주니어 데이터 과학자/머신러닝에서 데이터 과학자/머신러닝 엔지니어 전문가로
게시 됨: 2020-12-07주니어 데이터 과학자/머신러닝에서 풀스택 데이터 과학자/머신러닝 엔지니어로
데이터 과학 분야의 현재 전망은 3년, 심지어 2년 전과 비교할 때 크게 바뀌었습니다. 학습 곡선은 결코 끝나지 않아야 합니다. 따라서 번창하려면 현재 업계의 기대치를 충족할 수 있는 올바른 기술을 개발해야 합니다.
"적응성은 대처하기 위해 적응하는 것과 승리하기 위해 적응하는 것 사이의 강력한 차이에 관한 것입니다." — 맥스 맥키온.
주니어 데이터 과학자/머신 러닝에서 풀 스택 데이터 과학자/머신 러닝으로 전환하는 데 도움이 될 수 있는 핵심 요소를 살펴보겠습니다.
목차
과거의 기대
업계의 현재 기대에 적응하기 위해 과거의 책임을 이해하는 것이 중요합니다. 간단히 말해서 과거 데이터 과학자의 일상적인 역할은 일반적으로 다음과 같습니다.
- AI 공간은 여전히 상대적으로 새롭고(학계에서는 아니지만) 많은 기업, 신생 기업이 해당 응용 프로그램과 유효한 사용 사례를 분석하고 있었습니다.
- 연구는 주요 초점이었습니다. 여기서 주의할 점은 이 연구가 여러 번 조직의 핵심과 직접적으로 일치하지 않는다는 것이었습니다. 그래서 처음에는 그렇게 많은 신뢰를 기대하지 않았습니다.
- 일반적으로 회사는 데이터 과학자의 역할을 데이터 분석가 또는 데이터 엔지니어와 혼합했습니다. 다시 말하지만, AI 엔터프라이즈 애플리케이션의 모호함 때문입니다.
- 개인에게도 비슷한 딜레마가 있었다. 그들의 연구나 작업의 대부분은 직접적인 관련이 없었고 실제로 제품으로 제공될 수 없었습니다.
현재 전망
AI의 민주화는 기업과 신생 기업에서 놀라운 발전을 보였습니다. 그것을 이해하려고 노력합시다.
- 업계는 이제 데이터 과학자, 기계 학습 엔지니어, 데이터 분석가, 데이터 엔지니어, 심지어 MLops 엔지니어의 역할을 구별합니다.
- 기업은 정확히 어떤 사용 사례를 활용하고 있는지 알고 있기 때문에 더 이상 야생에서의 연구를 허용하지 않습니다. 명확한 사고 방식과 개인의 유사한 개별 접근 방식도 필요합니다.
- 모든 연구 또는 POC에는 유형적이고 제공 가능한 제품이 있어야 합니다.
더 읽어보기: 기계 학습 경력
모든 역할의 철저한 분석
기업이 AI 분야에서 두각을 나타낸 한 분야를 선택해야 한다면, 모든 역할의 다양성에 대한 분명한 기대일 것입니다. 간단히 말해서:
- 데이터 과학자: 데이터 과학자는 (일반적으로 통계/수학 배경에서) AI를 포함한 다양한 수단을 사용하여 데이터에서 귀중한 정보를 추출하는 사람입니다.
- 데이터 분석가와 데이터 과학자의 근본적인 차이점은 전자는 일반적으로 중소 규모의 데이터를 이해하기 위해 도메인 지식과 수동 구식 방법에 의존하는 반면 후자는 더 큰 규모의 데이터 수집, 분석 및 해석을 담당한다는 것입니다. AI, SQL, 구식 수동 방식 등과 같은 광범위한 도구 사용,
- 도메인 지식은 필수는 아니지만 있으면 도움이 됩니다.
- 주요 업무는 소프트웨어나 제품을 개발하는 것이 아니라 데이터에서 통찰력을 제공하는 비즈니스를 유지하고 추출하는 것입니다.
- 통계학자나 수학자도 훌륭한 데이터 과학자가 될 수 있습니다.
2. 머신러닝 엔지니어: AI를 기반으로 제품이나 서비스를 개발하는 틈새 소프트웨어 엔지니어.
- ML 엔지니어는 결국 AI를 중심으로 소프트웨어를 구축하게 되므로 AI에 대한 지식과 함께 기존 소프트웨어 엔지니어링의 모든 전문 지식을 갖추어야 합니다.
