Vom Jr Data Scientist/Machine Learning zum Data Scientist/Machine Learning Engineer Expert
Veröffentlicht: 2020-12-07Vom Jr. Data Scientist/Machine Learning zum Full-Stack Data Scientist/Machine Learning Engineer
Die aktuellen Aussichten im Bereich Data Science haben sich im Vergleich zu vor drei oder sogar zwei Jahren erheblich verändert. Die Lernkurve sollte nie enden. Um erfolgreich zu sein, muss man also die richtigen Fähigkeiten entwickeln, um die aktuellen Erwartungen der Branche zu erfüllen.
„Bei der Anpassungsfähigkeit geht es um den gewaltigen Unterschied zwischen der Anpassung an die Bewältigung und der Anpassung an den Sieg.“ – Max McKeown.
Lassen Sie uns einen Blick auf die Schlüsselelemente werfen, die uns beim Übergang vom Jr. Data Scientist/Machine Learning zum Full Stack Data Scientist/Machine Learning helfen können.
Inhaltsverzeichnis
Die vergangene Erwartung
Es ist wichtig, die vergangene Verantwortung zu verstehen, um sich an die aktuellen Erwartungen der Branche anzupassen. Kurz gesagt, die tägliche Rolle eines Data Scientist in der Vergangenheit umfasste im Allgemeinen Folgendes:
- Der KI-Bereich war noch relativ neu (wenn auch nicht im akademischen Bereich) und viele Unternehmen und Startups analysierten seine Anwendung und seinen gültigen Anwendungsfall.
- Die Recherche stand im Vordergrund. Der Vorbehalt hier war, dass diese Forschung oft nicht direkt mit dem Kern der Organisation übereinstimmte. Also war zunächst nicht so viel Glaubwürdigkeit zu erwarten.
- Im Allgemeinen haben Unternehmen die Rollen eines Datenwissenschaftlers mit einem Datenanalysten oder Dateningenieur gemischt. Auch hier aufgrund der Unbestimmtheit der KI-Unternehmensanwendung.
- Einzelpersonen hatten auch eine Art ähnliches Dilemma. Ein Großteil ihrer Forschung oder Arbeit stand nicht direkt im Zusammenhang, praktisch nicht als Produkt zu dienen.
Der aktuelle Ausblick
Die Demokratisierung der KI hat bemerkenswerte Entwicklungen von Unternehmen und Startups mit sich gebracht. Versuchen wir es zu verstehen,
- Die Branche unterscheidet jetzt die Rolle eines Data Scientist, Machine Learning Engineer, Data Analyst, Data Engineer, sogar MLops Engineer.
- Unternehmen erlauben keine Forschung in freier Wildbahn mehr, da sie genau wissen, welchen Anwendungsfall sie erschließen. Eine klare Denkweise und ein ähnlich diskreter Ansatz einer Einzelperson sind ebenfalls erforderlich.
- Jede Forschung oder POC muss ein greifbares und bedienbares Produkt haben.
Lesen Sie auch: Karriere im maschinellen Lernen
Die gründliche Zerlegung aller Rollen
Wenn wir einen Bereich herausgreifen müssen, in dem sich die Unternehmen im KI-Bereich hervorgetan haben, ist dies zweifellos die klare Erwartung aller Arten von Rollen, die kurz zusammengefasst sind:
- Data Scientist: Ein Data Scientist ist eine Person, die (in der Regel mit Statistik-/Mathematikhintergrund) eine Vielzahl von Mitteln, einschließlich KI, verwendet, um wertvolle Informationen aus Daten zu extrahieren.
- Ein grundlegender Unterschied zwischen Datenanalysten und Datenwissenschaftlern besteht darin, dass sich erstere im Allgemeinen auf Domänenwissen und manuelle Methoden der alten Schule verlassen, um Daten in kleinem bis mittlerem Maßstab zu verstehen, während letzterer für das Sammeln, Analysieren und Interpretieren von Daten in größerem Maßstab verantwortlich ist Verwendung breiterer Mittel von Tools wie KI, SQL, manuelle Methoden der alten Schule usw.,
- Domänenkenntnisse sind kein Muss, aber hilfreich.
- Die Hauptaufgabe besteht darin, geschäftsrelevante Erkenntnisse aus Daten zu erhalten und zu extrahieren und nicht die Software oder das Produkt zu entwickeln.
- Ein Statistiker oder Mathematiker kann ein guter Data Scientist werden.
2. Machine Learning Engineer: Ein Nischen-Software-Ingenieur, der ein Produkt oder eine Dienstleistung auf der Grundlage von KI entwickelt.
