Od Jr Data Scientist/Machine Learning do Data Scientist/Machine Learning Engineer Expert
Opublikowany: 2020-12-07Od Jr Data Scientist/Machine learning do Full-stack Data Scientist/Machine learning?
Obecna perspektywa w dziedzinie Data Science znacznie się zmieniła w porównaniu do trzech, a nawet dwóch lat temu. Krzywa uczenia się nigdy nie powinna się kończyć. Aby więc prosperować, należy rozwinąć odpowiedni zestaw umiejętności, aby spełnić obecne oczekiwania branży.
„Zdolność do adaptacji to potężna różnica między przystosowaniem się do radzenia sobie a przystosowaniem się do zwycięstwa”. — Max McKeown.
Przyjrzyjmy się kluczowym elementom, które mogą nam pomóc w przejściu od Jr Data Scientist / Machine Learning do Full Stack Data Scientist / Machine Learning.
Spis treści
Przeszłe oczekiwania
Niezbędne jest zrozumienie przeszłej odpowiedzialności za dostosowanie się do obecnych oczekiwań branży. Krótko mówiąc, codzienna rola analityka danych w przeszłości obejmowała:
- Przestrzeń AI była wciąż stosunkowo nowa (choć nie w środowisku akademickim), a wiele firm, startupów analizowało jej zastosowanie i prawidłowy przypadek użycia.
- Głównym celem było badanie. Zastrzeżeniem było to, że te badania wielokrotnie nie były bezpośrednio zgodne z rdzeniem organizacji. Tak więc początkowo nie oczekiwano tak dużej wiarygodności.
- Generalnie firmy łączyły role analityka danych z analitykiem danych lub inżynierem danych. Ponownie, ze względu na niejasność aplikacji korporacyjnej AI.
- Podobny dylemat mieli też jednostki. Wiele z ich badań lub prac nie było bezpośrednio zgodnych, praktycznie nieopłacalnych, aby służyć jako produkt.
Obecna perspektywa
Demokratyzacja sztucznej inteligencji przyniosła niezwykły rozwój firm i start-upów. Spróbujmy to zrozumieć,
- Branża wyróżnia teraz rolę naukowca danych, inżyniera uczenia maszynowego, analityka danych, inżyniera danych, a nawet inżyniera MLops.
- Firmy nie pozwalają już na prowadzenie badań na wolności, ponieważ wiedzą dokładnie, w jakim przypadku używają. Wymagane jest również jasne nastawienie i podobne dyskretne podejście ze strony osoby.
- Każdy Research lub POC musi mieć namacalny i serwowalny produkt.
Przeczytaj także: Kariera w uczeniu maszynowym
Dokładna analiza wszystkich ról
Jeśli musimy wybrać jeden obszar, w którym firmy celowały w przestrzeni AI, jest to niewątpliwie jasne oczekiwanie ze wszystkich odmian ról, które są w skrócie:
- Data Scientist: Data Scientist to osoba, która (zwykle ze statystyk/matematyki) używa różnych środków, w tym sztucznej inteligencji, do wydobywania cennych informacji z danych.
- Podstawowa różnica między analitykiem danych a naukowcem danych polega na tym, że ci pierwsi generalnie polegają na wiedzy dziedzinowej i ręcznych metodach starej szkoły, aby zrozumieć dane na małą i średnią skalę, podczas gdy ten drugi jest odpowiedzialny za zbieranie, analizowanie i interpretowanie danych na większą skalę korzystanie z szerszych narzędzi, takich jak AI, SQL, oldschoolowe metody manualne itp.,
- Znajomość domeny nie jest koniecznością, ale jej posiadanie jest pomocne.
- Podstawowym zadaniem jest utrzymywanie i wydobywanie wniosków biznesowych z danych, a nie opracowywanie oprogramowania lub produktu.
- Statystyk lub matematyk może zostać dobrym naukowcem zajmującym się danymi.
2. Inżynier ds. uczenia maszynowego: niszowy inżynier oprogramowania, który opracowuje produkt lub usługę w oparciu o sztuczną inteligencję.
- Inżynier ML musi posiadać całą wiedzę specjalistyczną w zakresie tradycyjnej inżynierii oprogramowania, a także wiedzę na temat sztucznej inteligencji, ponieważ ostatecznie zamierza zbudować oprogramowanie z AI w sercu.
