Da Jr Data Scientist/Machine learning a Data Scientist/Machine Learning Engineer Expert
Pubblicato: 2020-12-07Da Jr Data Scientist/Apprendimento automatico a Data Scientist/Ingegnere di apprendimento automatico full-stack
L'attuale prospettiva nel campo della scienza dei dati è cambiata in modo significativo rispetto a tre o anche due anni fa. La curva di apprendimento non dovrebbe mai finire. Quindi, per prosperare, è necessario sviluppare il giusto set di competenze per soddisfare le attuali aspettative del settore.
"L'adattabilità riguarda la potente differenza tra adattarsi per far fronte e adattarsi per vincere". — Max McKeown.
Diamo un'occhiata agli elementi chiave che possono aiutarci a passare da Jr Data Scientist / Machine learning a Full stack Data Scientist / Machine learning.
Sommario
L'aspettativa passata
È fondamentale comprendere la responsabilità passata per adattarsi alle attuali aspettative del settore. Quindi, in poche parole, il ruolo quotidiano di un Data Scientist in passato generalmente prevedeva:
- Lo spazio dell'IA era ancora relativamente nuovo (sebbene non negli accademici) e molte aziende e startup ne stavano analizzando l'applicazione e il caso d'uso valido.
- La ricerca era l'obiettivo principale. L'avvertenza qui era che questa ricerca molte volte non era direttamente in linea con il nucleo dell'organizzazione. Quindi inizialmente non ci si aspettava così tanta credibilità.
- In genere, le aziende univano i ruoli di un Data Scientist con un Data Analyst o un Data Engineer. Ancora una volta, a causa della vaghezza dell'applicazione aziendale AI.
- Gli individui avevano anche una specie di dilemma simile. Molte delle loro ricerche o del loro lavoro non erano direttamente in linea, praticamente non praticabili per essere serviti come prodotto.
La prospettiva attuale
La democratizzazione dell'IA ha visto notevoli sviluppi da parte di aziende e startup. Proviamo a capirlo,
- Il settore ora distingue il ruolo di Data Scientist, Machine Learning Engineer, Data Analyst, Data Engineer e persino MLops engineer.
- Le aziende non consentono più la ricerca in natura, poiché sanno esattamente quale caso d'uso stanno attingendo. Sono inoltre necessari una mentalità chiara e un approccio discreto simile da parte di un individuo.
- Ogni Ricerca o POC deve avere un prodotto tangibile e fruibile.
Leggi anche: Carriera nell'apprendimento automatico
La dissezione approfondita di tutti i Ruoli
Se dobbiamo scegliere un'area in cui le aziende hanno eccelso nello spazio dell'IA, è senza dubbio la chiara aspettativa da tutte le varietà dei ruoli, che sono in poche parole:
- Data Scientist: un Data Scientist è una persona che (generalmente con un background di statistiche/matematica) utilizza una varietà di mezzi, inclusa l'IA, per estrarre informazioni preziose dai dati.
- Una differenza fondamentale tra Data Analyst e Data Scientist è: il primo generalmente si basa sulla conoscenza del dominio e sui metodi manuali della vecchia scuola per dare un senso ai dati su scala piccola e media, mentre il secondo è responsabile della raccolta, dell'analisi e dell'interpretazione dei dati su scala più ampia utilizzando strumenti più ampi come AI, SQL, metodi manuali della vecchia scuola, ecc.,
- La conoscenza del dominio non è un must, ma avere è utile.
- Il compito principale è mantenere ed estrarre informazioni utili per il business dai dati e non sviluppare il software o il prodotto.
- Uno statistico o un matematico possono diventare un buon Data Scientist.
2. Machine Learning Engineer: un ingegnere del software di nicchia che sviluppa un prodotto o servizio basato sull'IA.
- Un ingegnere ML deve possedere tutta l'esperienza dell'ingegneria del software tradizionale insieme alla conoscenza dell'IA perché alla fine costruirà software con l'IA al centro.
