從初級數據科學家/機器學習到數據科學家/機器學習工程師專家
已發表: 2020-12-07從初級數據科學家/機器學習到全棧數據科學家/機器學習工程師
與三年甚至兩年前相比,當前數據科學領域的前景發生了顯著變化。 學習曲線永遠不會結束。 因此,要想茁壯成長,就必須培養正確的技能來滿足當前的行業期望。
“適應性是關於適應應對和適應勝利之間的巨大差異。” — 馬克斯·麥基翁。
讓我們看看可以幫助我們從初級數據科學家/機器學習轉向全棧數據科學家/機器學習的關鍵要素。
目錄
過去的期望
了解過去的責任以適應行業當前的期望至關重要。 因此,簡而言之,過去數據科學家的日常角色通常包括:
- 人工智能領域仍然相對較新(儘管不是在學術界),許多公司、初創公司正在分析其應用和有效用例。
- 研究是主要焦點。 這裡需要注意的是,這項研究多次與組織的核心並不直接一致。 因此,最初並沒有預期的那麼多可信度。
- 通常,公司過去常常將數據科學家與數據分析師或數據工程師的角色混合在一起。 再次,由於人工智能企業應用的模糊性。
- 個人也有類似的困境。 他們的許多研究或工作都不是直接的,實際上不可行作為產品。
當前展望
人工智能的民主化已經見證了公司和初創公司的顯著發展。 讓我們試著理解它,
- 業界現在區分了數據科學家、機器學習工程師、數據分析師、數據工程師,甚至是 MLops 工程師的角色。
- 企業不再允許在野外進行研究,因為他們知道他們究竟在利用什麼用例。還需要個人清晰的心態和類似的離散方法。
- 每項研究或 POC 都必須有一個有形且可服務的產品。
另請閱讀:機器學習職業
對所有角色的徹底剖析
如果我們必須選擇一個企業在人工智能領域表現出色的領域,那無疑是各種角色的明確預期,簡而言之:
- 數據科學家:數據科學家是指(通常來自統計/數學背景)使用包括人工智能在內的多種手段從數據中提取有價值信息的人。
- 數據分析師和數據科學家之間的一個根本區別是——前者通常依靠領域知識和傳統的手工方法來理解中小規模的數據,而後者負責收集、分析和解釋更大規模的數據使用更廣泛的工具手段,如 AI、SQL、老式手動方式等,
- 領域知識不是必須的,但擁有是有幫助的。
- 主要工作是維護和從數據中提取業務貢獻見解,而不是開發軟件或產品。
- 統計學家或數學家可以成為優秀的數據科學家。
2.機器學習工程師:基於人工智能開發產品或服務的小眾軟件工程師。
- ML 工程師需要具備傳統軟件工程的所有專業知識以及 AI 知識,因為他/她最終將構建以 AI 為核心的軟件。
- 主要工作不是提取數據,而是開發可以執行相同工作的人工智能工具。
- 具有良好機器學習/深度學習以及軟件工程知識的開發人員可以成為優秀的機器學習工程師。
3.機器學習操作工程師:維護和自動化機器學習系統使用的管道的利基軟件工程師。
- 受 DevOps 啟發的相對較新的領域。 雖然不同於傳統的 DevOps 角色。
- 與傳統的軟件工程不同,任何基於人工智能的產品/軟件/服務的開發都不會在軟件構建完成時停止。 它必須使用新數據定期更新,即“數據漂移”。
- 主要工作包括所有傳統的 DevOps 工作以及維護/自動化管道和數據漂移
- 具有機器學習/深度學習、軟件工程和雲技術知識的開發人員可以成為優秀的 MlOps 工程師。
對於一個新的求職者或希望在他或她的職業生涯中取得進步的人來說,所有這些角色和期望都必須得到很好的理解。 鑑於公司明確區分了這一角色,預計個人也將如此。 模糊的心態是完全沒用的。
全棧機器學習系統的堆棧
現在讓我們進入關鍵點。 要成為一名全棧機器學習工程師,了解棧背後的概念是必要的。
什麼是全棧?
- 與傳統的軟件工程類似,開發基於 AI 的系統也需要一套工具。 這個完整的套件可以稱為全棧。
- 完整的堆棧通常使用三個構建塊構建,即云技術、治理技術和人工智能技術。
- 有多個組件可用於跨三個構建塊構建 AI 系統。 該列表包括配置、數據收集轉換和驗證、ML 代碼(培訓和驗證)、資源(流程和機器)管理工具、服務基礎設施、監控(可以與 Data Drift 結合使用)。 這個列表並不詳盡,但它肯定是通用的,可以根據需要進行修改。
- 因此,為了堅持性能良好的 ML 系統,我們必須使用工具堆棧來覆蓋所有上述組件,有時甚至不止一個組件。
設計全棧系統的能力有多重要?