- Podstawowym zadaniem nie jest wydobywanie danych, ale opracowanie narzędzia AI, które może wykonać to samo zadanie.
- Programista z dobrą znajomością uczenia maszynowego/głębokiego uczenia oraz inżynierii oprogramowania może zostać dobrym inżynierem uczenia maszynowego.
3. Inżynier operacji uczenia maszynowego: niszowy inżynier oprogramowania, który utrzymuje i automatyzuje potok używany przez system ML.
- Stosunkowo nowa dziedzina inspirowana DevOps. Choć różni się od tradycyjnych ról DevOps.
- W przeciwieństwie do tradycyjnej inżynierii oprogramowania, rozwój dowolnego produktu/oprogramowania/usługi w oparciu o sztuczną inteligencję nie kończy się na zakończeniu budowy oprogramowania. Musi być regularnie aktualizowany o nowe dane, czyli „Drift danych”.
- Podstawowe zadanie obejmuje wszystkie tradycyjne prace DevOps, a także utrzymanie/automatyzację potoku i Data-Drift
- Programista z dobrą znajomością uczenia maszynowego/głębokiego uczenia, inżynierii oprogramowania i technologii chmury może zostać dobrym inżynierem MlOps.
Dla nowego poszukiwacza lub kogoś, kto chce zrobić postęp w swojej karierze, wszystkie te role i oczekiwania muszą być dobrze zrozumiane. Biorąc pod uwagę, że firmy wyraźnie wyróżniają tę rolę, oczekuje się, że dotyczy to również osób fizycznych. Niejasny sposób myślenia jest całkowicie bezużyteczny.
Stos systemu uczenia maszynowego z pełnym stosem
Przejdźmy teraz do zasadniczego punktu. Aby zostać inżynierem uczenia maszynowego z pełnym stosem, konieczne jest zrozumienie koncepcji stosu.

Co to jest pełny stos?
- Podobnie jak w przypadku tradycyjnej inżynierii oprogramowania, tworzenie systemu opartego na sztucznej inteligencji wymaga również zestawu narzędzi. Ten kompletny pakiet można nazwać Full Stack.
- Pełny stos jest zwykle budowany przy użyciu trzech bloków konstrukcyjnych, technologii chmury, technologii zarządzania i technologii sztucznej inteligencji.
- Istnieje wiele elementów do budowy systemu AI w trzech blokach konstrukcyjnych. Lista obejmuje konfigurację, transformację i weryfikację gromadzenia danych, kod ML (szkolenie i walidację), narzędzia do zarządzania zasobami (procesami i maszynami), infrastrukturę obsługi, monitorowanie (można połączyć z dryfem danych). Ta lista nie jest wyczerpująca, ale z pewnością jest ogólna i może być modyfikowana w razie potrzeby.
- Tak więc, aby trzymać się dobrze działającego systemu ML, musimy użyć stosu narzędzi, aby pokryć wszystkie wyżej wymienione komponenty, czasami nawet więcej niż jeden dla jednej części.
Jakie znaczenie ma możliwość zaprojektowania systemu Full Stack?
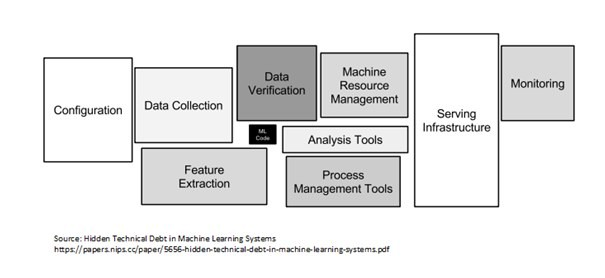
Źródło zdjęcia: Ukryty dług techniczny w dokumencie dotyczącym systemów uczenia maszynowego
- Jak wspomniałem powyżej, dzisiejsze biznesy nie pozwalają na badania/POC bez namacalnej trwałości produktu.
- Nie przesadzę, jeśli powiem, że szkolenie modelowe nie jest najważniejszą częścią, w rzeczywistości postawię go na trzecim, a nawet czwartym miejscu. Osoba, która potrafi zaprojektować i utrzymać stos, staje się kluczowa dla Firmy, ponieważ:
- Jeśli ta sama osoba, która zamierza trenować model, utrzymuje również potok danych (lub wnosi wkład), może zaprojektować go tak, aby odpowiadał dokładnym potrzebom.
- Zrozumienie infrastruktury wdrażania pomoże zbudować bardziej zorientowany na wydajność.
