ジュニアデータサイエンティスト/機械学習からデータサイエンティスト/機械学習エンジニアエキスパートまで
公開: 2020-12-07Jrデータサイエンティスト/機械学習からフルスタックデータサイエンティスト/機械学習エンジニアまで
データサイエンスの分野における現在の見通しは、3年または2年前と比較して大幅に変化しています。 学習曲線は決して終わらないはずです。 したがって、繁栄するには、現在の業界の期待に応えるための適切なスキルセットを開発する必要があります。
「適応性とは、対処するための適応と勝利への適応の強力な違いです。」 —マックス・マッケオン。
Jrデータサイエンティスト/機械学習からフルスタックデータサイエンティスト/機械学習への移行を支援する重要な要素を見てみましょう。
目次
過去の期待
業界の現在の期待に適応するための過去の責任を理解することが重要です。 つまり、一言で言えば、過去のデータサイエンティストの日常的な役割には、一般的に次のようなものが含まれていました。
- AIスペースはまだ比較的新しく(学者ではありませんが)、多くの企業、スタートアップがそのアプリケーションと有効なユースケースを分析していました。
- 研究が主な焦点でした。 ここでの注意点は、この調査が組織のコアと直接一致していないことが何度もあったことです。 そのため、当初はそれほど信頼性は期待されていませんでした。
- 一般的に、企業はデータサイエンティストの役割とデータアナリストまたはデータエンジニアの役割を融合させていました。 繰り返しになりますが、AIエンタープライズアプリケーションのあいまいさのためです。
- 個人にも同様のジレンマがありました。 彼らの研究や研究の多くは直接一致しておらず、製品として提供することは事実上実行可能ではありませんでした。
現在の見通し
AIの民主化は、企業や新興企業から目覚ましい発展を遂げています。 それを理解してみましょう、
- 現在、業界では、データサイエンティスト、機械学習エンジニア、データアナリスト、データエンジニア、さらにはMLopsエンジニアの役割が区別されています。
- 企業は、どのユースケースを利用しているのかを正確に把握しているため、もはや実際の調査を許可していません。明確な考え方と、個人からの同様の個別のアプローチも必要です。
- すべてのリサーチまたはPOCには、具体的でサービス可能な製品が必要です。
また読む:機械学習のキャリア
すべての役割の徹底的な分析
企業がAIの分野で優れている分野を1つ選ぶ必要がある場合、それは間違いなく明確です-一言で言えば、すべての種類の役割からの期待です。
- データサイエンティスト:データサイエンティストは、(一般的に統計/数学のバックグラウンドから)AIを含むさまざまな手段を使用してデータから貴重な情報を抽出する人です。
- データアナリストとデータサイエンティストの根本的な違いは、前者は一般にドメイン知識と手動の古い学校の方法に依存して小規模から中規模のデータを理解するのに対し、後者は大規模なデータの収集、分析、解釈を担当することです。 AI、SQL、古い学校の手動の方法などのツールのより広い手段を使用して、
- ドメイン知識は必須ではありませんが、持っていることは役に立ちます。
- 主な仕事は、データからビジネスに貢献する洞察を維持および抽出することであり、ソフトウェアや製品を開発することではありません。
- 統計学者または数学者は、優れたデータサイエンティストになることができます。
2.機械学習エンジニア: AIに基づいて製品またはサービスを開発するニッチなソフトウェアエンジニア。
- MLエンジニアは、最終的にAIを中心にソフトウェアを構築するため、AIの知識とともに従来のソフトウェアエンジニアリングのすべての専門知識を持っている必要があります。
- 主な仕事はデータを抽出することではなく、同じ仕事を実行できるAIツールを開発することです。
- 機械学習/深層学習とソフトウェアエンジニアリングの知識が豊富な開発者は、優れた機械学習エンジニアになることができます。
3.機械学習オペレーションエンジニア: MLシステムで使用されるパイプラインを維持および自動化するニッチなソフトウェアエンジニア。
- DevOpsに触発された比較的新しい分野。 従来のDevOpsの役割とは異なりますが。
- 従来のソフトウェアエンジニアリングとは異なり、AIに基づく製品/ソフトウェア/サービスの開発は、ソフトウェアの構築が完了した時点で止まりません。 「データドリフト」という新しいデータで定期的に更新する必要があります。
- 主な仕事には、パイプラインとデータドリフトの維持/自動化だけでなく、すべての従来のDevOps作業が含まれます
- 機械学習/ディープラーニング、ソフトウェアエンジニアリング、クラウドテクノロジーに精通している開発者は、優れたMlOpsエンジニアになることができます。
新しい求職者や自分のキャリアの進歩を目指している人にとって、これらすべての役割と期待を十分に理解する必要があります。 企業がこの役割を明確に区別していることを考えると、これは個人にも当てはまると予想されます。 漠然とした考え方はまったく役に立たない。
フルスタック機械学習システムのスタック
ここで、本質的なポイントに移りましょう。 フルスタックの機械学習エンジニアになるには、スタックの背後にある概念を理解する必要があります。
フルスタックとは何ですか?
