De Jr Data Scientist/Machine learning à Data Scientist/Machine Learning Engineer Expert
Publié: 2020-12-07De Jr Data Scientist/Machine learning à Full-stack Data Scientist/Machine learning engineer
Les perspectives actuelles dans le domaine de la science des données ont considérablement changé par rapport à il y a trois ou même deux ans. La courbe d'apprentissage ne devrait jamais s'arrêter. Donc, pour prospérer, il faut développer les bonnes compétences pour répondre aux attentes actuelles de l'industrie.
"L'adaptabilité concerne la puissante différence entre s'adapter pour faire face et s'adapter pour gagner." —Max McKeown.
Examinons les éléments clés qui peuvent nous aider à passer de Jr Data Scientist / Machine learning à Full stack Data Scientist / Machine learning.
Table des matières
L'attente passée
Il est essentiel de comprendre la responsabilité passée de s'adapter aux attentes actuelles de l'industrie. Donc, en un mot, le rôle quotidien d'un Data Scientist dans le passé impliquait généralement :
- L'espace de l'IA était encore relativement nouveau (mais pas dans le milieu universitaire) et de nombreuses entreprises, startups analysaient son application et son cas d'utilisation valide.
- La recherche était l'objectif principal. La mise en garde ici était que cette recherche n'était souvent pas directement en ligne avec le cœur de l'organisation. Donc, au départ, il n'y avait pas tant de crédibilité attendue.
- Généralement, les entreprises mélangeaient les rôles de Data Scientist avec ceux d'analyste de données ou d'ingénieur de données. Encore une fois, en raison de l'imprécision de l'application d'entreprise AI.
- Les individus ont également eu une sorte de dilemme similaire. Une grande partie de leurs recherches ou de leur travail n'était pas directement en ligne, pratiquement pas viable pour être servie en tant que produit.
Les perspectives actuelles
La démocratisation de l'IA a connu des développements remarquables de la part des entreprises et des startups. Essayons de le comprendre,
- L'industrie distingue désormais le rôle d'un Data Scientist, d'un ingénieur en apprentissage automatique, d'un analyste de données, d'un ingénieur de données, voire d'un ingénieur MLops.
- Les entreprises n'autorisent plus la recherche dans la nature, car elles savent exactement dans quel cas d'utilisation elles s'appuient. Un état d'esprit clair et une approche discrète similaire de la part d'un individu sont également nécessaires.
- Chaque recherche ou POC doit avoir un produit tangible et utilisable.
Lisez aussi: Carrière en apprentissage automatique
La dissection minutieuse de tous les rôles
Si nous devons choisir un domaine dans lequel les entreprises ont excellé dans l'espace de l'IA, c'est sans aucun doute l'attente claire de toutes les variétés de rôles, qui sont en un mot :
- Scientifique des données : un scientifique des données est une personne qui (généralement issue des statistiques/mathématiques) utilise une variété de moyens, y compris l'IA, pour extraire des informations précieuses des données.
- Une différence fondamentale entre l'analyste de données et le scientifique de données est que le premier s'appuie généralement sur la connaissance du domaine et les méthodes manuelles de la vieille école pour donner un sens aux données à petite et moyenne échelle, tandis que le second est responsable de la collecte, de l'analyse et de l'interprétation des données à plus grande échelle. en utilisant des moyens plus larges d'outils comme l'IA, SQL, les méthodes manuelles de la vieille école, etc.,
- La connaissance du domaine n'est pas indispensable, mais l'avoir est utile.
- Le travail principal consiste à maintenir et à extraire des informations commerciales à partir des données et non à développer le logiciel ou le produit.
- Un Statisticien ou un Mathématicien peut devenir un bon Data Scientist.
2. Ingénieur en apprentissage automatique : un ingénieur logiciel de niche qui développe un produit ou un service basé sur l'IA.
- Un ingénieur ML doit posséder toute l'expertise de l'ingénierie logicielle traditionnelle ainsi que des connaissances en IA, car il finira par créer des logiciels avec l'IA en son cœur.
