Jr Data Scientist/Machine Learning'den Data Scientist/Machine Learning Engineer Expert'e
Yayınlanan: 2020-12-07Jr Data Scientist/Makine öğreniminden Full-stack Data Scientist/Makine öğrenimi mühendisine
Veri Bilimi alanındaki mevcut görünüm, üç hatta iki yıl öncesine kıyasla önemli ölçüde değişti. Öğrenme eğrisi asla bitmemelidir. Dolayısıyla gelişmek için, mevcut endüstri beklentilerini karşılamak için doğru beceri setini geliştirmek gerekir.
“Uyumluluk, başa çıkmak için uyum sağlamak ile kazanmaya uyum sağlamak arasındaki güçlü farkla ilgilidir.” - Max McKeown.
Jr Data Scientist / Machine Learning'den Full stack Data Scientist/Machine Learning'e geçmemize yardımcı olabilecek temel unsurlara bakalım.
İçindekiler
Geçmiş Beklenti
Sektörün mevcut beklentisine uyum sağlamak için geçmişteki sorumluluğu anlamak hayati önem taşımaktadır. Özetle, geçmişte bir Veri Bilimcisinin günlük rolü genellikle şunları içeriyordu:
- AI alanı hala nispeten yeniydi (akademisyenlerde olmasa da) ve birçok şirket, yeni başlayanlar uygulamasını ve geçerli kullanım durumunu analiz ediyordu.
- Araştırma birincil odak noktasıydı. Buradaki uyarı, bu araştırmanın birçok kez doğrudan organizasyonun özüyle uyumlu olmadığıydı. Bu yüzden başlangıçta çok fazla güvenilirlik beklenmiyordu.
- Genellikle şirketler, bir Veri Bilimcisi rollerini bir Veri analisti veya Veri mühendisi ile harmanlardı. Yine, AI kurumsal uygulamasının belirsizliği nedeniyle.
- Bireyler de benzer bir ikilem yaşadı. Araştırmalarının veya çalışmalarının çoğu doğrudan doğruya değildi, pratikte bir ürün olarak sunulmaya uygun değildi.
Mevcut Görünüm
Yapay zekanın demokratikleşmesi, şirketlerden ve yeni başlayanlardan dikkate değer gelişmeler gördü. Onu anlamaya çalışalım,
- Endüstri artık bir Veri Bilimcisi, Makine Öğrenimi Mühendisi, Veri Analisti, Veri mühendisi ve hatta MLops mühendisinin rolünü ayırt ediyor.
- İşletmeler, tam olarak hangi kullanım durumundan yararlandıklarını bildikleri için artık vahşi doğada araştırmalara izin vermiyor. Açık bir zihniyet ve bir kişiden benzer ayrık bir yaklaşım da gereklidir.
- Her Araştırma veya POC'nin somut ve kullanılabilir bir ürünü olmalıdır.
Ayrıca Okuyun: Makine Öğreniminde Kariyer
Tüm Rollerin kapsamlı bir şekilde incelenmesi
İşletmelerin yapay zeka alanında üstün olduğu bir alan seçmemiz gerekirse, bu, şüphesiz, kısaca tüm Rol çeşitlerinin açık beklentisidir:
- Veri Bilimcisi: Veri Bilimcisi (genellikle istatistik/matematik geçmişine sahip), verilerden değerli bilgileri çıkarmak için AI dahil çeşitli araçlar kullanan bir kişidir.
- Veri Analisti ve Veri bilimcisi arasındaki temel bir fark, ilki genellikle küçük ila orta ölçekte verileri anlamlandırmak için alan bilgisine ve manuel eski okul yöntemlerine dayanırken, ikincisi daha büyük ölçekte verileri toplamaktan, analiz etmekten ve yorumlamaktan sorumludur. AI, SQL, eski okul manuel yolları vb. gibi daha geniş araçlar kullanarak,
- Alan bilgisi şart değil ama sahip olmak faydalıdır.
- Birincil iş, yazılım veya ürünü geliştirmek değil, verilerden işletmeye katkı sağlayan içgörüleri sürdürmek ve çıkarmaktır.
- Bir İstatistikçi veya Matematikçi iyi bir Veri Bilimcisi olabilir.
2. Makine Öğrenimi Mühendisi: Yapay zekaya dayalı bir ürün veya hizmet geliştiren niş bir yazılım mühendisi.
- Bir makine öğrenimi mühendisinin geleneksel yazılım mühendisliğinin tüm uzmanlığına ve yapay zeka bilgisine sahip olması gerekir çünkü sonunda kalbinde yapay zeka olan bir yazılım geliştirecektir.
