
สถาปัตยกรรม CNN ขั้นพื้นฐาน: การอธิบาย 5 ชั้นของ Convolutional Neural Network
เผยแพร่แล้ว: 2020-12-07สารบัญ
บทนำ
ในช่วงไม่กี่ปีที่ผ่านมาของอุตสาหกรรมไอที มีความต้องการอย่างมากสำหรับชุดทักษะเฉพาะที่เรียกว่าการเรียนรู้เชิงลึก Deep Learning เป็นส่วนย่อยของ Machine Learning ซึ่งประกอบด้วยอัลกอริธึมที่ได้รับแรงบันดาลใจจากการทำงานของสมองมนุษย์หรือโครงข่ายประสาทเทียม
โครงสร้างเหล่านี้เรียกว่าโครงข่ายประสาทเทียม มันสอนคอมพิวเตอร์ให้ทำในสิ่งที่มนุษย์เกิดตามธรรมชาติ การเรียนรู้เชิงลึก มีโมเดลหลายประเภท เช่น Artificial Neural Networks (ANN), Autoencoders, Recurrent Neural Networks (RNN) และ Reinforcement Learning แต่มีรูปแบบหนึ่งที่มีส่วนร่วมอย่างมากในด้านการมองเห็นด้วยคอมพิวเตอร์และการวิเคราะห์ภาพ ซึ่งก็คือ Convolutional Neural Networks (CNN) หรือ ConvNets
CNN เป็นคลาสของ Deep Neural Networks ที่สามารถจดจำและจำแนกคุณลักษณะเฉพาะจากรูปภาพ และใช้กันอย่างแพร่หลายในการวิเคราะห์ภาพ การใช้งานมีตั้งแต่การจดจำภาพและวิดีโอ การจำแนกภาพ การวิเคราะห์ภาพทางการแพทย์ คอมพิวเตอร์วิทัศน์ และการประมวลผลภาษาธรรมชาติ
คำว่า 'Convolution' ใน CNN หมายถึงฟังก์ชันทางคณิตศาสตร์ของการ convolution ซึ่งเป็นชนิดพิเศษของการดำเนินการเชิงเส้นตรงซึ่งฟังก์ชันสองฟังก์ชันจะถูกคูณเพื่อสร้างฟังก์ชันที่สามซึ่งแสดงว่ารูปร่างของฟังก์ชันหนึ่งถูกแก้ไขโดยอีกฟังก์ชันหนึ่งอย่างไร พูดง่ายๆ ก็คือ รูปภาพสองรูปที่สามารถแสดงเป็นเมทริกซ์ได้จะถูกคูณเพื่อให้ได้ผลลัพธ์ที่ใช้ในการแยกคุณลักษณะออกจากรูปภาพ
เรียนรู้แมชชีนเลิร์นนิงออนไลน์ จากมหาวิทยาลัยชั้นนำของโลก – ปริญญาโท หลักสูตร Executive Post Graduate และหลักสูตรประกาศนียบัตรขั้นสูงใน ML & AI เพื่อติดตามอาชีพของคุณอย่างรวดเร็ว
เรียนรู้: บทนำสู่การเรียนรู้เชิงลึกและโครงข่ายประสาทเทียม

สถาปัตยกรรมพื้นฐาน
มีสองส่วนหลักในสถาปัตยกรรม CNN
- เครื่องมือ Convolution ที่แยกและระบุคุณลักษณะต่างๆ ของรูปภาพเพื่อการวิเคราะห์ในกระบวนการที่เรียกว่า Feature Extraction
- เลเยอร์ที่เชื่อมต่ออย่างสมบูรณ์ซึ่งใช้เอาต์พุตจากกระบวนการบิดและคาดการณ์คลาสของรูปภาพตามคุณสมบัติที่ดึงออกมาในขั้นตอนก่อนหน้า