- Ein ML-Ingenieur muss über das gesamte Fachwissen des traditionellen Software-Engineerings sowie über KI-Kenntnisse verfügen, da er/sie letztendlich Software mit KI als Herzstück erstellen wird.
- Die Hauptaufgabe besteht nicht darin, Daten zu extrahieren, sondern ein KI-Tool zu entwickeln, das die gleiche Aufgabe erfüllen kann.
- Ein Entwickler mit guten Kenntnissen in Machine Learning/Deep Learning sowie Software Engineering kann ein guter Machine Learning Engineer werden.
3. Machine Learning Operation Engineer: Ein Nischen-Software-Ingenieur, der die vom ML-System verwendete Pipeline wartet und automatisiert.
- Relativ neues, von DevOps inspiriertes Feld. Obwohl sie sich von traditionellen DevOps-Rollen unterscheiden.
- Im Gegensatz zum traditionellen Software-Engineering endet die Entwicklung für Produkte/Software/Dienste auf der Grundlage von KI nicht mit dem Abschluss der Erstellung von Software. Es muss regelmäßig mit neuen Daten aktualisiert werden, was 'Data-Drift' ist.
- Die Hauptaufgabe umfasst alle traditionellen DevOps-Arbeiten sowie die Wartung/Automatisierung von Pipelines und Data-Drift
- Ein Entwickler mit guten Kenntnissen in maschinellem Lernen/Deep Learning, Softwareentwicklung und Cloud-Technologien kann ein guter MlOps-Ingenieur werden.
Für einen neuen Suchenden oder jemanden, der in seiner Karriere vorankommen möchte, müssen all diese Rollen und Erwartungen gut verstanden werden. Da Unternehmen diese Rolle klar abgrenzen, wird erwartet, dass dies auch für Einzelpersonen der Fall sein wird. Eine vage Denkweise ist völlig nutzlos.
Der Stack eines Full-Stack-Machine-Learning-Systems
Kommen wir nun zum Wesentlichen. Um ein Full Stack Machine Learning Engineer zu werden, ist es notwendig, das Konzept hinter dem Stack zu verstehen.

Was ist Fullstack?
- Ähnlich wie beim traditionellen Software-Engineering erfordert die Entwicklung eines KI-basierten Systems auch eine Reihe von Tools. Diese vollständige Suite kann als Full Stack bezeichnet werden.
- Der vollständige Stack wird in der Regel aus drei Bausteinen aufgebaut: Cloud-Technologie, Governance-Technologie und KI-Technologie.
- Es gibt mehrere Komponenten für den Aufbau eines KI-Systems über die drei Bausteine hinweg. Die Liste umfasst Konfiguration, Transformation und Verifizierung der Datenerfassung, ML-Code (Schulung und Validierung), Verwaltungstools für Ressourcen (Prozess und Maschine), Bereitstellungsinfrastruktur, Überwachung (kann mit Data Drift kombiniert werden). Diese Liste ist nicht vollständig, aber sie ist sicherlich allgemein gehalten und kann nach Bedarf geändert werden.
- Um also an dem gut funktionierenden ML-System festzuhalten, müssen wir den Werkzeugstapel verwenden, um alle oben genannten Komponenten abzudecken, manchmal sogar mehr als eine für ein einzelnes Teil.
Welche Bedeutung hat die Fähigkeit, ein Full-Stack-System zu entwerfen?
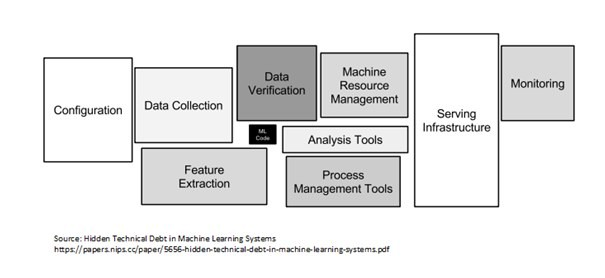
Pic Credit: Versteckte technische Schuld in Papier zu maschinellen Lernsystemen
- Wie ich oben erwähnt habe, erlauben die heutigen Unternehmen keine Forschung/POC ohne greifbare Nachhaltigkeit des Produkts.
- Ich übertreibe nicht, wenn ich sage, dass das Modelltraining nicht der wichtigste Teil ist, sondern ich werde es an dritter oder sogar vierter Stelle einstufen. Die Person, die den Stack entwerfen und warten kann, wird für das Unternehmen lebenswichtig, denn
- Wenn dieselbe Person, die ein Modell trainieren wird, auch eine Datenpipeline verwaltet (oder einen Beitrag leistet), kann sie diese so gestalten, dass sie genau den Anforderungen entspricht.