- Il compito principale non è estrarre i dati ma sviluppare uno strumento di intelligenza artificiale in grado di eseguire lo stesso lavoro.
- Uno sviluppatore con una buona conoscenza dell'apprendimento automatico/deep learning e dell'ingegneria del software può diventare un buon ingegnere dell'apprendimento automatico.
3. Machine Learning Operation Engineer: un ingegnere software di nicchia che mantiene e automatizza la pipeline utilizzata dal sistema ML.
- Campo relativamente nuovo ispirato a DevOps. Sebbene diverso dai ruoli DevOps tradizionali.
- A differenza dell'ingegneria del software tradizionale, lo sviluppo di qualsiasi prodotto/software/servizio basato sull'IA non si ferma al completamento della costruzione del software. Deve essere aggiornato regolarmente con nuovi dati, ovvero 'Data-Drift'.
- Il lavoro principale include tutto il lavoro DevOps tradizionale, nonché la manutenzione/automazione della pipeline e la deriva dei dati
- Uno sviluppatore con una buona conoscenza di machine learning/deep learning, ingegneria del software e tecnologie cloud può diventare un buon ingegnere MlOps.
Per un nuovo cercatore o qualcuno che mira ad avanzare nella sua carriera, tutti questi ruoli e aspettative devono essere ben compresi. Dato che le aziende stanno distinguendo chiaramente questo ruolo, si prevede che ciò varrà anche per gli individui. La mentalità vaga è totalmente inutile.
Lo stack di un sistema di Machine Learning a stack completo
Passiamo ora al punto essenziale. Per diventare un Full stack Machine Learning Engineer, è necessario comprendere il concetto alla base dello stack.

Cos'è lo stack completo?
- Simile all'ingegneria del software tradizionale, anche lo sviluppo di un sistema basato sull'intelligenza artificiale richiede una suite di strumenti. Questa suite completa può essere definita Full Stack.
- L'intero stack viene in genere creato utilizzando tre elementi costitutivi, la tecnologia Cloud, la tecnologia Governance e la tecnologia AI.
- Ci sono più componenti per costruire un sistema di intelligenza artificiale attraverso i tre elementi costitutivi. L'elenco include Configurazione, Trasformazione e verifica della raccolta dati, Codice ML (formazione e convalida), Strumenti di gestione delle risorse (processi e macchine), Infrastruttura di servizio, Monitoraggio (può essere associato a Data Drift). Questo elenco non è esaustivo, ma è certamente generico e può essere modificato secondo necessità.
- Quindi, per aderire al sistema ML ben performante, dobbiamo utilizzare la pila di strumenti per coprire tutti i componenti sopra menzionati, a volte anche più di uno per una singola parte.
Qual è l'importanza della capacità di progettare un sistema Full stack?
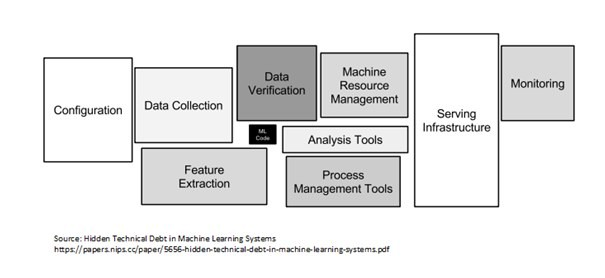
Pic Credit: debito tecnico nascosto nella carta dei sistemi di apprendimento automatico
- Come accennato in precedenza, le aziende di oggi non consentono la ricerca/POC senza una tangibile sostenibilità del prodotto.
- Non esagero se dico che la formazione del modello non è la parte più importante, anzi la classificherò terza o addirittura quarta. La persona che può progettare e mantenere lo stack diventa vitale per l'Azienda, perché,
- Se la stessa persona che sta per addestrare un modello mantiene anche una pipeline di dati (o contribuisce), allora può progettarla per soddisfare le esigenze esatte.
