De Cientista de Dados Jr/Aprendizado de Máquina a Cientista de Dados/Engenheiro de Aprendizado de Máquina Especialista
Publicados: 2020-12-07De Cientista de Dados Jr/Aprendizado de Máquina a Cientista de Dados Fullstack/Engenheiro de Aprendizado de Máquina
A perspectiva atual no campo da Ciência de Dados mudou significativamente em comparação com três ou até dois anos atrás. A curva de aprendizado nunca deve terminar. Portanto, para prosperar, é preciso desenvolver o conjunto de habilidades certo para atender às expectativas atuais do setor.
“Adaptabilidade é sobre a poderosa diferença entre se adaptar para lidar e se adaptar para vencer.” — Max McKeown.
Vejamos os principais elementos que podem nos ajudar a passar de Jr Data Scientist/Machine learning para Full stack Data Scientist/Machine learning.
Índice
A Expectativa Passada
É vital entender a responsabilidade passada para se adaptar às expectativas atuais da indústria. Então, em poucas palavras, o papel do dia-a-dia de um Cientista de Dados no passado geralmente envolvia:
- O espaço de IA ainda era relativamente novo (embora não no meio acadêmico) e muitas empresas, startups, estavam analisando sua aplicação e casos de uso válidos.
- A pesquisa foi o foco principal. A ressalva aqui foi que essa pesquisa muitas vezes não estava diretamente alinhada com o núcleo da organização. Então, inicialmente, não se esperava tanta credibilidade.
- Geralmente, as empresas costumavam combinar as funções de um Cientista de Dados com um Analista de Dados ou Engenheiro de Dados. Novamente, devido à imprecisão do aplicativo corporativo de IA.
- Os indivíduos também tinham um tipo de dilema semelhante. Muitas de suas pesquisas ou trabalhos não estavam diretamente alinhados, praticamente inviáveis para serem servidos como produto.
A Perspectiva Atual
A democratização da IA viu desenvolvimentos notáveis de empresas e startups. Tentemos entendê-lo,
- A indústria agora distingue o papel de um cientista de dados, engenheiro de aprendizado de máquina, analista de dados, engenheiro de dados e até engenheiro de MLops.
- As empresas não permitem mais pesquisas em estado selvagem, pois sabem exatamente em que caso de uso estão explorando. Também é necessária uma mentalidade clara e uma abordagem discreta semelhante de um indivíduo.
- Cada Pesquisa ou POC deve ter um produto tangível e servível.
Leia também: Carreira em Machine Learning
A dissecação completa de todos os papéis
Se tivermos que escolher uma área em que os Negócios se destacaram no espaço de IA, é sem dúvida a expectativa clara de todas as variedades dos Papéis, que estão em poucas palavras:
- Cientista de Dados: Um Cientista de Dados é uma pessoa que (geralmente com experiência em estatística/matemática) usa uma variedade de meios, incluindo IA, para extrair informações valiosas dos dados.
- Uma diferença fundamental entre Analista de Dados e Cientista de Dados é que o primeiro geralmente confia no conhecimento do domínio e nos métodos manuais da velha escola para dar sentido aos dados em pequena e média escala, enquanto o último é responsável por coletar, analisar e interpretar dados em uma escala maior usando meios mais amplos de ferramentas como IA, SQL, métodos manuais da velha escola, etc.,
- Conhecimento de domínio não é uma obrigação, mas ter é útil.
- O trabalho principal é manter e extrair insights de dados que contribuam para os negócios e não desenvolver o software ou produto.
- Um Estatístico ou um Matemático pode se tornar um bom Cientista de Dados.
2. Engenheiro de Machine Learning: Um engenheiro de software de nicho que desenvolve um produto ou serviço baseado em IA.
- Um engenheiro de ML precisa ter toda a experiência da engenharia de software tradicional, juntamente com o conhecimento de IA, porque ele/ela acabará construindo software com IA em seu coração.
