От младшего специалиста по данным/машинному обучению до специалиста по данным/инженера по машинному обучению
Опубликовано: 2020-12-07От младшего специалиста по данным/машинному обучению до специалиста по анализу данных полного цикла/инженера по машинному обучению
Нынешнее мировоззрение в области науки о данных значительно изменилось по сравнению с тем, что было три или даже два года назад. Кривая обучения никогда не должна заканчиваться. Таким образом, чтобы преуспеть, нужно развивать правильный набор навыков, чтобы соответствовать текущим ожиданиям отрасли.
«Адаптивность — это огромная разница между адаптацией, чтобы справиться с ситуацией, и адаптацией, чтобы победить». — Макс МакКаун.
Давайте рассмотрим ключевые элементы, которые могут помочь нам перейти от Jr Data Scientist/Machine Learning к Full Stack Data Scientist/Machine Learning.
Оглавление
Прошлое ожидание
Очень важно понимать прошлую ответственность, чтобы адаптироваться к текущим ожиданиям отрасли. Итак, вкратце, повседневная роль Data Scientist в прошлом обычно включала:
- Область ИИ все еще была относительно новой (хотя и не в академических кругах), и многие компании и стартапы анализировали ее применение и варианты использования.
- Исследования были в центре внимания. Предупреждение здесь заключалось в том, что это исследование много раз не соответствовало сути организации. Так что изначально не ожидалось такого большого доверия.
- Обычно компании совмещали роли Data Scientist с Data Analytics или Data Engineer. Опять же, из-за неясности корпоративного применения ИИ.
- У людей также была своего рода подобная дилемма. Многие их исследования или работы не были напрямую связаны, практически не годились для использования в качестве продукта.
Текущая перспектива
Демократизация ИИ привела к замечательным разработкам компаний и стартапов. Попробуем понять это,
- В настоящее время в отрасли различают роли специалиста по данным, инженера по машинному обучению, аналитика данных, инженера по данным и даже инженера по MLops.
- Предприятия больше не разрешают исследования в дикой природе, поскольку они точно знают, к какому варианту использования они подключаются. Также требуется четкое мышление и аналогичный дискретный подход от человека.
- Каждое исследование или POC должно иметь материальный и полезный продукт.
Читайте также: Карьера в машинном обучении
Тщательный анализ всех ролей
Если нам нужно выбрать одну область, в которой предприятия преуспели в области ИИ, это, несомненно, четкие ожидания от всех разновидностей ролей, которые в двух словах:
- Data Scientist: Data Scientist — это человек, который (обычно из статистики/математики) использует различные средства, включая ИИ, для извлечения ценной информации из данных.
- Фундаментальное различие между аналитиком данных и специалистом по данным заключается в том, что первые обычно полагаются на знание предметной области и ручные методы старой школы для понимания данных в малом и среднем масштабе, тогда как последний отвечает за сбор, анализ и интерпретацию данных в более крупном масштабе. использование более широких средств таких инструментов, как AI, SQL, ручные способы старой школы и т. д.,
- Знание домена не обязательно, но полезно.
- Основная задача состоит в том, чтобы поддерживать и извлекать бизнес-информацию из данных, а не разрабатывать программное обеспечение или продукт.
- Статистик или математик может стать хорошим специалистом по данным.
2. Инженер по машинному обучению: нишевый инженер-программист, который разрабатывает продукт или услугу на основе ИИ.
- Инженер машинного обучения должен обладать всеми знаниями в области традиционной разработки программного обеспечения, а также знаниями в области искусственного интеллекта, потому что в конечном итоге он/она собирается создавать программное обеспечение, в основе которого лежит искусственный интеллект.
- Основная задача заключается не в извлечении данных, а в разработке инструмента искусственного интеллекта, который может выполнять ту же работу.
- Разработчик с хорошими знаниями в области машинного обучения/глубокого обучения, а также разработки программного обеспечения может стать хорошим инженером по машинному обучению.
3. Инженер по эксплуатации машинного обучения: нишевый инженер-программист, который поддерживает и автоматизирует конвейер, используемый системой ML.
- Относительно новая область, вдохновленная DevOps. Хотя и отличается от традиционных ролей DevOps.
- В отличие от традиционной разработки программного обеспечения, разработка любого продукта/программного обеспечения/услуги на основе ИИ не останавливается на завершении создания программного обеспечения. Его необходимо регулярно обновлять новыми данными, что называется «Дрейф данных».
- Основная работа включает в себя всю традиционную работу DevOps, а также поддержку/автоматизацию конвейера и Data-Drift.
- Разработчик с хорошими знаниями в области машинного обучения/глубокого обучения, разработки программного обеспечения и облачных технологий может стать хорошим инженером по многооперационным операциям.
Для нового ищущего или для того, кто стремится продвинуться в своей карьере, все эти роли и ожидания должны быть хорошо поняты. Учитывая, что компании четко разграничивают эту роль, ожидается, что то же самое будет и с физическими лицами. Расплывчатое мышление совершенно бесполезно.
Стек системы машинного обучения полного стека
Теперь перейдем к существенному моменту. Чтобы стать инженером по машинному обучению с полным стеком, необходимо понимать концепцию стека.

Что такое полный стек?
- Подобно традиционной разработке программного обеспечения, разработка системы на основе ИИ также требует набора инструментов. Этот полный пакет можно назвать полным стеком.
- Полный стек обычно строится с использованием трех строительных блоков: облачных технологий, технологий управления и технологий искусственного интеллекта.