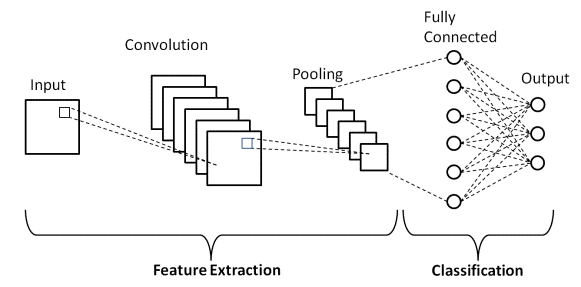
แหล่งที่มา
Convolution Layers
เลเยอร์ที่ประกอบเป็น CNN มีอยู่สามประเภทด้วยกัน ได้แก่ ชั้นแบบ Convolutional ชั้นแบบรวม และชั้นแบบเชื่อมต่อทั้งหมด (FC) เมื่อเลเยอร์เหล่านี้ซ้อนกัน สถาปัตยกรรม CNN จะถูกสร้างขึ้น นอกจากสามเลเยอร์นี้แล้ว ยังมีพารามิเตอร์ที่สำคัญอีก 2 ตัว ได้แก่ เลเยอร์ดร็อปเอาต์และฟังก์ชันการเปิดใช้งานซึ่งกำหนดไว้ด้านล่าง
1. Convolutional Layer
เลเยอร์นี้เป็นเลเยอร์แรกที่ใช้เพื่อแยกคุณสมบัติต่างๆ ออกจากรูปภาพที่ป้อน ในเลเยอร์นี้ การดำเนินการทางคณิตศาสตร์ของการบิดจะดำเนินการระหว่างรูปภาพที่ป้อนเข้าและตัวกรองขนาด MxM เฉพาะ การเลื่อนตัวกรองไปเหนือภาพที่ป้อนเข้าไป ผลิตภัณฑ์ดอทจะถูกถ่ายระหว่างฟิลเตอร์กับส่วนต่างๆ ของภาพที่ป้อนโดยสัมพันธ์กับขนาดของฟิลเตอร์ (MxM)
ผลลัพธ์เรียกว่าเป็นแผนผังคุณลักษณะซึ่งให้ข้อมูลเกี่ยวกับภาพ เช่น มุมและขอบ ต่อมา แมปคุณลักษณะนี้จะป้อนไปยังเลเยอร์อื่นๆ เพื่อเรียนรู้คุณลักษณะอื่นๆ ของภาพที่ป้อน
2. การรวมเลเยอร์
ในกรณีส่วนใหญ่ Convolutional Layer จะตามด้วย Pooling Layer เป้าหมายหลักของเลเยอร์นี้คือการลดขนาดของแผนผังคุณลักษณะที่รวมเข้าด้วยกันเพื่อลดต้นทุนในการคำนวณ ทำได้โดยการลดการเชื่อมต่อระหว่างเลเยอร์และดำเนินการอย่างอิสระในแต่ละแผนที่คุณลักษณะ ขึ้นอยู่กับวิธีการที่ใช้ มีการดำเนินการรวมหลายประเภท
ใน Max Pooling องค์ประกอบที่ใหญ่ที่สุดจะถูกนำมาจากฟีเจอร์แมป การรวมค่าเฉลี่ยจะคำนวณค่าเฉลี่ยขององค์ประกอบในส่วนรูปภาพขนาดที่กำหนดไว้ล่วงหน้า ผลรวมทั้งหมดขององค์ประกอบในส่วนที่กำหนดไว้ล่วงหน้าจะถูกคำนวณในการรวมรวม Pooling Layer มักจะทำหน้าที่เป็นสะพานเชื่อมระหว่าง Convolutional Layer และ FC Layer
ต้องอ่าน: แนวคิดโครงการโครงข่ายประสาทเทียม
3. เชื่อมต่ออย่างสมบูรณ์ Layer
เลเยอร์ที่เชื่อมต่ออย่างสมบูรณ์ (FC) ประกอบด้วยน้ำหนักและความเอนเอียงพร้อมกับเซลล์ประสาท และใช้เพื่อเชื่อมต่อเซลล์ประสาทระหว่างสองชั้นที่ต่างกัน เลเยอร์เหล่านี้มักจะถูกวางไว้ก่อนเลเยอร์เอาต์พุตและก่อตัวเป็นสองสามเลเยอร์สุดท้ายของสถาปัตยกรรม CNN