- Le travail principal n'est pas d'extraire des données mais de développer un outil d'IA qui peut effectuer le même travail.
- Un développeur ayant de bonnes connaissances en machine learning/deep learning ainsi qu'en génie logiciel peut devenir un bon ingénieur en machine learning.
3. Machine Learning Operation Engineer : Un ingénieur logiciel de niche qui maintient et automatise le pipeline utilisé par le système ML.
- Domaine relativement nouveau inspiré par DevOps. Bien que différent des rôles DevOps traditionnels.
- Contrairement à l'ingénierie logicielle traditionnelle, le développement de tout produit/logiciel/service basé sur l'IA ne s'arrête pas à l'achèvement de la construction du logiciel. Il doit être mis à jour régulièrement avec de nouvelles données, qui sont 'Data-Drift'.
- Le travail principal comprend tous les travaux DevOps traditionnels ainsi que la maintenance/l'automatisation du pipeline et de la dérive des données
- Un développeur ayant une bonne connaissance de l'apprentissage machine/deep learning, du génie logiciel et des technologies cloud peut devenir un bon ingénieur MlOps.
Pour un nouveau chercheur ou quelqu'un qui vise à progresser dans sa carrière, tous ces rôles et attentes doivent être bien compris. Étant donné que les entreprises distinguent clairement ce rôle, on s'attend à ce que ce soit également le cas pour les particuliers. Un état d'esprit vague est totalement inutile.

La pile d'un système d'apprentissage automatique Full stack
Passons maintenant à l'essentiel. Pour devenir un ingénieur en apprentissage automatique Full stack, il est nécessaire de comprendre le concept derrière la pile.
Qu'est-ce que la pile complète ?
- Semblable à l'ingénierie logicielle traditionnelle, le développement d'un système basé sur l'IA nécessite également une suite d'outils. Cette suite complète peut être appelée Full Stack.
- La pile complète est généralement construite à l'aide de trois éléments constitutifs, la technologie Cloud, la technologie de gouvernance et la technologie AI.
- Il existe plusieurs composants pour construire un système d'IA à travers les trois éléments constitutifs. La liste comprend la configuration, la transformation et la vérification de la collecte de données, le code ML (formation et validation), les outils de gestion des ressources (processus et machine), l'infrastructure de service, la surveillance (peut être associée à Data Drift). Cette liste n'est pas exhaustive, mais elle est certainement générique et peut être modifiée au besoin.
- Ainsi, pour adhérer au système ML performant, nous devons utiliser la pile d'outils pour couvrir tous les composants mentionnés ci-dessus, parfois même plus d'un pour une seule pièce.
Quelle est l'importance de la capacité à concevoir un système Full stack ?
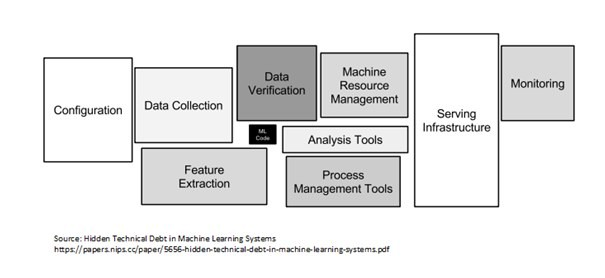
Crédit photo : dette technique cachée dans l'article sur les systèmes d'apprentissage automatique
- Comme je l'ai mentionné ci-dessus, les entreprises d'aujourd'hui ne permettent pas la recherche/POC sans durabilité tangible du produit.
- Je n'exagère pas si je dis que la formation des modèles n'est pas la partie la plus importante, en fait, je la classerai troisième voire quatrième. La personne qui peut concevoir et entretenir la pile devient vitale pour l'entreprise, car,
- Si la même personne qui va former un modèle maintient également un pipeline de données (ou y contribue), elle peut le concevoir pour répondre aux besoins exacts.
