从初级数据科学家/机器学习到数据科学家/机器学习工程师专家
已发表: 2020-12-07从初级数据科学家/机器学习到全栈数据科学家/机器学习工程师
与三年甚至两年前相比,当前数据科学领域的前景发生了显着变化。 学习曲线永远不会结束。 因此,要想茁壮成长,就必须培养正确的技能来满足当前的行业期望。
“适应性是关于适应应对和适应胜利之间的巨大差异。” — 马克斯·麦基翁。
让我们看看可以帮助我们从初级数据科学家/机器学习转向全栈数据科学家/机器学习的关键要素。
目录
过去的期望
了解过去的责任以适应行业当前的期望至关重要。 因此,简而言之,过去数据科学家的日常角色通常包括:
- 人工智能领域仍然相对较新(尽管不是在学术界),许多公司、初创公司正在分析其应用和有效用例。
- 研究是主要焦点。 这里需要注意的是,这项研究多次与组织的核心并不直接一致。 因此,最初并没有预期的那么多可信度。
- 通常,公司过去常常将数据科学家与数据分析师或数据工程师的角色混合在一起。 再次,由于人工智能企业应用的模糊性。
- 个人也有类似的困境。 他们的许多研究或工作都不是直接的,实际上不可行作为产品。
当前展望
人工智能的民主化已经见证了公司和初创公司的显着发展。 让我们试着理解它,
- 业界现在区分了数据科学家、机器学习工程师、数据分析师、数据工程师,甚至是 MLops 工程师的角色。
- 企业不再允许在野外进行研究,因为他们知道他们究竟在利用什么用例。还需要个人清晰的心态和类似的离散方法。
- 每项研究或 POC 都必须有一个有形且可服务的产品。
另请阅读:机器学习职业
对所有角色的彻底剖析
如果我们必须选择一个企业在人工智能领域表现出色的领域,那无疑是各种角色的明确预期,简而言之:
- 数据科学家:数据科学家是指(通常来自统计/数学背景)使用包括人工智能在内的多种手段从数据中提取有价值信息的人。
- 数据分析师和数据科学家之间的一个根本区别是——前者通常依靠领域知识和传统的手工方法来理解中小规模的数据,而后者负责收集、分析和解释更大规模的数据使用更广泛的工具手段,如 AI、SQL、老式手动方式等,
- 领域知识不是必须的,但拥有是有帮助的。
- 主要工作是维护和从数据中提取业务贡献见解,而不是开发软件或产品。
- 统计学家或数学家可以成为优秀的数据科学家。
2.机器学习工程师:基于人工智能开发产品或服务的小众软件工程师。
- ML 工程师需要具备传统软件工程的所有专业知识以及 AI 知识,因为他/她最终将构建以 AI 为核心的软件。
- 主要工作不是提取数据,而是开发可以执行相同工作的人工智能工具。
- 具有良好机器学习/深度学习以及软件工程知识的开发人员可以成为优秀的机器学习工程师。
3.机器学习操作工程师:维护和自动化机器学习系统使用的管道的利基软件工程师。
- 受 DevOps 启发的相对较新的领域。 虽然不同于传统的 DevOps 角色。
- 与传统的软件工程不同,任何基于人工智能的产品/软件/服务的开发都不会在软件构建完成时停止。 它必须使用新数据定期更新,即“数据漂移”。
- 主要工作包括所有传统的 DevOps 工作以及维护/自动化管道和数据漂移
- 具有机器学习/深度学习、软件工程和云技术知识的开发人员可以成为优秀的 MlOps 工程师。
对于一个新的求职者或希望在他或她的职业生涯中取得进步的人来说,所有这些角色和期望都必须得到很好的理解。 鉴于公司明确区分了这一角色,预计个人也将如此。 模糊的心态是完全没用的。
全栈机器学习系统的堆栈
现在让我们进入关键点。 要成为一名全栈机器学习工程师,了解栈背后的概念是必要的。
什么是全栈?
- 与传统的软件工程类似,开发基于 AI 的系统也需要一套工具。 这个完整的套件可以称为全栈。
- 完整的堆栈通常使用三个构建块构建,即云技术、治理技术和人工智能技术。
- 有多个组件可用于跨三个构建块构建 AI 系统。 该列表包括配置、数据收集转换和验证、ML 代码(培训和验证)、资源(流程和机器)管理工具、服务基础设施、监控(可以与 Data Drift 结合使用)。 这个列表并不详尽,但它肯定是通用的,可以根据需要进行修改。
- 因此,为了坚持性能良好的 ML 系统,我们必须使用工具堆栈来覆盖所有上述组件,有时甚至不止一个组件。
设计全栈系统的能力有多重要?