- 기본 업무는 데이터를 추출하는 것이 아니라 동일한 작업을 수행할 수 있는 AI 도구를 개발하는 것입니다.
- 기계 학습/딥 러닝 및 소프트웨어 엔지니어링에 대한 지식이 풍부한 개발자는 우수한 기계 학습 엔지니어가 될 수 있습니다.
3. 기계 학습 운영 엔지니어: ML 시스템에서 사용하는 파이프라인을 유지 관리하고 자동화하는 틈새 소프트웨어 엔지니어입니다.
- DevOps에서 영감을 받은 비교적 새로운 분야. 기존 DevOps 역할과는 다르지만.
- 기존의 소프트웨어 엔지니어링과 달리 AI를 기반으로 하는 모든 제품/소프트웨어/서비스 개발은 소프트웨어 구축 완료에서 그치지 않습니다. 'Data-Drift'라는 새로운 데이터로 정기적으로 업데이트해야 합니다.
- 기본 작업에는 모든 기존 DevOps 작업과 파이프라인 및 Data-Drift 유지/자동화가 포함됩니다.
- 머신 러닝/딥 러닝, 소프트웨어 엔지니어링 및 클라우드 기술에 대한 지식이 풍부한 개발자는 훌륭한 MlOps 엔지니어가 될 수 있습니다.
새로운 구직자나 경력 향상을 목표로 하는 사람은 이러한 모든 역할과 기대치를 잘 이해해야 합니다. 기업이 이 역할을 명확히 구분하고 있다는 점을 감안할 때 개인도 마찬가지일 것으로 예상된다. 막연한 생각은 전혀 쓸모가 없습니다.
전체 스택 머신 러닝 시스템의 스택
이제 본론으로 넘어가겠습니다. 풀스택 머신 러닝 엔지니어가 되려면 스택 이면의 개념을 이해하는 것이 필요합니다.

풀스택이란?
- 기존 소프트웨어 엔지니어링과 마찬가지로 AI 기반 시스템을 개발하려면 도구 모음도 필요합니다. 이 완전한 제품군을 전체 스택이라고 할 수 있습니다.
- 전체 스택은 일반적으로 클라우드 기술, 거버넌스 기술 및 AI 기술의 세 가지 빌딩 블록을 사용하여 구축됩니다.
- 세 가지 빌딩 블록에 걸쳐 AI 시스템을 구축하기 위한 여러 구성 요소가 있습니다. 목록에는 구성, 데이터 수집 변환 및 검증, ML 코드(교육 및 검증), 리소스(프로세스 및 기계) 관리 도구, 인프라 제공, 모니터링(Data Drift와 함께 사용할 수 있음)이 포함됩니다. 이 목록이 완전하지는 않지만 확실히 일반적이며 필요에 따라 수정할 수 있습니다.
- 따라서 성능이 좋은 ML 시스템을 고수하려면 위에서 언급한 모든 구성 요소를 포함하는 도구 스택을 사용해야 하며 때로는 단일 부품에 대해 둘 이상의 구성 요소를 포함해야 합니다.
풀 스택 시스템을 설계하는 능력의 중요성은 무엇입니까?
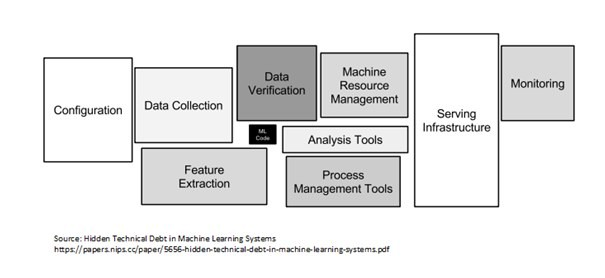
사진 제공: 기계 학습 시스템 문서에 숨겨진 기술적 부채
- 위에서 언급했듯이 오늘날의 비즈니스는 제품의 가시적인 지속 가능성 없이 연구/POC를 허용하지 않습니다.
- 모델 교육이 가장 중요한 부분이 아니라고 해도 과언이 아니라 3위, 4위를 차지할 것입니다. 스택을 설계하고 유지 관리할 수 있는 사람은 회사에 매우 중요합니다.
- 모델을 교육할 동일한 사람이 데이터 파이프라인을 유지 관리(또는 기여)하는 경우 정확한 요구 사항을 충족하도록 설계할 수 있습니다.