- 従来のソフトウェアエンジニアリングと同様に、AIベースのシステムの開発にも一連のツールが必要です。 この完全なスイートは、フルスタックと呼ばれます。
- フルスタックは通常、クラウドテクノロジー、ガバナンステクノロジー、AIテクノロジーの3つのビルディングブロックを使用して構築されます。
- 3つのビルディングブロックにわたってAIシステムを構築するための複数のコンポーネントがあります。 このリストには、構成、データ収集の変換と検証、MLコード(トレーニングと検証)、リソース(プロセスとマシン)の管理ツール、サービスインフラストラクチャ、監視(データドリフトと組み合わせることができます)が含まれます。 このリストは網羅的なものではありませんが、確かに一般的なものであり、必要に応じて変更できます。
- したがって、パフォーマンスの高いMLシステムに準拠するには、ツールのスタックを使用して、上記のすべてのコンポーネントをカバーする必要があります。1つのパーツに複数のコンポーネントが含まれる場合もあります。
フルスタックシステムを設計する機能の重要性は何ですか?
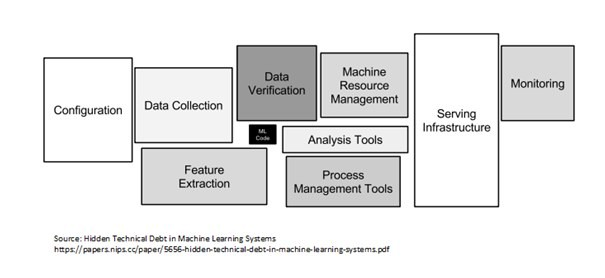

Pic Credit:機械学習システムの論文に隠された技術的負債
- 上で述べたように、今日のビジネスは、製品の具体的な持続可能性なしに研究/POCを許可していません。
- モデルトレーニングが最も重要な部分ではないと言っても過言ではありません。実際、私はそれを3番目または4番目にランク付けします。 スタックを設計および保守できる人は、会社にとって不可欠です。なぜなら、
- モデルをトレーニングしようとしている同じ人がデータパイプラインも維持している(または貢献している)場合、その人は正確なニーズに応えるようにモデルを設計できます。
- インフラストラクチャのインフラストラクチャを理解すると、パフォーマンス中心の構築に役立ちます。
- インフラストラクチャの提供を理解することは、速度と遅延の部分に役立ちます(これは一般的にMLシステムの最大の叫びです)。
- モニタリングを理解することは、データドリフトと長期モデルのパフォーマンスに役立ちます。
- したがって、これらすべてを知っている個人は、パイプライン全体をより効率的にし、パフォーマンスを向上させることができます。 しかし何よりも、1人で複数の役割を処理できるようになったため、会社のコストを節約でき、その結果、会社にとっての個人の価値が高まります。
要約すると、モデルの精度だけでなく、速度、遅延、精度、インフラストラクチャのニーズ、要求への対応など、すべての主要なパフォーマンス指標にこだわることが不可欠です。
また読む:機械学習プロジェクトのアイデア
フルスタックシステムの仕組みの概要
理想的なMLシステムのライフサイクルの概要
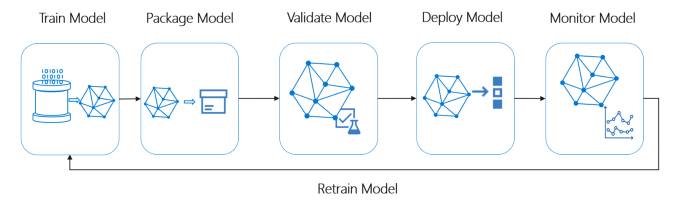
写真提供者: Microsoft MLOps
理想的なMLパイプラインは、以下の概念に従う必要があります。
- ガバナンス:
- プロジェクトコードのバージョン管理
- データのバージョン管理
- モデルのバージョン管理
- ドキュメンテーション
- バージョン管理されたアセットを保存するユニバーサルアーティファクトストア
- 一般的なパイプラインの青写真:
- 一般的な発見と実験のポリシー
- 実験の追跡(一部の指標、結果、パフォーマンスなど)
- パイプラインのコンポーネントを相互接続するための一般的な戦略
- 結果を公開する
- 簡単に複製、再作成、移植するメカニズム
- CI/CDのサポート
- 開発と生産をサポートするのに十分なインフラ
- 本番環境とエンドポイントに簡単に適応
- 増え続ける要求に対応するためのスケーラブルなサービングインフラ
パイプラインの概要
- スタックを使用した1回限りの設定構成
- DVCを使用したバージョンデータセット。
- MLflow/Wandbを使用したストラトトラッキング実験。
- ユニバーサルアーティファクトストア(バックエンドとしてのAzure BLOBストレージ)のMLflow / Wandbを使用して、結果、メトリックなどをログに記録します。
- ユニバーサルアーティファクトストアのMLflow/Wandbを使用して、バージョン化されたアセットとしてモデル(または関連するアセット)をログに記録します。
- 個々のコンポーネントをDockerでパッケージ化します。
- パッケージコンポーネントを目的のDockerリポジトリに保存します
- パッケージ化と公開は、CI/CDを使用して行う必要があります。
- データドリフトの継続的な監視に基づく自動モデルトレーニングのスケジューリング。
世界のトップ大学からデータサイエンス認定を取得します。 エグゼクティブPGプログラム、高度な証明書プログラム、または修士プログラムを学び、キャリアを早急に進めましょう。
結論
関連性があり、機知に富んだ、主要なチームプレーヤーであり続けるためには、知識のテントを増やす必要があります。 それは間違いなく競争の激しい環境で進歩するのに役立ちます。
機械学習について詳しく知りたい場合は、IIIT-BとupGradの機械学習とAIのPGディプロマをご覧ください。これは、働く専門家向けに設計されており、450時間以上の厳格なトレーニング、30以上のケーススタディと課題、IIIT-を提供します。 B卒業生のステータス、5つ以上の実践的なキャップストーンプロジェクト、トップ企業との仕事の支援。