ในสิ่งนี้ รูปภาพอินพุตจากเลเยอร์ก่อนหน้าจะถูกทำให้แบนและป้อนไปยังเลเยอร์ FC เวกเตอร์ที่แบนแล้วผ่านชั้น FC อีกสองสามชั้น ซึ่งโดยปกติแล้วการดำเนินการฟังก์ชันทางคณิตศาสตร์จะเกิดขึ้น ในขั้นตอนนี้ กระบวนการจัดหมวดหมู่จะเริ่มขึ้น
4. การออกกลางคัน
โดยปกติ เมื่อคุณลักษณะทั้งหมดเชื่อมต่อกับเลเยอร์ FC อาจทำให้เกิดการใส่ชุดข้อมูลการฝึกมากเกินไป Overfitting เกิดขึ้นเมื่อแบบจำลองใดรุ่นหนึ่งทำงานได้ดีกับข้อมูลการฝึก ทำให้เกิดผลกระทบด้านลบต่อประสิทธิภาพของแบบจำลองเมื่อใช้กับข้อมูลใหม่
เพื่อแก้ปัญหานี้ เลเยอร์ดรอปเอาท์ถูกใช้โดยที่เซลล์ประสาทบางส่วนหลุดออกจากโครงข่ายประสาทระหว่างกระบวนการฝึก ส่งผลให้ขนาดของโมเดลลดลง เมื่อผ่านการดรอปเอาท์ 0.3 30% ของโหนดจะถูกสุ่มออกจากโครงข่ายประสาทเทียม
5. ฟังก์ชั่นการเปิดใช้งาน
สุดท้าย หนึ่งในพารามิเตอร์ที่สำคัญที่สุดของโมเดล CNN คือฟังก์ชันการเปิดใช้งาน ใช้เพื่อเรียนรู้และประมาณความสัมพันธ์ที่ต่อเนื่องและซับซ้อนระหว่างตัวแปรต่างๆ ของเครือข่าย พูดง่ายๆ ก็คือ มันตัดสินใจว่าข้อมูลใดของโมเดลควรจะยิงไปในทิศทางไปข้างหน้าและข้อมูลที่ไม่ควรอยู่ที่ส่วนท้ายของเครือข่าย

มันเพิ่มความไม่เป็นเชิงเส้นให้กับเครือข่าย มีฟังก์ชันการเปิดใช้งานที่ใช้กันทั่วไปหลายอย่าง เช่น ReLU, Softmax, tanH และฟังก์ชัน Sigmoid แต่ละฟังก์ชันเหล่านี้มีการใช้งานเฉพาะ สำหรับแบบจำลอง CNN การจำแนกแบบไบนารี ควรใช้ฟังก์ชัน sigmoid และ softmax สำหรับการจำแนกประเภทหลายคลาส โดยทั่วไปเราจะใช้ softmax
สถาปัตยกรรม LeNet-5 CNN
ในปี 1998 สถาปัตยกรรม LeNet-5 ถูกนำมาใช้ในงานวิจัยเรื่อง "Gradient-Based Learning Applied to Document Recognition" โดย Yann LeCun, Leon Bottou, Yoshua Bengio และ Patrick Haffner เป็นหนึ่งในสถาปัตยกรรม CNN ที่เก่าที่สุดและเป็นพื้นฐานที่สุด
ประกอบด้วย 7 ชั้น เลเยอร์แรกประกอบด้วยรูปภาพอินพุตที่มีขนาด 32×32 ถูกรวมเข้าด้วยกันด้วยฟิลเตอร์ 6 ตัว ขนาด 5×5 ส่งผลให้มีขนาด 28x28x6 ชั้นที่สองคือการดำเนินการรวมกลุ่มซึ่งขนาดฟิลเตอร์ 2×2 และระยะที่ 2 ดังนั้นขนาดของภาพที่ได้จะเป็น 14x14x6
ในทำนองเดียวกัน ชั้นที่สามยังเกี่ยวข้องกับการดำเนินการบิดด้วยตัวกรอง 16 ขนาด 5×5 ตามด้วยชั้นรวมที่สี่ซึ่งมีขนาดตัวกรองใกล้เคียงกันคือ 2×2 และระยะที่ 2 ดังนั้นขนาดภาพที่ได้จะลดลงเหลือ 5x5x16
