
Объяснение алгоритма быстрой сортировки [с примером]
Опубликовано: 2020-12-15Быстрая сортировка основана на концепции алгоритма « разделяй и властвуй », которая также используется в сортировке слиянием. Разница в том, что при быстрой сортировке самая важная или значительная работа выполняется при разбиении (или делении) массива на подмассивы, а при сортировке слиянием вся основная работа выполняется при объединении подмассивов. Для быстрой сортировки шаг объединения незначителен.
Быстрая сортировка также называется сортировкой с обменом разделами . Этот алгоритм делит заданный массив чисел на три основные части:
- Элементы меньше, чем опорный элемент
- Поворотный элемент
- Элементы больше, чем опорный элемент
Элемент Pivot можно выбрать из заданных чисел разными способами:
- Выбор первого элемента
- Выбор последнего элемента (показан пример)
- Выбор любого случайного элемента
- Выбор медианы
Например: в массиве {51, 36, 62, 13, 16, 7, 5, 24} мы берем 24 в качестве точки опоры (последний элемент). Таким образом, после первого прохода список будет изменен следующим образом.
{5 7 16 13 24 62 36 51}
Следовательно, после первого прохода массив сортируется таким образом, что все элементы, меньшие выбранной опорной точки, находятся на его левой стороне, а все большие элементы — на правой. Наконец, точка поворота находится в той позиции, в которой она должна находиться в отсортированной версии массива. Теперь подмассивы {5 7 16 13} и {62 36 51} рассматриваются как два отдельных массива, и к ним будет применяться одна и та же рекурсивная логика, и мы будем продолжать делать это до тех пор, пока весь массив не будет отсортирован.

Читайте также: Сортировка кучей в структуре данных
Оглавление
Как это работает?
Вот шаги, выполняемые в алгоритме быстрой сортировки:
- Мы выбираем наш стержень в качестве последнего элемента и начинаем разбивать (или делить) массив в первый раз.
- В этом алгоритме разбиения массив разбивается на 2 подмассива таким образом, что все элементы, меньшие, чем опорная точка, будут находиться на левой стороне опорной точки, а все элементы, превышающие опорную, будут находиться на правой стороне от нее.
- И поворотный элемент будет в своей конечной отсортированной позиции.
- Элементы в левом и правом подмассивах не нужно сортировать.
- Затем мы рекурсивно выбираем левый и правый подмассивы и выполняем разбиение каждого из них, выбирая точку опоры в подмассивах, и шаги повторяются для одного и того же.
Ниже показано, как алгоритм работает в коде C++ с использованием примера массива.
void QuickSort (int a [], int low, int high)
{
если (высокий<низкий)
вернуть;
int p = раздел (а, низкий, высокий);
Быстрая сортировка (а, низкий, p-1);
Быстрая сортировка (а, р+1, высокий);
}
раздел int (int a [], int low, int high)
{
INT Pivot=a[высокий];
интервал я = низкий;
for(int j=низкий; j<высокий; j++)
{
если(a[j]<=поворот)
{
своп(&a[j],&a[i]);
я++;
}
}
своп(&a[i],&a[высокий]);
вернуть я;
}
основной ()
{
интервал обр[]={6,1,5,2,4,3};
Быстрая сортировка (обр, 0,5);
cout<<"Отсортированный массив: ";

для (целое я = 0; я <6; я ++)
cout<<arr[i]<<” “;
вернуть 0;
}
Ниже показано графическое представление того, как быстрая сортировка будет сортировать данный массив.
Предположим, что исходный входной массив:
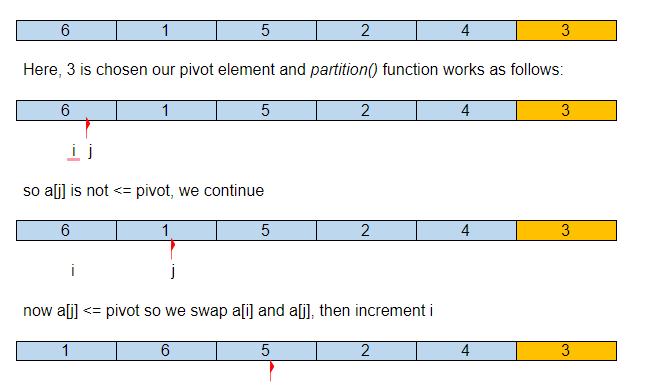

