De científico de datos junior/aprendizaje automático a científico de datos/experto en ingeniería de aprendizaje automático
Publicado: 2020-12-07De científico de datos junior/aprendizaje automático a científico de datos completo/ingeniero de aprendizaje automático
El panorama actual en el campo de la ciencia de datos ha cambiado significativamente en comparación con hace tres o incluso dos años. La curva de aprendizaje nunca debe terminar. Entonces, para prosperar, uno debe desarrollar el conjunto de habilidades adecuado para cumplir con las expectativas actuales de la industria.
“La adaptabilidad se trata de la poderosa diferencia entre adaptarse para hacer frente y adaptarse para ganar”. —Max McKeown.
Veamos los elementos clave que pueden ayudarnos a pasar de un científico de datos junior/aprendizaje automático a un científico de datos/aprendizaje automático de pila completa.
Tabla de contenido
La expectativa pasada
Es vital entender la responsabilidad pasada para adaptarse a las expectativas actuales de la industria. Entonces, en pocas palabras, el rol diario de un científico de datos en el pasado generalmente involucraba:
- El espacio de la IA todavía era relativamente nuevo (aunque no en el ámbito académico) y muchas empresas, las nuevas empresas estaban analizando su aplicación y su caso de uso válido.
- La investigación fue el foco principal. La advertencia aquí fue que esta investigación muchas veces no estaba directamente alineada con el núcleo de la organización. Así que inicialmente no se esperaba tanta credibilidad.
- En general, las empresas solían combinar los roles de un científico de datos con un analista de datos o un ingeniero de datos. Nuevamente, debido a la vaguedad de la aplicación empresarial de IA.
- Los individuos también tenían una especie de dilema similar. Mucha de su investigación o trabajo no estaba directamente en línea, prácticamente no era viable servir como producto.
La perspectiva actual
La democratización de la IA ha visto desarrollos notables de empresas y nuevas empresas. Tratemos de entenderlo,
- La industria ahora distingue el papel de un científico de datos, un ingeniero de aprendizaje automático, un analista de datos, un ingeniero de datos e incluso un ingeniero de MLops.
- Las empresas ya no permiten la investigación en la naturaleza, ya que saben qué caso de uso exactamente están aprovechando. También se requiere una mentalidad clara y un enfoque discreto similar de un individuo.
- Cada Investigación o POC debe tener un producto tangible y útil.
Lea también: Carrera en aprendizaje automático
La disección minuciosa de todos los Roles
Si tenemos que elegir un área en la que las empresas se han destacado en el espacio de la IA, es sin duda la clara expectativa de todas las variedades de roles, que se resumen en pocas palabras:
- Científico de datos: un científico de datos es una persona que (generalmente con experiencia en estadísticas/matemáticas) utiliza una variedad de medios, incluida la IA, para extraer información valiosa de los datos.
- Una diferencia fundamental entre el analista de datos y el científico de datos es que el primero generalmente se basa en el conocimiento del dominio y los métodos manuales de la vieja escuela para dar sentido a los datos a pequeña y mediana escala, mientras que el segundo es responsable de recopilar, analizar e interpretar datos a mayor escala. utilizando medios más amplios de herramientas como AI, SQL, formas manuales de la vieja escuela, etc.,
- El conocimiento del dominio no es obligatorio, pero tenerlo es útil.
- El trabajo principal es mantener y extraer información comercial que contribuya a partir de los datos y no desarrollar el software o el producto.
- Un estadístico o matemático puede convertirse en un buen científico de datos.
2. Ingeniero de aprendizaje automático: un ingeniero de software de nicho que desarrolla un producto o servicio basado en IA.
- Un ingeniero de ML debe tener toda la experiencia de la ingeniería de software tradicional junto con el conocimiento de IA porque eventualmente creará software con IA en su centro.
- El trabajo principal no es extraer datos sino desarrollar una herramienta de IA que pueda realizar el mismo trabajo.
- Un desarrollador con buenos conocimientos de aprendizaje automático/aprendizaje profundo, así como de ingeniería de software, puede convertirse en un buen ingeniero de aprendizaje automático.
3. Ingeniero de operaciones de aprendizaje automático: un ingeniero de software de nicho que mantiene y automatiza la canalización que utiliza el sistema ML.
- Campo relativamente nuevo inspirado en DevOps. Aunque es diferente de los roles tradicionales de DevOps.
- A diferencia de la ingeniería de software tradicional, el desarrollo de cualquier producto/software/servicio basado en IA no se detiene al completar la construcción del software. Debe actualizarse regularmente con nuevos datos, que es 'Data-Drift'.
- El trabajo principal incluye todo el trabajo tradicional de DevOps, así como el mantenimiento/automatización de la canalización y Data-Drift
- Un desarrollador con buenos conocimientos de aprendizaje automático/aprendizaje profundo, ingeniería de software y tecnologías en la nube puede convertirse en un buen ingeniero de MlOps.
Para un nuevo buscador o alguien que aspira a avanzar en su carrera, todos estos roles y expectativas deben entenderse bien. Dado que las empresas están distinguiendo claramente este rol, se espera que este también sea el caso de las personas. La mentalidad vaga es totalmente inútil.
La pila de un sistema de aprendizaje automático de pila completa
Pasemos ahora al punto esencial. Para convertirse en un ingeniero de aprendizaje automático de pila completa, es necesario comprender el concepto detrás de la pila.

¿Qué es la pila completa?
- Al igual que la ingeniería de software tradicional, el desarrollo de un sistema basado en IA también necesita un conjunto de herramientas. Esta suite completa se puede denominar Full Stack.
- La pila completa generalmente se construye utilizando tres bloques de construcción, tecnología en la nube, tecnología de gobernanza y tecnología de IA.