- O trabalho principal não é extrair dados, mas desenvolver uma ferramenta de IA que possa realizar o mesmo trabalho.
- Um desenvolvedor com bom conhecimento de aprendizado de máquina/aprendizado profundo, bem como engenharia de software, pode se tornar um bom engenheiro de aprendizado de máquina.
3. Engenheiro de operação de aprendizado de máquina: um engenheiro de software de nicho que mantém e automatiza o pipeline usado pelo sistema de ML.
- Campo relativamente novo inspirado no DevOps. Embora diferente das funções tradicionais de DevOps.
- Ao contrário da engenharia de software tradicional, o desenvolvimento de qualquer produto/software/serviço baseado em IA não para na conclusão da construção do software. Ele deve ser atualizado regularmente com novos dados, que são 'Data-Drift'.
- O trabalho principal inclui todo o trabalho tradicional de DevOps, bem como manutenção/automatização de pipeline e Data-Drift
- Um desenvolvedor com bom conhecimento de aprendizado de máquina/aprendizado profundo, engenharia de software e tecnologias de nuvem pode se tornar um bom engenheiro de MlOps.
Para um novo candidato ou alguém que pretende avançar em sua carreira, todos esses papéis e expectativas devem ser bem compreendidos. Dado que as empresas estão a distinguir claramente este papel, espera-se que este também seja o caso das pessoas singulares. A mentalidade vaga é totalmente inútil.
A pilha de um sistema de aprendizado de máquina de pilha completa
Passemos agora ao ponto essencial. Para se tornar um engenheiro de aprendizado de máquina full stack, é necessário entender o conceito por trás da pilha.

O que é pilha completa?
- Semelhante à engenharia de software tradicional, o desenvolvimento de um sistema baseado em IA também precisa de um conjunto de ferramentas. Essa suíte completa pode ser chamada de Full Stack.
- A pilha completa é normalmente construída usando três componentes básicos, tecnologia de nuvem, tecnologia de governança e tecnologia de IA.
- Existem vários componentes para construir um sistema de IA nos três blocos de construção. A lista inclui configuração, transformação e verificação de coleta de dados, código ML (treinamento e validação), ferramentas de gerenciamento de recursos (processo e máquina), infraestrutura de serviço, monitoramento (pode ser combinado com o Data Drift). Esta lista não é exaustiva, mas é certamente genérica e pode ser modificada conforme necessário.
- Portanto, para aderir ao sistema de ML de bom desempenho, temos que usar a pilha de ferramentas para cobrir todos os componentes mencionados acima, às vezes até mais de um para uma única peça.
Qual é a importância da capacidade de projetar um sistema Full Stack?
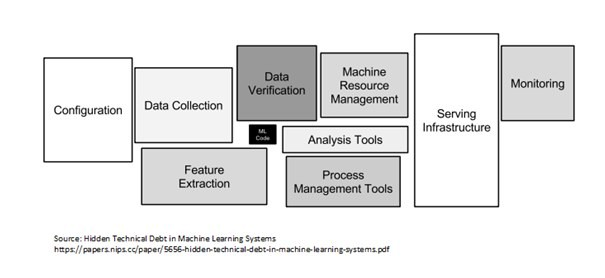
Crédito da foto: Dívida técnica oculta no documento de sistemas de aprendizado de máquina
- Como mencionei acima, os negócios de hoje não permitem pesquisa/POC sem sustentabilidade tangível do produto.
- Não estarei exagerando se disser que o treinamento do modelo não é a parte mais importante, na verdade, vou classificá-lo em terceiro ou até quarto. A pessoa que pode projetar e manter a pilha torna-se vital para a Empresa, pois,
- Se a mesma pessoa que vai treinar um modelo também mantiver um pipeline de dados (ou contribuir), ele poderá projetá-lo para atender às necessidades exatas.