- Birincil iş, veri çıkarmak değil, aynı işi yapabilecek bir yapay zeka aracı geliştirmektir.
- Yazılım mühendisliğinin yanı sıra makine öğrenimi/derin öğrenme hakkında iyi bilgiye sahip bir geliştirici, iyi bir Makine öğrenimi mühendisi olabilir.
3. Makine Öğrenimi Operasyon Mühendisi: ML sistemi tarafından kullanılan boru hattını koruyan ve otomatikleştiren bir niş yazılım mühendisi.
- DevOps'tan ilham alan nispeten yeni bir alan. Geleneksel DevOps rollerinden farklı olsa da.
- Geleneksel yazılım mühendisliğinin aksine, yapay zekaya dayalı herhangi bir ürün/yazılım/hizmet için geliştirme, yazılımın oluşturulmasının tamamlanmasıyla bitmez. 'Data-Drift' olan yeni verilerle düzenli olarak güncellenmesi gerekir.
- Birincil iş, tüm geleneksel DevOps çalışmalarının yanı sıra ardışık düzen ve Data-Drift'in bakımını/otomatikleştirilmesini içerir
- Makine öğrenimi/derin öğrenme, yazılım mühendisliği ve bulut teknolojileri konusunda iyi bilgiye sahip bir geliştirici, iyi bir MlOps mühendisi olabilir.
Yeni arayan veya kariyerinde ilerlemeyi hedefleyen biri için tüm bu rollerin ve beklentilerin iyi anlaşılması gerekir. Şirketlerin bu rolü açıkça ayırt ettiği düşünüldüğünde, bireyler için de durumun böyle olması bekleniyor. Belirsiz zihniyet tamamen işe yaramaz.
Tam yığın Makine Öğrenimi sisteminin yığını
Şimdi esas noktaya geçelim. Tam yığın Makine Öğrenimi Mühendisi olmak için yığının arkasındaki kavramı anlamak gerekir.

Tam yığın nedir?
- Geleneksel yazılım mühendisliğine benzer şekilde, AI tabanlı bir sistem geliştirmek de bir takım araçlara ihtiyaç duyar. Bu eksiksiz paket Full Stack olarak adlandırılabilir.
- Tam yığın genellikle üç yapı taşı, Bulut teknolojisi, Yönetişim teknolojisi ve AI teknolojisi kullanılarak oluşturulur.
- Üç yapı taşında bir yapay zeka sistemi oluşturmak için birden fazla bileşen vardır. Liste, Yapılandırma, Veri toplama dönüştürme ve doğrulama, ML kodu (eğitim ve doğrulama), Kaynak (süreç ve makine) yönetim araçları, Hizmet altyapısı, İzleme (Data Drift ile birlikte kullanılabilir) içerir. Bu liste ayrıntılı değildir, ancak kesinlikle geneldir ve gerektiğinde değiştirilebilir.
- Bu nedenle, iyi performans gösteren ML sistemine bağlı kalmak için, yukarıda belirtilen tüm bileşenleri, hatta bazen tek bir parça için birden fazlasını kapsayacak şekilde araç yığınını kullanmamız gerekir.
Tam yığın sistemi tasarlama yeteneğinin önemi nedir?
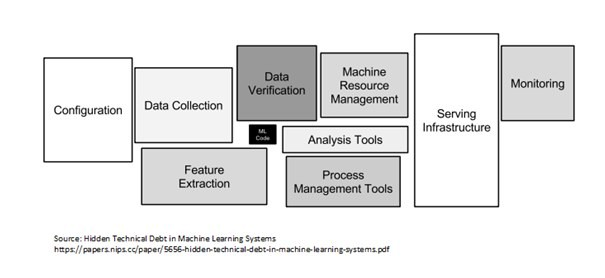
Pic Credit: Makine öğrenimi sistemleri belgesinde gizli teknik borç
- Yukarıda bahsettiğim gibi, günümüz işletmeleri, ürünün somut sürdürülebilirliği olmadan araştırmaya/POC'ye izin vermemektedir.
- Model eğitimi en önemli kısım değil dersem abartmış olmam, hatta üçüncü hatta dördüncü sıraya koyarım. Yığını tasarlayabilen ve bakımını yapabilen kişi Şirket için hayati önem taşır, çünkü,
- Bir modeli eğitecek olan aynı kişi aynı zamanda bir Veri hattını da sürdürüyorsa (veya katkıda bulunuyorsa), o zaman onu tam ihtiyaçları karşılayacak şekilde tasarlayabilir.