- Comprendre l'infra de déploiement aidera à construire une approche plus centrée sur les performances.
- Comprendre Serving infra aidera dans la partie vitesse et latence (qui est généralement le cri le plus élevé pour tout système ML).
- Comprendre la surveillance aidera à la dérive des données et aux performances du modèle à long terme.
- Ainsi, une personne connaissant tout cela peut rendre l'ensemble du pipeline plus efficace et augmenter les performances. Mais surtout, cela réduit les coûts pour l'entreprise car une seule personne peut désormais gérer plusieurs rôles, augmentant ainsi la valeur de l'individu pour l'entreprise.
Donc, pour résumer, il est essentiel de ne pas être obsédé par la précision du modèle, mais obsédé par toutes les mesures de performance clés - vitesse, latence, précision, besoins d'infra, demandes de traitement, etc.
Lisez aussi : Idées de projets d'apprentissage automatique
Présentation du fonctionnement d'un système full stack
Présentation du cycle de vie d'Ideal ML System
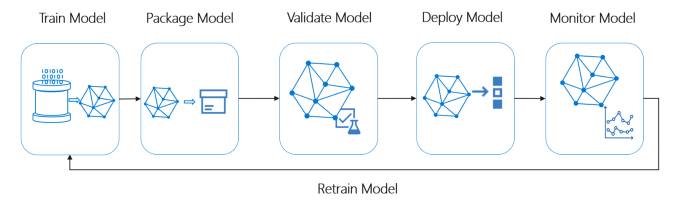
Crédit photo : Microsoft MLOps
Un pipeline ML idéal doit suivre les concepts ci-dessous :
- Gouvernance :
- Versionnement du code du projet
- Versionnement des données
- Versionnage du modèle
- Documentation
- Magasin d'artefacts universel pour stocker les actifs versionnés
- Plan de pipeline générique :
- Politique commune découverte + expérimentation
- Suivi des expériences (comme certaines mesures, résultats, performances)
- Une stratégie commune pour interconnecter les composants du pipeline
- Publier les résultats
- Un mécanisme pour facilement reproduire, recréer, porter
- Prise en charge de CI/CD
- Infra suffisante pour soutenir le développement ainsi que la production
- Adaptation facile pour la production et les terminaux
- Infra de service évolutif pour répondre aux demandes toujours croissantes
Présentation du pipeline
- Une configuration de réglage unique avec la pile
- Jeu de données de version avec DVC.
- Expérience de suivi de strat avec MLflow/Wandb.
- Enregistrez les résultats, les métriques, etc., avec MLflow/Wandb sur Universal Artifact Store (stockage d'objets blob Azure en tant que backend).
- Modèle de journal (ou tout actif connexe) en tant qu'actif versionné avec MLflow/Wandb sur Universal Artifact Store.
- Emballez des composants individuels avec Docker.
- Stocker les composants du package avec le référentiel Docker souhaité
- L'emballage et la publication doivent être effectués à l'aide du CI/CD.
- Planification d'une formation de modèle automatisée basée sur une surveillance continue pour Data Drift.
Obtenez une certification en science des données des meilleures universités du monde. Apprenez les programmes Executive PG, les programmes de certificat avancés ou les programmes de maîtrise pour accélérer votre carrière.
Conclusion
Pour rester pertinent, débrouillard, joueur d'équipe clé, il est nécessaire d'augmenter notre tente de connaissances. Il vous aidera sans aucun doute à progresser dans n'importe quel environnement concurrentiel.
Si vous souhaitez en savoir plus sur l'apprentissage automatique, consultez le diplôme PG en apprentissage automatique et IA de IIIT-B & upGrad, conçu pour les professionnels en activité et offrant plus de 450 heures de formation rigoureuse, plus de 30 études de cas et missions, IIIT- Statut B Alumni, plus de 5 projets de synthèse pratiques et aide à l'emploi avec les meilleures entreprises.