
Análise de expressão na estrutura de dados: tipos de notação, associatividade e precedência
Publicados: 2020-10-07A análise sintática é o processo de análise de uma sequência de símbolos, expressos em linguagens naturais ou de computador que irão conferir gramática formal . Expression Parsing in Data Structure significa a avaliação de expressões aritméticas e lógicas. Primeiro, vamos ver como uma expressão aritmética é escrita:
- 9+9
- Cb
Uma expressão pode ser escrita com constantes, variáveis e símbolos que podem atuar como um operador ou parênteses. Toda essa expressão precisa seguir um conjunto específico de regras. De acordo com essa regra, a análise da expressão é feita com base na gramática.
Uma expressão aritmética é expressa na forma de notação . Agora, existem três maneiras de escrever uma expressão em Aritmética:
- Notação Infixa
- Notação de prefixo (polonês)
- Notação pós-fixada (polonês reverso)
No entanto, quando a expressão é escrita, a saída da expressão desejada permanece a mesma. Antes de começar com os tipos de Notação, vamos ver o que são Associatividade e Precedência na Análise de Expressão na Estrutura de Dados.
Se você é iniciante e está interessado em aprender mais sobre ciência de dados, confira nossos cursos de ciência de dados das melhores universidades.
Leia: Gráficos na Estrutura de Dados
Índice
Associatividade
Antes de começar, você precisa saber o que é propriedade de Associatividade; ele fornece as regras para reorganizar os parênteses em uma expressão para fornecer uma prova válida. Isso significa que um rearranjo do colchete precisa fornecer o mesmo valor que a equação pai. Ele fornece uma regra válida para substituir os operadores.
Em uma expressão contendo dois ou mais operadores, a operação realizada não importa, a menos que a sequência de operandos não seja trocada. Se a expressão for escrita entre colchetes e entre colchetes, alterar a posição não altera o valor.
Como nas línguas indo-européias as expressões são lidas da esquerda para a direita, a maioria dos operadores infixos são associativos à esquerda; operadores são avaliados na mesma precedência. O aumento do poder é a regra usada para considerar os operadores infixos. Os operadores de prefixo são geralmente associativos à direita e os operadores pósfixos são associativos à esquerda.
Em algumas linguagens, operadores e operandos recebem o mesmo valor, onde a Associatividade não é considerada tornando essa sequência de linguagem explícita. Enquanto em algumas linguagens os operadores são não associativos, isso torna necessário o uso de expressões complexas para o uso de colchetes, o que aumenta a complexidade para os programadores.
Precedência na estrutura de dados
Ordem de precedência significa que ordem os operadores precisam seguir em uma declaração de expressões. Isso é comumente usado ao trabalhar com Infix Notation.
Na situação do operando <operador> <operando> <operador> entre os dois operadores, a preferência para alocar o operador é bastante complicada. Assim, as regras de Precedência do operador são seguidas para o cálculo. Por exemplo, aqui, a multiplicação tem maior precedência e, posteriormente, a operação de adição é executada.
- A regra mais comum, mas não tão óbvia, é que a operação de multiplicação e divisão deve ser realizada antes da adição e subtração. Normalmente, eles são coletados da mesma maneira, portanto, a mesma importância é fornecida para todos os operadores.
- Considerando esta operação em um formato lógico, a variação é vista em “e” e “ou”. Muitos idiomas fornecem a mesma importância, onde a operação “ou” recebe maior precedência. Alguns idiomas consideram a multiplicação ou “&”, “&” adição “ou” a Precedência igual, onde a maioria dos idiomas fornece operações aritméticas com a Precedência mais alta.
- A sobrecarga é causada devido à falta de alocação adequada de precedência. Muitas linguagens fornecem negação (verdadeiro/falso) com Precedência mais alta do que expressões de álgebra vetorial, enquanto algumas fornecem Precedência igual.
Leia também: Ideias de projetos de estrutura de dados
Tipos de notação
Agora vamos aprender como a posição do operador decide o tipo de notação.
1. Notação Infixa
Na Notação Infixa, os operadores são usados entre os operandos. Ao ler uma expressão, a Notação Infixa é bastante fácil para humanos. Mas consome bastante tempo e espaço para processar um argumento infixo quando se trata de um algoritmo de computador. Ex: p + q
<operandos> <operadores> <operandos>
Infix Notation precisa de informações adicionais para realizar a avaliação; as regras são construídas na linguagem de expressão usando o operador Associativity , Por exemplo: p * ( q + r ) / s
- As regras de associatividade sugerem que a expressão precisa ser realizada da esquerda para a direita, de modo que a multiplicação por p seja feita antes da divisão de q.
- Da mesma forma, as regras de Precedência sugerem que a operação de multiplicação e divisão seja realizada antes da operação de adição e subtração.
2. Notação de prefixo
Aqui o operador é escrito primeiro, seguido por um operando. Também é nomeado como notação polonesa. Por exemplo, +pq
<operadores> <operandos> <operandos>
Por exemplo: p * ( q + r ) / s
A avaliação precisa ser realizada da esquerda para a direita e os colchetes não alteram ou alteram o padrão da equação. Aqui, a adição precisa ser concluída antes da multiplicação porque a posição “+” fica à esquerda de “*”.