Таким образом, после нашего первого раздела опорный элемент находится на правильном месте в отсортированном массиве, со всеми его меньшими элементами слева и большими справа.
Теперь QuickSort() будет вызываться рекурсивно для подмассивов {1,2} и {6,4,5} и продолжаться до тех пор, пока массив не будет отсортирован.
Обязательно к прочтению: типы алгоритмов ИИ, которые вы должны знать
Анализ сложности
Ω Временная сложность в наилучшем случае: Ω Θ Средняя временная сложность: Θ O(n Временная сложность в наихудшем случае: O(n Если разбиение приводит к почти равным подмассивам, то время выполнения будет оптимальным, а временная сложность равна O(n*log n).
В худшем случае это случается с массивами, в которых элементы уже отсортированы, а сводная точка выбирается последним элементом. Здесь разбиение дает несбалансированные подмассивы, в которых все элементы уже меньше, чем точка опоры и, следовательно, находятся на ее левой стороне, а элементы на правой стороне отсутствуют.
O(n*log n) O (n * log n)
Заключение
Быстрая сортировка — это алгоритм, основанный на сравнении , и он нестабилен . Небольшая оптимизация, которую можно выполнить, заключается в вызове рекурсивной функции QuickSort() сначала для меньшего подмассива, а затем для большего подмассива.
В целом, быстрая сортировка — это высокоэффективный метод сортировки, который может обеспечить более высокую производительность, чем сортировка слиянием, в случае небольших массивов.
Если вы хотите узнать больше, ознакомьтесь с дипломом PG upGrad & IIIT-B по программе машинного обучения и искусственного интеллекта.
Каковы недостатки использования алгоритма быстрой сортировки?
В общем, алгоритм быстрой сортировки является наиболее эффективным и широко используемым методом сортировки списка любого размера, хотя и имеет некоторые недостатки. Это хрупкий метод, из которого следует, что если не устранить небольшой недостаток в реализации, то пострадают результаты. Реализация сложна, особенно если рекурсия недоступна. Одно небольшое ограничение алгоритма быстрой сортировки заключается в том, что его производительность в наихудшем случае сравнима с типичной производительностью пузырьковой сортировки, сортировки вставкой или выбора.
Для чего используется алгоритм сортировки ведра?
Алгоритм сортировки ведра — это метод сортировки, который используется для помещения разных элементов в разные группы. Он назван так потому, что различные подгруппы называются ведрами. Из-за абсолютно равномерного распределения элементов он асимптотически быстр. Однако, если у нас есть огромный массив, это неэффективно, поскольку увеличивает стоимость всего процесса, делая его менее доступным.
Какой из них лучше использовать — алгоритм быстрой сортировки или алгоритм сортировки слиянием?
Для небольших наборов данных быстрая сортировка работает быстрее, чем другие алгоритмы сортировки, такие как сортировка выбором, но сортировка слиянием обеспечивает постоянную производительность независимо от размера данных. С другой стороны, быстрая сортировка менее эффективна, чем сортировка слиянием, при работе с большими массивами. Сортировка слиянием занимает больше места, но быстрая сортировка занимает совсем немного. Быстрая сортировка, в частности, имеет сильную локальную кэш-память, что делает ее более быстрой, чем сортировка слиянием во многих ситуациях, например, в среде виртуальной памяти. В результате быстрая сортировка превосходит алгоритм сортировки слиянием.