- Compreender a infra de implantação ajudará a construir um desempenho mais centrado.
- Entender a infraestrutura de serviço ajudará na parte de velocidade e latência (que geralmente é o maior clamor para qualquer sistema de ML).
- Entender o monitoramento ajudará no Data Drift e no desempenho do modelo de longo prazo.
- Assim, um indivíduo sabendo de tudo isso pode tornar todo o pipeline mais eficiente e aumentar o desempenho. Mas, acima de tudo, economiza custos para a empresa, pois agora uma única pessoa pode lidar com várias funções, aumentando assim o valor do indivíduo para a empresa.
Portanto, para resumir, é essencial não apenas ficar obcecado com a precisão do modelo, mas também com todas as principais métricas de desempenho - velocidade, latência, precisão, necessidades de infra, solicitações de atendimento, etc.
Leia também: Ideias de projetos de aprendizado de máquina
Visão geral de como funciona um sistema full stack
Visão geral do ciclo de vida do sistema de ML ideal
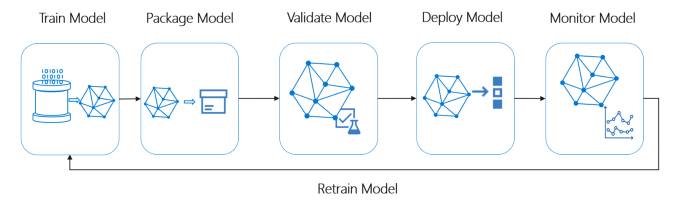
Crédito da foto: Microsoft MLOps
Um pipeline de ML ideal deve seguir os conceitos abaixo:
- Governança:
- Versionamento do código do projeto
- Versionamento de dados
- Versionamento do modelo
- Documentação
- Armazenamento universal de artefatos para armazenar ativos com versão
- Plano genérico de pipeline:
- Política comum de descoberta + experimentação
- Acompanhamento de experimentos (como algumas métricas, resultados, desempenho)
- Uma estratégia comum para interconectar componentes do pipeline
- Publicar resultados
- Um mecanismo para reproduzir, recriar, portar facilmente
- Suporte para CI/CD
- Infraestrutura suficiente para apoiar o desenvolvimento e a produção
- Fácil adaptação para produção e endpoints
- Infraestrutura de serviço escalável para atender a solicitações cada vez maiores
Visão geral do pipeline
- Uma configuração de configuração única com a pilha
- Conjunto de dados de versão com DVC.
- Experiência de rastreamento Strat com MLflow/Wandb.
- Resultados de log, métricas, etc., com MLflow/Wandb no armazenamento de artefatos universal (armazenamento de blobs do Azure como back-end).
- Modelo de log (ou quaisquer ativos relacionados) como ativos com versão com MLflow/Wandb no armazenamento de artefatos universais.
- Empacote componentes individuais com o Docker.
- Armazene os componentes do pacote com o repositório Docker desejado
- A embalagem e a publicação devem ser feitas usando o CI/CD.
- Agendamento de treinamento de modelo automatizado com base no monitoramento contínuo do Data Drift.
Obtenha a certificação em ciência de dados das melhores universidades do mundo. Aprenda Programas PG Executivos, Programas de Certificado Avançado ou Programas de Mestrado para acelerar sua carreira.
Conclusão
Para permanecer relevante, engenhoso e importante em equipe, é necessário aumentar nossa tenda de conhecimento. Sem dúvida, ajudará a pessoa a progredir em qualquer ambiente competitivo.
Se você estiver interessado em aprender mais sobre aprendizado de máquina, confira o PG Diploma in Machine Learning & AI do IIIT-B e upGrad, projetado para profissionais que trabalham e oferece mais de 450 horas de treinamento rigoroso, mais de 30 estudos de caso e atribuições, IIIT- B Status de ex-aluno, mais de 5 projetos práticos práticos e assistência de trabalho com as principais empresas.