- Comprendere l'infrastruttura di distribuzione aiuterà a creare un ambiente più incentrato sulle prestazioni.
- Comprendere Servire infra aiuterà nella parte di velocità e latenza (che è generalmente il grido più alto per qualsiasi sistema ML).
- Comprendere il monitoraggio aiuterà con Data Drift e nelle prestazioni del modello a lungo termine.
- Quindi, un individuo che conosce tutto questo può rendere l'intera pipeline più efficiente e aumentare le prestazioni. Ma soprattutto, consente di risparmiare sui costi per l'azienda poiché ora una singola persona può gestire più ruoli, aumentando così a sua volta il valore dell'individuo per l'azienda.
Quindi, per riassumere, è essenziale non essere solo ossessionato dall'accuratezza del modello, ma ossessionato da tutte le metriche chiave delle prestazioni: velocità, latenza, precisione, esigenze interne, richieste di servizio, ecc.
Leggi anche: Idee per progetti di apprendimento automatico
Panoramica di come funziona un sistema full stack
Panoramica del ciclo di vita del sistema Ideal ML
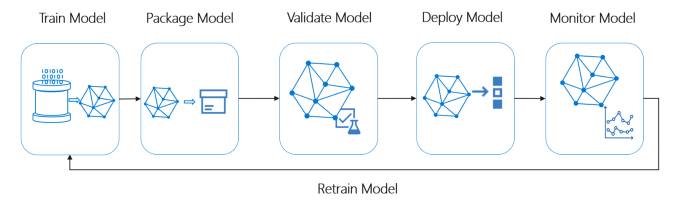
Credito foto: Microsoft MLOps
Una pipeline ML ideale deve seguire i seguenti concetti:
- Governo:
- Versione del codice del progetto
- Versione dei dati
- Versionamento del modello
- Documentazione
- Negozio di artefatti universale per archiviare risorse con versione
- Progetto di pipeline generico:
- Politica comune di scoperta + sperimentazione
- Monitoraggio degli esperimenti (come alcune metriche, risultati, prestazioni)
- Una strategia comune per interconnettere i componenti del gasdotto
- Pubblica i risultati
- Un meccanismo per riprodurre, ricreare, portare facilmente
- Supporto per CI/CD
- Infra sufficienti per supportare lo sviluppo e la produzione
- Facile adattamento per la produzione e gli endpoint
- Scalabile Servire infra per soddisfare le richieste sempre crescenti
Panoramica della pipeline
- Una configurazione di impostazione una tantum con lo stack
- Versione Dataset con DVC.
- Esperimento di tracciamento Stratocaster con MLflow/Wandb.
- Registra risultati, metriche e così via con MLflow/Wandb in Universal Artifact Store (archiviazione BLOB di Azure come back-end).
- Log Model (o qualsiasi risorsa correlata) come asset con versione con MLflow/Wandb su Universal Artifact Store.
- Pacchetto di singoli componenti con Docker.
- Archivia i componenti del pacchetto con il repository Docker desiderato
- Il packaging e la pubblicazione devono essere eseguiti utilizzando il CI/CD.
- Pianificazione dell'addestramento automatizzato del modello basato sul monitoraggio continuo per Data Drift.
Ottieni la certificazione di data science dalle migliori università del mondo. Impara i programmi Executive PG, Advanced Certificate Program o Master per accelerare la tua carriera.
Conclusione
Per rimanere un giocatore di squadra rilevante, pieno di risorse e chiave, è necessario aumentare la nostra tenda della conoscenza. Aiuterà senza dubbio a progredire in qualsiasi ambiente competitivo.
Se sei interessato a saperne di più sull'apprendimento automatico, dai un'occhiata al Diploma PG di IIIT-B e upGrad in Machine Learning e AI, progettato per i professionisti che lavorano e offre oltre 450 ore di formazione rigorosa, oltre 30 casi di studio e incarichi, IIIT- B Status di Alumni, oltre 5 progetti pratici pratici e assistenza sul lavoro con le migliori aziende.