เมื่อลดขนาดภาพลง เลเยอร์ที่ 5 จะเป็นเลเยอร์ Convolutional ที่เชื่อมต่ออย่างสมบูรณ์ โดยมีตัวกรอง 120 ตัวต่อขนาด 5×5 ในเลเยอร์นี้ แต่ละ 120 ยูนิตในเลเยอร์นี้จะเชื่อมต่อกับยูนิต 400 (5x5x16) จากเลเยอร์ก่อนหน้า เลเยอร์ที่หกยังเป็นเลเยอร์ที่เชื่อมต่ออย่างสมบูรณ์ด้วย 84 ยูนิต
เลเยอร์ที่เจ็ดสุดท้ายจะเป็นเลเยอร์เอาต์พุต softmax โดยมีคลาสที่เป็นไปได้ 'n' ขึ้นอยู่กับจำนวนคลาสในชุดข้อมูล
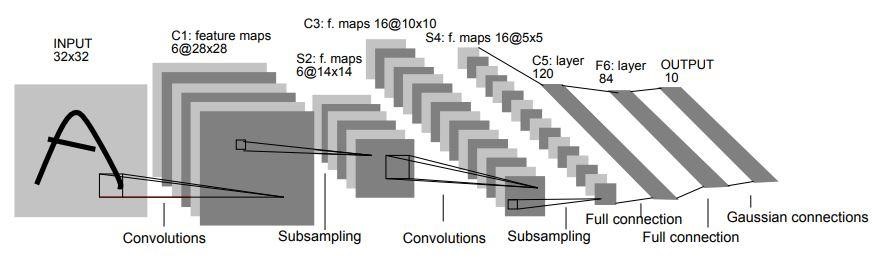
แหล่งที่มา
แผนภาพด้านบนเป็นตัวแทนของ 7 เลเยอร์ของสถาปัตยกรรม LeNet-5 CNN
ด้านล่างนี้คือสแน็ปช็อตของโค้ด Python เพื่อสร้างสถาปัตยกรรม LeNet-5 CNN โดยใช้ไลบรารี keras พร้อมเฟรมเวิร์ก TensorFlow

ในการเขียนโปรแกรม Python ประเภทโมเดลที่ใช้บ่อยที่สุดคือประเภท Sequential เป็นวิธีที่ง่ายที่สุดในการสร้างโมเดล CNN ใน keras อนุญาตให้เราสร้างแบบจำลองทีละชั้น ฟังก์ชัน 'add()' ใช้สำหรับเพิ่มเลเยอร์ให้กับโมเดล ตามที่อธิบายไว้ข้างต้น สำหรับสถาปัตยกรรม LeNet-5 มีคู่ Convolution และ Pooling สองคู่ ตามด้วยเลเยอร์ Flatten ซึ่งมักใช้เป็นการเชื่อมต่อระหว่าง Convolution และเลเยอร์ Dense
เลเยอร์หนาแน่นเป็นเลเยอร์ที่ใช้เป็นส่วนใหญ่สำหรับเลเยอร์เอาต์พุต การเปิดใช้งานที่ใช้คือ 'Softmax' ซึ่งให้ความน่าจะเป็นสำหรับแต่ละคลาสและรวมเป็น 1 ทั้งหมด โมเดลจะทำการทำนายตามคลาสที่มีความเป็นไปได้สูงสุด
บทสรุปของโมเดลแสดงไว้ดังนี้
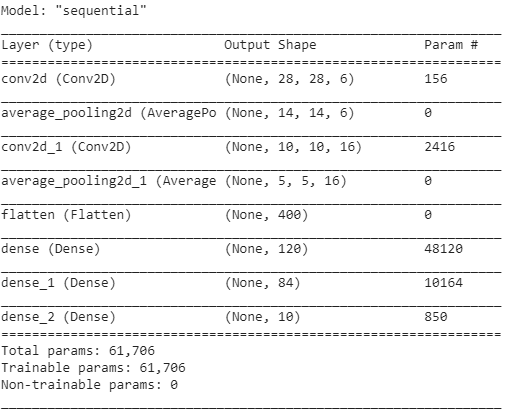
บทสรุป
ดังนั้น ในบทความนี้ เราจึงได้เข้าใจโครงสร้างพื้นฐานของ CNN นั่นคือสถาปัตยกรรม และเลเยอร์ต่างๆ ที่ประกอบเป็นโมเดล CNN นอกจากนี้เรายังได้เห็นตัวอย่างสถาปัตยกรรมของโมเดล LeNet-5 ที่มีชื่อเสียงและดั้งเดิมด้วยโปรแกรม Python
หากคุณสนใจที่จะเรียนรู้เพิ่มเติมเกี่ยวกับ หลักสูตร แมชชีนเลิร์นนิง ลองดู โปรแกรม Executive PG ของ IIIT-B และ upGrad ในการเรียนรู้ของเครื่องและ AI ซึ่งออกแบบมาสำหรับมืออาชีพที่ทำงานและมีการฝึกอบรมที่เข้มงวดมากกว่า 450 ชั่วโมง กรณีศึกษาและการมอบหมายมากกว่า 30 รายการ สถานะศิษย์เก่า IIIT-B โครงการหลัก 5 โครงการและความช่วยเหลือด้านงานกับบริษัทชั้นนำ
ฟังก์ชั่นการเปิดใช้งานใน CNN คืออะไร?