- Das Verständnis der Bereitstellungsinfrastruktur hilft beim Aufbau einer stärker leistungsorientierten Umgebung.
- Das Verständnis von Serving Infra hilft beim Geschwindigkeits- und Latenzteil (was im Allgemeinen der höchste Schrei für jedes ML-System ist).
- Das Verständnis der Überwachung hilft bei der Datendrift und bei der langfristigen Modellleistung.
- Eine Person, die all dies weiß, kann also die gesamte Pipeline effizienter machen und die Leistung steigern. Vor allem aber spart es Kosten für das Unternehmen, da jetzt eine einzelne Person mehrere Rollen übernehmen kann, was wiederum den Wert des Einzelnen für das Unternehmen erhöht.
Zusammenfassend ist es also wichtig, nicht nur von der Modellgenauigkeit besessen zu sein, sondern von allen wichtigen Leistungsmetriken – Geschwindigkeit, Latenz, Genauigkeit, Infrastrukturbedarf, Bereitstellung von Anfragen usw. – besessen zu sein.
Lesen Sie auch: Projektideen für maschinelles Lernen
Überblick über die Funktionsweise eines Full-Stack-Systems
Überblick über den Lebenszyklus des idealen ML-Systems
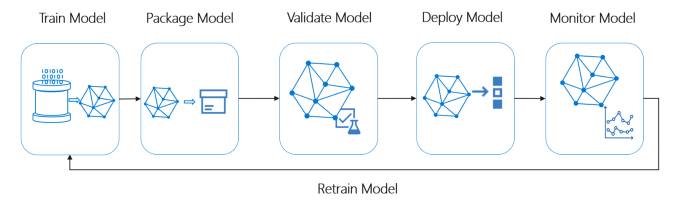
Bildnachweis : Microsoft MLOps
Eine ideale ML-Pipeline muss den folgenden Konzepten folgen:
- Führung:
- Versionierung des Projektcodes
- Versionierung von Daten
- Versionierung des Modells
- Dokumentation
- Universeller Artefaktspeicher zum Speichern von versionierten Assets
- Generische Pipeline-Blaupause:
- Gemeinsame Entdeckungs- und Experimentierrichtlinie
- Experiment-Tracking (wie einige Metriken, Ergebnisse, Leistung)
- Eine gemeinsame Strategie, um Komponenten der Pipeline miteinander zu verbinden
- Ergebnisse veröffentlichen
- Ein Mechanismus zum einfachen Reproduzieren, Neuerstellen, Portieren
- Unterstützung für CI/CD
- Ausreichende Infrastruktur zur Unterstützung der Entwicklung sowie der Produktion
- Einfache Anpassung für Produktion und Endpunkte
- Skalierbare Serving-Infrastruktur, um ständig steigende Anfragen zu erfüllen
Pipeline-Übersicht
- Eine einmalige Einstellungskonfiguration mit dem Stack
- Versionsdatensatz mit DVC.
- Strat-Tracking-Experiment mit MLflow/Wandb.
- Protokollieren Sie Ergebnisse, Metriken usw. mit MLflow/Wandb im Universal Artifact Store (Azure Blob Storage als Back-End).
- Protokollmodell (oder zugehörige Assets) als versionierte Assets mit MLflow/Wandb im Universal Artifact Store.
- Packen Sie einzelne Komponenten mit Docker.
- Speichern Sie Paketkomponenten mit dem gewünschten Docker-Repository
- Das Verpacken und Veröffentlichen muss unter Verwendung des CI/CD erfolgen.
- Planen eines automatisierten Modelltrainings basierend auf einer kontinuierlichen Überwachung für Data Drift.
Holen Sie sich eine Data-Science-Zertifizierung von den besten Universitäten der Welt. Lernen Sie Executive PG-Programme, Advanced Certificate-Programme oder Master-Programme, um Ihre Karriere zu beschleunigen.
Fazit
Um relevant, einfallsreich und ein wichtiger Teamplayer zu bleiben, ist es notwendig, unser Wissenszelt zu vergrößern. Es wird einem zweifellos helfen, in jedem Wettbewerbsumfeld voranzukommen.
Wenn Sie mehr über maschinelles Lernen erfahren möchten, sehen Sie sich das PG-Diplom in maschinellem Lernen und KI von IIIT-B & upGrad an, das für Berufstätige konzipiert ist und mehr als 450 Stunden strenge Schulungen, mehr als 30 Fallstudien und Aufgaben bietet, IIIT- B-Alumni-Status, mehr als 5 praktische, praktische Abschlussprojekte und Jobunterstützung bei Top-Unternehmen.