- Zrozumienie serwowania infra pomoże w części dotyczącej szybkości i opóźnień (która jest ogólnie najwyższym wołaniem dla każdego systemu ML).
- Zrozumienie monitorowania pomoże w dryfowaniu danych i długoterminowej wydajności modelu.
- Tak więc osoba, która to wszystko wie, może zwiększyć wydajność całego potoku i zwiększyć wydajność. Ale przede wszystkim oszczędza koszty dla firmy, ponieważ teraz jedna osoba może pełnić wiele ról, co z kolei zwiększa wartość jednostki dla firmy.
Podsumowując, istotne jest nie tylko obsesja na punkcie dokładności modelu, ale także obsesja na punkcie wszystkich kluczowych wskaźników wydajności – szybkości, opóźnień, dokładności, potrzeb w zakresie infrastruktury, żądań obsługi itp.
Przeczytaj także: Pomysły na projekty uczenia maszynowego
Omówienie działania systemu pełnego stosu
Przegląd cyklu życia systemu Ideal ML
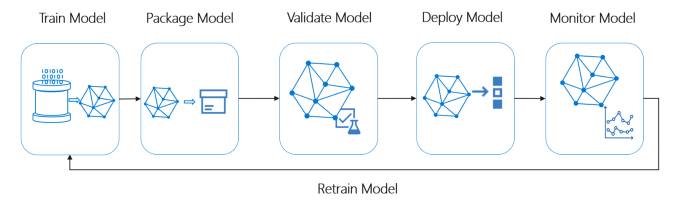
Zdjęcie : Microsoft MLOps
Idealny potok ML musi być zgodny z poniższymi koncepcjami:
- Zarządzanie:
- Wersjonowanie kodu projektu
- Wersjonowanie danych
- Wersjonowanie modelu
- Dokumentacja
- Uniwersalny magazyn artefaktów do przechowywania wersjonowanych zasobów
- Ogólny plan rurociągu:
- Wspólne odkrywanie + polityka eksperymentowania
- Śledzenie eksperymentów (np. niektóre dane, wyniki, skuteczność)
- Wspólna strategia łączenia elementów rurociągu
- Opublikuj wyniki
- Mechanizm do łatwego odtwarzania, odtwarzania, przenoszenia
- Wsparcie dla CI/CD
- Infra wystarczająca do wsparcia rozwoju i produkcji
- Łatwa adaptacja do produkcji i punktów końcowych
- Skalowalna obsługa infra w celu zaspokojenia stale rosnących żądań
Przegląd potoku
- Jednorazowa konfiguracja ustawień ze stosem
- Zestaw danych wersji z DVC.
- Eksperyment ze śledzeniem strat za pomocą MLflow/Wandb.
- Rejestruj wyniki, metryki itp. za pomocą MLflow/Wandb w magazynie Universal Artifact (magazyn obiektów blob platformy Azure jako zaplecze).
- Model dziennika (lub dowolne powiązane zasoby) jako wersjonowane zasoby za pomocą MLflow/Wandb w sklepie Universal Artifact.
- Spakuj poszczególne komponenty za pomocą Dockera.
- Przechowuj składniki pakietu w żądanym repozytorium Docker
- Pakowanie i publikowanie musi odbywać się za pomocą CI/CD.
- Planowanie zautomatyzowanego szkolenia modeli w oparciu o ciągłe monitorowanie dryftu danych.
Uzyskaj certyfikat data science od najlepszych światowych uniwersytetów. Naucz się programów Executive PG, Advanced Certificate Programs lub Masters Programs, aby przyspieszyć swoją karierę.
Wniosek
Aby pozostać aktualnym, zaradnym, kluczowym graczem zespołowym, konieczne jest poszerzenie naszego namiotu wiedzy. Niewątpliwie pomoże w rozwoju w każdym konkurencyjnym środowisku.
Jeśli chcesz dowiedzieć się więcej o uczeniu maszynowym, sprawdź dyplom PG IIIT-B i upGrad w uczeniu maszynowym i sztucznej inteligencji, który jest przeznaczony dla pracujących profesjonalistów i oferuje ponad 450 godzin rygorystycznego szkolenia, ponad 30 studiów przypadków i zadań, IIIT- Status absolwenta B, ponad 5 praktycznych, praktycznych projektów zwieńczenia i pomoc w pracy z najlepszymi firmami.