- Hay múltiples componentes para construir un sistema de IA en los tres componentes básicos. La lista incluye configuración, transformación y verificación de recopilación de datos, código ML (capacitación y validación), herramientas de administración de recursos (procesos y máquinas), infraestructura de servicio, monitoreo (se puede combinar con Data Drift). Esta lista no es exhaustiva, pero ciertamente es genérica y puede modificarse según sea necesario.
- Entonces, para adherirnos al sistema ML de buen rendimiento, tenemos que usar la pila de herramientas para cubrir todos los componentes mencionados anteriormente, a veces incluso más de uno para una sola parte.
¿Cuál es la importancia de la capacidad de diseñar un sistema Full Stack?
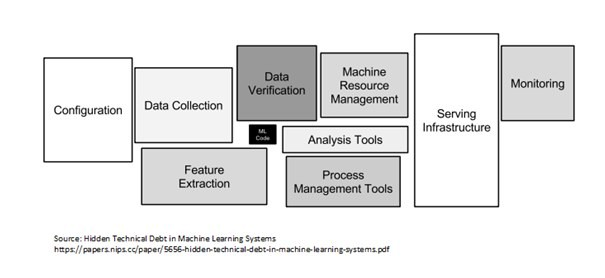
Crédito de la imagen: Deuda técnica oculta en el artículo sobre sistemas de aprendizaje automático
- Como mencioné anteriormente, las empresas de hoy no permiten la investigación/POC sin una sostenibilidad tangible del producto.
- No estaré exagerando si digo que el entrenamiento del modelo no es la parte más importante, de hecho, lo ubicaré tercero o incluso cuarto. La persona que puede diseñar y mantener la pila se vuelve vital para la Compañía, porque,
- Si la misma persona que va a entrenar un modelo también mantiene un flujo de datos (o contribuye), entonces puede diseñarlo para satisfacer las necesidades exactas.
- Comprender la infraestructura de implementación ayudará a construir un entorno más centrado en el rendimiento.
- Comprender la infraestructura de servicio ayudará en la parte de velocidad y latencia (que generalmente es el grito más alto para cualquier sistema ML).
- Comprender el monitoreo ayudará con la deriva de datos y el rendimiento del modelo a largo plazo.
- Por lo tanto, una persona que sepa todo esto puede hacer que toda la canalización sea más eficiente y aumentar el rendimiento. Pero, sobre todo, ahorra costos para la empresa, ya que ahora una sola persona puede manejar múltiples roles y, a su vez, aumenta el valor del individuo para la empresa.
Entonces, para resumir, es esencial no solo obsesionarse con la precisión del modelo, sino obsesionarse con todas las métricas clave de rendimiento: velocidad, latencia, precisión, necesidades de infraestructura, solicitudes de servicio, etc.
Lea también: Ideas de proyectos de aprendizaje automático
Descripción general de cómo funciona un sistema de pila completa
Descripción general del ciclo de vida de Ideal ML System
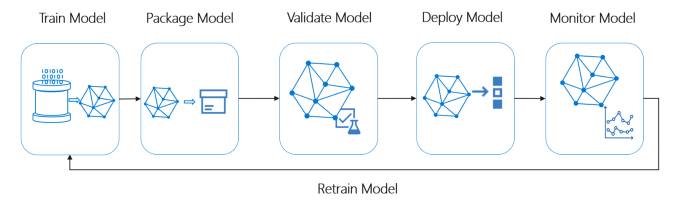
Crédito de la imagen: Microsoft MLOps
Una canalización ideal de ML debe seguir los siguientes conceptos:
- Gobernancia:
- Versionado del código del proyecto
- Versionado de datos
- Versionado del modelo
- Documentación
- Almacén de artefactos universal para almacenar activos versionados
- Plan de tubería genérico:
- Política común de descubrimiento + experimentación
- Seguimiento de experimentos (como algunas métricas, resultados, rendimiento)
- Una estrategia común para interconectar componentes de la tubería
- Publicar resultados
- Un mecanismo para reproducir, recrear, portar fácilmente
- Soporte para CI/CD
- Infraestructura suficiente para apoyar el desarrollo y la producción
- Fácil adaptación para producción y terminales
- Infraestructura de servicio escalable para atender solicitudes cada vez mayores
Descripción general de la canalización
- Una configuración de configuración de una sola vez con la pila
- Versión Dataset con DVC.
- Experimento de seguimiento de estrategias con MLflow/Wandb.
- Registre resultados, métricas, etc., con MLflow/Wandb en el almacén Universal Artifact (almacenamiento de blobs de Azure como back-end).
- Log Model (o cualquier activo relacionado) como activos versionados con MLflow/Wandb en la tienda Universal Artifact.
- Empaquete componentes individuales con Docker.
- Almacene los componentes del paquete con el repositorio de Docker deseado
- El empaquetado y la publicación deben realizarse utilizando el CI/CD.
- Programación de entrenamiento de modelos automatizado basado en monitoreo continuo para Data Drift.
Obtenga la certificación de ciencia de datos de las mejores universidades del mundo. Aprenda los programas Executive PG, los programas de certificación avanzada o los programas de maestría para acelerar su carrera.
Conclusión
Para seguir siendo un jugador relevante, ingenioso y clave en el equipo, es necesario aumentar nuestra tienda de conocimientos. Sin duda, ayudará a progresar en cualquier entorno competitivo.
Si está interesado en obtener más información sobre el aprendizaje automático, consulte el Diploma PG en aprendizaje automático e IA de IIIT-B y upGrad, que está diseñado para profesionales que trabajan y ofrece más de 450 horas de capacitación rigurosa, más de 30 estudios de casos y asignaciones, IIIT- B Estado de exalumno, más de 5 proyectos prácticos finales prácticos y asistencia laboral con las mejores empresas.