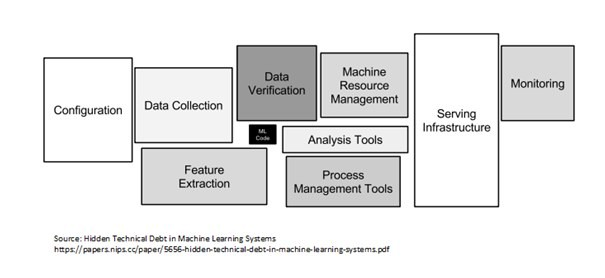

圖片來源:機器學習系統論文中隱藏的技術債務
- 正如我上面提到的,如果沒有產品的切實可持續性,今天的企業不允許進行研究/POC。
- 如果我說模型訓練不是最重要的部分,我不會誇大其詞,事實上,我會將它排在第三甚至第四。 能夠設計和維護堆棧的人對公司至關重要,因為,
- 如果要訓練模型的同一個人還維護數據管道(或貢獻),那麼他/她可以設計它以滿足確切的需求。
- 了解部署基礎架構將有助於構建更加以性能為中心的架構。
- 了解 Serving infra 將有助於速度和延遲部分(這通常是任何 ML 系統的最高要求)。
- 了解監控將有助於數據漂移和長期模型性能。
- 因此,了解這一切的個人可以使整個管道更高效並提高性能。 但最重要的是,它為公司節省了成本,因為現在一個人可以處理多個角色,從而增加了個人對公司的價值。
總而言之,重要的是不要只關注模型準確性,還要關注所有關鍵性能指標——速度、延遲、準確性、基礎設施需求、服務請求等。
另請閱讀:機器學習項目理念
全棧系統工作原理概述
Ideal ML System 的生命週期概覽
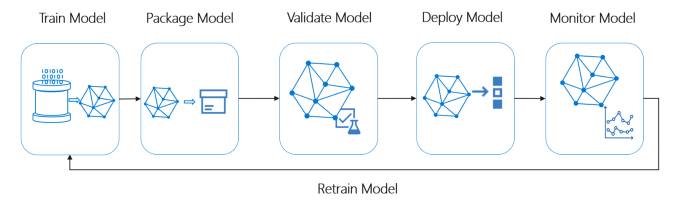
圖片來源:微軟 MLOps
理想的 ML 流水線必須遵循以下概念:
- 治理:
- 項目代碼的版本控制
- 數據版本控制
- 模型的版本控制
- 文檔
- 用於存儲版本化資產的通用工件存儲
- 通用管道藍圖:
- 共同發現+實驗策略
- 實驗跟踪(如一些指標、結果、性能)
- 互連管道組件的常用策略
- 發布結果
- 一種輕鬆複製、重新創建、移植的機制
- 支持 CI/CD
- 足夠的基礎設施來支持開發和生產
- 輕鬆適應生產和端點
- 可擴展的服務基礎設施,以滿足不斷增長的需求
管道概述
- 使用堆棧的一次性設置配置
- 帶有 DVC 的版本數據集。
- 使用 MLflow/Wandb 進行 Strat 跟踪實驗。
- 在通用工件存儲(Azure blob 存儲作為後端)上使用 MLflow/Wandb 記錄結果、指標等。
- 使用 MLflow/Wandb 將模型(或任何相關資產)作為版本化資產記錄在 Universal Artifact 商店中。
- 使用 Docker 打包單個組件。
- 使用所需的 Docker 存儲庫存儲包組件
- 打包和發布必須使用 CI/CD 完成。
- 基於數據漂移的持續監控調度自動化模型訓練。
獲得世界頂尖大學的數據科學認證。 學習行政 PG 課程、高級證書課程或碩士課程,以加快您的職業生涯。
結論
為了保持相關、足智多謀、關鍵的團隊成員,有必要增加我們的知識帳篷。 毫無疑問,它將幫助一個人在任何競爭環境中取得進步。
如果您有興趣了解有關機器學習的更多信息,請查看 IIIT-B 和 upGrad 的機器學習和人工智能 PG 文憑,該文憑專為工作專業人士設計,提供 450 多個小時的嚴格培訓、30 多個案例研究和作業、IIIT- B 校友身份、5 個以上實用的實踐頂點項目和頂級公司的工作協助。