- Существует несколько компонентов для построения системы ИИ из трех строительных блоков. В список входят конфигурация, преобразование и проверка сбора данных, код машинного обучения (обучение и проверка), инструменты управления ресурсами (процессами и машинами), инфраструктура обслуживания, мониторинг (можно объединить с Data Drift). Этот список не является исчерпывающим, но он, безусловно, является общим и может быть изменен по мере необходимости.
- Таким образом, чтобы придерживаться хорошо работающей системы машинного обучения, мы должны использовать стек инструментов для покрытия всех вышеупомянутых компонентов, иногда даже более одного для одной детали.
В чем важность способности проектировать систему полного стека?
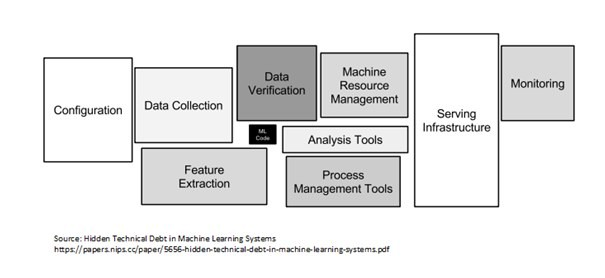
Pic Credit: Скрытый технический долг в документе о системах машинного обучения
- Как я упоминал выше, современный бизнес не позволяет проводить исследования/POC без ощутимой устойчивости продукта.
- Я не преувеличу, если скажу, что модельный тренинг не самая важная часть, на самом деле я поставлю его на третье или даже четвертое место. Человек, который может спроектировать и поддерживать стек, становится жизненно важным для компании, потому что,
- Если тот же человек, который собирается обучать модель, также поддерживает конвейер данных (или вносит свой вклад), то он / она может спроектировать его для удовлетворения конкретных потребностей.
- Понимание инфраструктуры развертывания поможет повысить производительность.
- Понимание инфраструктуры обслуживания поможет в части скорости и задержки (что, как правило, является самым большим криком для любой системы машинного обучения).
- Понимание мониторинга поможет с дрейфом данных и производительностью модели в долгосрочной перспективе.
- Таким образом, человек, знающий все это, может сделать весь конвейер более эффективным и повысить производительность. Но, прежде всего, это экономит затраты для компании, поскольку теперь один человек может выполнять несколько ролей, что, в свою очередь, увеличивает ценность человека для компании.
Подводя итог, важно не просто зацикливаться на точности модели, но и о всех ключевых показателях производительности — скорости, задержке, точности, потребностях в инфраструктуре, обслуживании запросов и т. д.
Читайте также: Идеи проекта машинного обучения
Обзор того, как работает система полного стека
Обзор жизненного цикла Ideal ML System
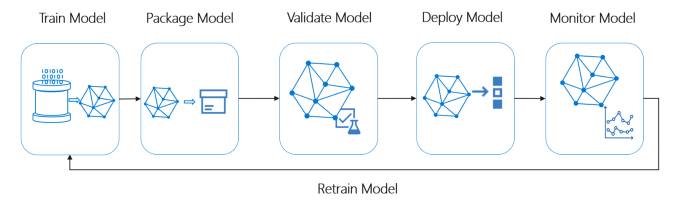
Фото предоставлено : Microsoft MLOps.
Идеальный конвейер машинного обучения должен следовать следующим принципам:
- Управление:
- Версии кода проекта
- Версии данных
- Версии модели
- Документация
- Универсальное хранилище артефактов для хранения версионированных ресурсов
- Общий план трубопровода:
- Общая политика обнаружения и экспериментов
- Отслеживание экспериментов (например, некоторые показатели, результаты, производительность)
- Общая стратегия соединения компонентов конвейера
- Опубликовать результаты
- Механизм для простого воспроизведения, воссоздания, переноса
- Поддержка CI/CD
- Достаточная инфраструктура для поддержки разработки, а также производства
- Простая адаптация для производства и конечных точек
- Масштабируемая инфраструктура обслуживания для удовлетворения постоянно растущих запросов
Обзор конвейера
- Одноразовая конфигурация настроек со стеком
- Набор данных версии с DVC.
- Эксперимент по отслеживанию стратегии с MLflow/Wandb.
- Регистрируйте результаты, метрики и т. д. с помощью MLflow/Wandb в универсальном хранилище артефактов (хранилище BLOB-объектов Azure в качестве серверной части).
- Модель журнала (или любые связанные активы) как версионные активы с MLflow/Wandb в универсальном хранилище артефактов.
- Упакуйте отдельные компоненты с помощью Docker.
- Храните компоненты пакета в нужном репозитории Docker.
- Упаковка и публикация должны выполняться с использованием CI/CD.
- Планирование автоматизированного обучения модели на основе непрерывного мониторинга Data Drift.
Получите сертификат по науке о данных от лучших университетов мира. Изучите программы Executive PG, Advanced Certificate Programs или Master Programs, чтобы ускорить свою карьеру.
Заключение
Чтобы оставаться актуальным, находчивым, ключевым игроком в команде, необходимо увеличивать нашу палатку знаний. Это, несомненно, поможет прогрессировать в любой конкурентной среде.
Если вам интересно узнать больше о машинном обучении, ознакомьтесь с дипломом PG IIIT-B и upGrad в области машинного обучения и искусственного интеллекта, который предназначен для работающих профессионалов и предлагает более 450 часов тщательного обучения, более 30 тематических исследований и заданий, IIIT- Статус B Alumni, более 5 практических практических проектов и помощь в трудоустройстве в ведущих фирмах.