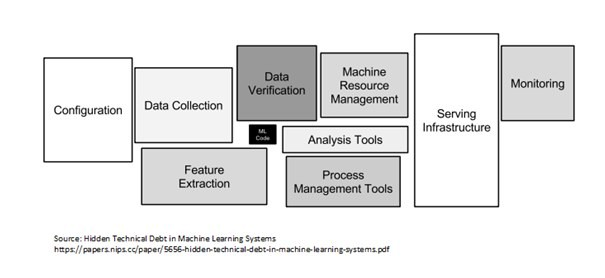

图片来源:机器学习系统论文中隐藏的技术债务
- 正如我上面提到的,如果没有产品的切实可持续性,今天的企业不允许进行研究/POC。
- 如果我说模型训练不是最重要的部分,我不会夸大其词,事实上,我会将它排在第三甚至第四。 能够设计和维护堆栈的人对公司至关重要,因为,
- 如果要训练模型的同一个人还维护数据管道(或贡献),那么他/她可以设计它以满足确切的需求。
- 了解部署基础架构将有助于构建更加以性能为中心的架构。
- 了解 Serving infra 将有助于速度和延迟部分(这通常是任何 ML 系统的最高要求)。
- 了解监控将有助于数据漂移和长期模型性能。
- 因此,了解这一切的个人可以使整个管道更高效并提高性能。 但最重要的是,它为公司节省了成本,因为现在一个人可以处理多个角色,从而增加了个人对公司的价值。
总而言之,重要的是不要只关注模型准确性,还要关注所有关键性能指标——速度、延迟、准确性、基础设施需求、服务请求等。
另请阅读:机器学习项目理念
全栈系统工作原理概述
Ideal ML System 的生命周期概览
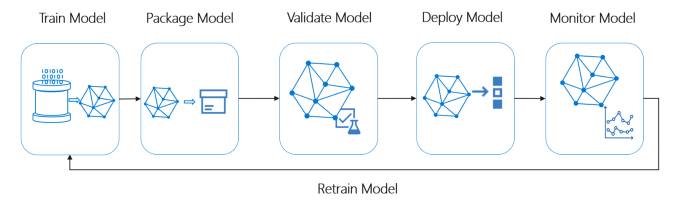
图片来源:微软 MLOps
理想的 ML 流水线必须遵循以下概念:
- 治理:
- 项目代码的版本控制
- 数据版本控制
- 模型的版本控制
- 文档
- 用于存储版本化资产的通用工件存储
- 通用管道蓝图:
- 共同发现+实验策略
- 实验跟踪(如一些指标、结果、性能)
- 互连管道组件的常用策略
- 发布结果
- 一种轻松复制、重新创建、移植的机制
- 支持 CI/CD
- 足够的基础设施来支持开发和生产
- 轻松适应生产和端点
- 可扩展的服务基础设施,以满足不断增长的需求
管道概述
- 使用堆栈的一次性设置配置
- 带有 DVC 的版本数据集。
- 使用 MLflow/Wandb 进行 Strat 跟踪实验。
- 在通用工件存储(Azure blob 存储作为后端)上使用 MLflow/Wandb 记录结果、指标等。
- 使用 MLflow/Wandb 将模型(或任何相关资产)作为版本化资产记录在 Universal Artifact 商店中。
- 使用 Docker 打包单个组件。
- 使用所需的 Docker 存储库存储包组件
- 打包和发布必须使用 CI/CD 完成。
- 基于数据漂移的持续监控调度自动化模型训练。
获得世界顶尖大学的数据科学认证。 学习行政 PG 课程、高级证书课程或硕士课程,以加快您的职业生涯。
结论
为了保持相关、足智多谋、关键的团队成员,有必要增加我们的知识帐篷。 毫无疑问,它将帮助一个人在任何竞争环境中取得进步。
如果您有兴趣了解有关机器学习的更多信息,请查看 IIIT-B 和 upGrad 的机器学习和人工智能 PG 文凭,该文凭专为工作专业人士设计,提供 450 多个小时的严格培训、30 多个案例研究和作业、IIIT- B 校友身份、5 个以上实用的实践顶点项目和顶级公司的工作协助。