ฟังก์ชันการเปิดใช้งานเป็นหนึ่งในองค์ประกอบที่สำคัญที่สุดในแบบจำลอง CNN พวกมันถูกใช้เพื่อเรียนรู้และประมาณรูปแบบใดๆ ของการเชื่อมโยงแบบแปรผันกับตัวแปรของเครือข่ายที่มีทั้งแบบต่อเนื่องและแบบซับซ้อน กล่าวอย่างง่าย ๆ คือกำหนดว่าข้อมูลรุ่นใดควรไหลไปในทิศทางไปข้างหน้าและไม่ควรอยู่ที่ส่วนท้ายของเครือข่าย มันทำให้เครือข่ายไม่เป็นเชิงเส้น ฟังก์ชัน ReLU, Softmax, tanH และ Sigmoid เป็นฟังก์ชันการเปิดใช้งานที่ใช้บ่อยที่สุดบางส่วน ฟังก์ชันทั้งหมดนี้มีการใช้งานที่แตกต่างกัน สำหรับโมเดล CNN 2 คลาส ฟังก์ชัน sigmoid และ softmax เป็นที่นิยม ในขณะที่โดยทั่วไปแล้ว softmax จะใช้สำหรับการจำแนกประเภทหลายคลาส
อะไรคือองค์ประกอบพื้นฐานของสถาปัตยกรรมโครงข่ายประสาทเทียมแบบ Convolutional?
เลเยอร์อินพุต เลเยอร์เอาต์พุต และเลเยอร์ที่ซ่อนอยู่หลายชั้นประกอบเป็นเครือข่ายแบบ Convolutional เซลล์ประสาทในชั้นของโครงข่ายแบบบิดงอถูกจัดเรียงเป็นสามมิติ ไม่เหมือนกับเซลล์ประสาทในโครงข่ายประสาทมาตรฐาน (ขนาดความกว้าง ความสูง และความลึก) สิ่งนี้ทำให้ CNN สามารถแปลงโวลุ่มอินพุตสามมิติเป็นโวลุ่มเอาต์พุตได้ Convolution, pooling, normalizing และเชื่อมต่ออย่างสมบูรณ์เป็นเลเยอร์ที่ซ่อนอยู่ มีการใช้เลเยอร์ Conv. หลายชั้นใน CNN เพื่อกรองปริมาณอินพุตไปยังระดับนามธรรมที่สูงขึ้น
ประโยชน์ของสถาปัตยกรรม CNN มาตรฐานคืออะไร?
แม้ว่าสถาปัตยกรรมเครือข่ายแบบดั้งเดิมจะประกอบด้วยชั้น Convolutional ที่ซ้อนกันเพียงอย่างเดียว แต่สถาปัตยกรรมที่ใหม่กว่าจะมองหาวิธีการใหม่และแปลกใหม่ในการสร้างเลเยอร์ Convolutional เพื่อปรับปรุงประสิทธิภาพการเรียนรู้ สถาปัตยกรรมเหล่านี้ให้คำแนะนำสถาปัตยกรรมทั่วไปสำหรับผู้ปฏิบัติงานการเรียนรู้ด้วยเครื่องเพื่อปรับตัวเพื่อจัดการกับปัญหาการมองเห็นคอมพิวเตอร์ที่หลากหลาย สถาปัตยกรรมเหล่านี้สามารถใช้เป็นตัวแยกคุณลักษณะที่หลากหลายสำหรับการจัดประเภทรูปภาพ การระบุวัตถุ การแบ่งส่วนรูปภาพ และงานขั้นสูงอื่นๆ ที่หลากหลาย