- 배포 인프라를 이해하면 보다 성능 중심적으로 구축하는 데 도움이 됩니다.
- Serving 인프라를 이해하면 속도 및 대기 시간 부분(일반적으로 모든 ML 시스템에서 가장 높은 요구 사항임)에 도움이 됩니다.
- 모니터링을 이해하면 데이터 드리프트 및 장기 모델 성능에 도움이 됩니다.
- 따라서 이 모든 것을 알고 있는 개인은 전체 파이프라인을 보다 효율적으로 만들고 성능을 높일 수 있습니다. 그러나 무엇보다 이제 한 사람이 여러 역할을 수행할 수 있어 회사의 비용을 절감할 수 있으며, 결과적으로 회사에 대한 개인의 가치를 높일 수 있습니다.
요약하자면, 모델 정확도에만 집착하는 것이 아니라 속도, 대기 시간, 정확도, 인프라 요구 사항, 서비스 요청 등 모든 주요 성능 지표에 집착하는 것이 중요합니다.
더 읽어보기: 기계 학습 프로젝트 아이디어
전체 스택 시스템 작동 방식 개요
이상적인 ML 시스템의 수명 주기 개요
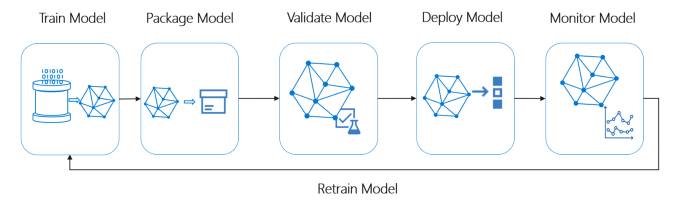
사진 제공: Microsoft MLOps
이상적인 ML 파이프라인은 다음 개념을 따라야 합니다.
- 통치:
- 프로젝트 코드 버전 관리
- 데이터 버전 관리
- 모델 버전 관리
- 선적 서류 비치
- 버전이 지정된 자산을 저장하는 범용 아티팩트 저장소
- 일반 파이프라인 청사진:
- 공통 발견 + 실험 정책
- 실험 추적(일부 측정항목, 결과, 성능 등)
- 파이프라인의 구성 요소를 상호 연결하는 공통 전략
- 결과 게시
- 쉽게 재현, 재현, 이식하는 메커니즘
- CI/CD 지원
- 개발 및 생산을 지원하기에 충분한 인프라
- 프로덕션 및 엔드포인트에 대한 손쉬운 조정
- 계속 증가하는 요청을 수용하기 위한 확장 가능한 서빙 인프라
파이프라인 개요
- 스택을 사용한 일회성 설정 구성
- DVC가 있는 버전 데이터 세트.
- MLflow/Wandb를 사용한 Strat 추적 실험.
- Universal Artifact 저장소(백엔드로 Azure Blob 저장소)에서 MLflow/Wandb를 사용하여 결과, 메트릭 등을 기록합니다.
- Universal Artifact 저장소에서 MLflow/Wandb를 사용하여 버전이 지정된 자산으로 모델(또는 모든 관련 자산)을 기록합니다.
- Docker를 사용하여 개별 구성 요소를 패키징합니다.
- 원하는 Docker 리포지토리로 패키지 구성 요소 저장
- CI/CD를 사용하여 패키징 및 게시해야 합니다.
- Data Drift에 대한 지속적인 모니터링을 기반으로 자동화된 모델 교육을 예약합니다.
세계 최고의 대학에서 데이터 과학 인증 을 받으십시오 . 이그 제 큐 티브 PG 프로그램, 고급 인증 프로그램 또는 석사 프로그램을 통해 경력을 빠르게 추적하십시오.
결론
관련성이 있고 수완이 있으며 핵심 팀 플레이어로 남아 있으려면 지식 텐트를 늘려야 합니다. 그것은 의심할 여지 없이 경쟁 환경에서 발전하는 데 도움이 될 것입니다.
기계 학습에 대해 자세히 알아보려면 IIIT-B 및 upGrad의 기계 학습 및 AI PG 디플로마를 확인하세요. 이 PG 디플로마는 일하는 전문가를 위해 설계되었으며 450시간 이상의 엄격한 교육, 30개 이상의 사례 연구 및 과제, IIIT- B 동문 자격, 5개 이상의 실용적인 실습 캡스톤 프로젝트 및 최고의 기업과의 취업 지원.