฯ ด้วย MLflow/Wandb บนที่เก็บ Universal Artifact (ที่เก็บข้อมูล Azure blob เป็นแบ็กเอนด์)
- Log Model (หรือสินทรัพย์ที่เกี่ยวข้องใดๆ) เป็นสินทรัพย์ที่มีการกำหนดเวอร์ชันด้วย MLflow/Wandb บนที่เก็บ Universal Artifact
- บรรจุส่วนประกอบแต่ละส่วนด้วย Docker
- จัดเก็บส่วนประกอบแพ็คเกจด้วยที่เก็บ Docker ที่ต้องการ
- บรรจุภัณฑ์และการเผยแพร่ต้องทำโดยใช้ CI/CD
- การจัดกำหนดการการฝึกอบรมแบบจำลองอัตโนมัติตามการตรวจสอบอย่างต่อเนื่องสำหรับ Data Drift
รับ ใบรับรองวิทยาศาสตร์ข้อมูล จากมหาวิทยาลัยชั้นนำของโลก เรียนรู้หลักสูตร Executive PG Programs, Advanced Certificate Programs หรือ Masters Programs เพื่อติดตามอาชีพของคุณอย่างรวดเร็ว
บทสรุป
เพื่อให้ผู้เล่นในทีมมีความเกี่ยวข้อง มีไหวพริบ และเป็นคนสำคัญ จำเป็นต้องเพิ่มเต็นท์ความรู้ของเรา มันจะช่วยให้ก้าวหน้าในสภาพแวดล้อมการแข่งขันอย่างไม่ต้องสงสัย
หากคุณสนใจที่จะเรียนรู้เพิ่มเติมเกี่ยวกับแมชชีนเลิร์นนิง โปรดดูที่ IIIT-B & upGrad's PG Diploma in Machine Learning & AI ซึ่งออกแบบมาสำหรับมืออาชีพที่ทำงานและมีการฝึกอบรมที่เข้มงวดมากกว่า 450 ชั่วโมง กรณีศึกษาและการมอบหมายมากกว่า 30 รายการ IIIT- สถานะศิษย์เก่า B, 5+ โครงการหลักที่ใช้งานได้จริง & ความช่วยเหลือด้านงานกับบริษัทชั้นนำ