- Dağıtım altyapısını anlamak, daha performans odaklı bir yapı oluşturmaya yardımcı olacaktır.
- Sunum altyapısını anlamak, hız ve gecikme (genellikle herhangi bir ML sistemi için en yüksek ağlama noktası olan) kısmında yardımcı olacaktır.
- İzlemeyi anlamak, Veri Kayması ve uzun vadeli model performansında yardımcı olacaktır.
- Böylece, tüm bunları bilen bir kişi, tüm boru hattını daha verimli hale getirebilir ve performansı artırabilir. Ancak her şeyden önce, artık tek bir kişi birden fazla rolü üstlenebildiğinden şirket için maliyet tasarrufu sağlar ve bu da bireyin şirket için değerini artırır.
Özetlemek gerekirse, yalnızca model doğruluğuna takıntılı olmak değil, hız, gecikme, doğruluk, altyapı ihtiyaçları, hizmet istekleri vb.
Ayrıca Okuyun: Makine Öğrenimi Proje Fikirleri
Tam yığın sisteminin nasıl çalıştığına genel bakış
İdeal ML Sisteminin Yaşam Döngüsüne Genel Bakış
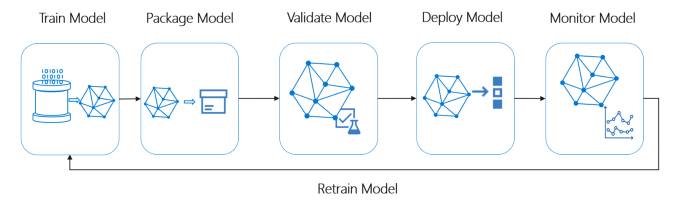
Resim kredisi: Microsoft MLOps
İdeal bir ML Pipeline aşağıdaki kavramları izlemelidir:
- Yönetim:
- Proje kodunun versiyonlanması
- Verilerin Versiyonu
- Modelin Versiyonu
- belgeler
- Sürümlü varlıkları depolamak için evrensel yapıt deposu
- Genel boru hattı planı:
- Ortak keşif + deneme politikası
- Deneme izleme (bazı metrikler, sonuçlar, performans gibi)
- Boru hattının bileşenlerini birbirine bağlamak için ortak bir strateji
- Sonuçları yayınla
- Kolayca çoğaltma, yeniden oluşturma, bağlantı noktası mekanizması
- CI/CD desteği
- Geliştirmeyi ve üretimi desteklemek için yeterli altyapı
- Üretim ve uç noktalar için kolay uyarlama
- Sürekli artan talepleri karşılamak için Ölçeklenebilir Sunum altyapısı
Boru Hattına Genel Bakış
- Yığınla bir kerelik ayar yapılandırması
- DVC ile Sürüm Veri Kümesi.
- MLflow/Wandb ile katman izleme deneyi.
- Universal Artifact deposunda (arka uç olarak Azure blob depolama) MLflow/Wandb ile sonuçları, ölçümleri vb. günlüğe kaydedin.
- Modeli (veya ilgili varlıkları) Universal Artifact mağazasında MLflow/Wandb ile sürümlü varlıklar olarak kaydedin.
- Docker ile bileşenleri tek tek paketleyin.
- Paket bileşenlerini istenen Docker deposuyla saklayın
- Paketleme ve yayınlama, CI/CD kullanılarak yapılmalıdır.
- Data Drift için sürekli izlemeye dayalı otomatik model eğitimi zamanlama.
Dünyanın en iyi Üniversitelerinden veri bilimi sertifikası alın . Kariyerinizi hızlandırmak için Yönetici PG Programları, İleri Düzey Sertifika Programları veya Yüksek Lisans Programları öğrenin.
Çözüm
İlgili, becerikli, kilit takım oyuncusu olarak kalabilmek için bilgi çadırımızı artırmamız gerekiyor. Şüphesiz herhangi bir rekabet ortamında ilerlemeye yardımcı olacaktır.
Makine öğrenimi hakkında daha fazla bilgi edinmek istiyorsanız, çalışan profesyoneller için tasarlanmış ve 450+ saat zorlu eğitim, 30'dan fazla vaka çalışması ve ödev, IIIT- sunan IIIT-B & upGrad'ın Makine Öğrenimi ve Yapay Zeka PG Diplomasına göz atın. B Mezun statüsü, 5+ pratik uygulamalı bitirme projesi ve en iyi firmalarla iş yardımı.