Aqui, cada operador executa operações em valores imediatamente à esquerda deles. Por exemplo, o “+” acima usa o “q” e o “r”. Podemos resumir colchetes para tornar isso evidente:
((p (qr +) *) s/)
Assim, o “( )” considera e utiliza os dois valores imediatamente anteriores ao “p”, e o resultado do +. Da mesma forma, o “/” usa o resultado da expressão de multiplicação e o “s”.

3. Notação Pós-fixada
A notação pós-fixada, principalmente o operando, é escrita, seguida por um operador. Também é chamado de notação polonesa reversa, por exemplo, pq+
<operandos> <operandos> <operadores>
Quanto ao Postfix, o mesmo que a operação Prefix da expressão é da esquerda para a direita e “( )” são desnecessários. Aqui, os operadores executam nos dois valores mais próximos da direita. No exemplo abaixo, colchetes são adicionados desnecessariamente, para deixar claro que não há impacto na avaliação.
(/(*p(+qr))s)
Aqui, os valores da operação “avaliação do operador é da esquerda para a direita” estão à direita e, se os próprios valores envolverem cálculos, haverá uma mudança na ordem de avaliação. Tomando o exemplo listado acima, veja que “/” é o operador primário à esquerda.
Ele espera até que a operação de multiplicação seja concluída. E principalmente, a operação de multiplicação precisa ser executada antes que o cálculo da divisão seja iniciado (e do exemplo acima, fica claro que a operação de adição precisa ser concluída antes da operação de multiplicação).
Porque os operadores Postfix Notation usam o valor à sua direita; quaisquer valores que envolvam cálculos terão o cálculo já concluído à medida que avançamos para a esquerda. Assim, podemos concluir que o cálculo da expressão não é o mesmo que a operação do operador Prefixo.
Para destacar todas as três notações, os operandos vêm na mesma ordem e os operadores precisam ser movidos para fornecer o significado correto durante o cálculo. Isso precisa ser considerado particularmente ao considerar os operadores assimétricos “-” e “/” para deixar claro pq é sempre qr a menos que tenham o mesmo valor; os valores são equivalentes a “pq -” ou “- pq”
P+q ≡ +pq ≡ pq+
Por exemplo:
Infixo-p * q + r/s
Prefixo – pq * rs / +
Pós-correção – + * pq / rs
Primeiro, para realizar a operação, multiplique p e q e depois divida r por s e, por fim, some os resultados.
Abaixo resumos da tabela entre as três notações,
| Notação Infixa | Notação polonesa | Notação polonesa reversa |
| p+q | +pq | pq+ |
| (p+q)*r | +*pq | pqr+* |
| p*(q+r) | *p+qr | pqr*+ + |
| p÷q+r÷s | +÷pq÷rs | pq÷rs÷+ |
| (pq)*(rs) | *-pq-rs | pq-rs-* |
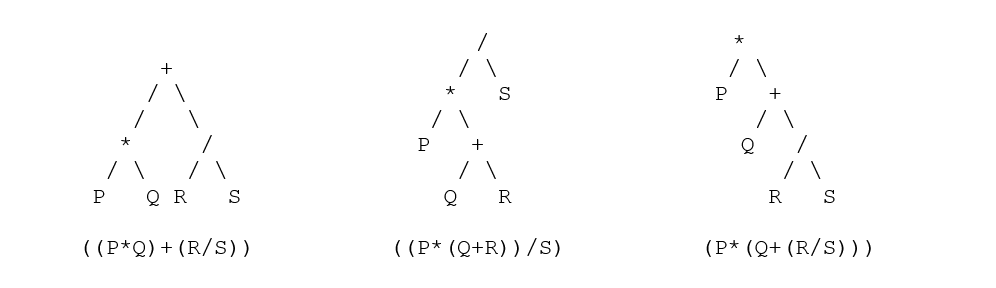
Conversão entre notações
*Para fornecer uma visão clara, os colchetes são adicionados na expressão,
| Infixo | Pós-fixação | Prefixo |
| ((p*q) + (r/s)) | ((pq*)(rs/)+) | (+ (* pq) (/rs)) |
| ((p * (q + r) ) / s) | ((p(qr+)*)s/) | (/(*p(+qr))s) |
| (p* (q + (r/s))) | (p (q (rs /) +) *) | (*p(+q(/rs))) |
- Você pode iniciar a conversão diretamente nas formas entre colchetes por operadores entre colchetes, por exemplo (m + n) ou (mn +) ou (+ mn). Agora repita isso em todos os operadores removendo os colchetes indesejados.
- Agora use este truque mostrado acima para converter e analisar árvores – as árvores de análise equivalentes para cada nó são:
Checkout: estrutura de dados e algoritmo em Python
Conclusão
Análise de Expressão na Estrutura de Dados , Infixo, Pós-fixo e Notações de Prefixo em expressões aritméticas são bastante diferentes, mas têm as mesmas formas de escrever expressões. O conhecimento destes é essencial para escrever programas.
Em uma linguagem de programação de computador, a expressão é considerada e analisada a partir da string. A regra de Associatividade e Precedência muda bastante em diferentes linguagens.
Por que escolher um curso de Ciência de Dados com o upGrad?
A ciência de dados é um dos campos em expansão na ciência da computação. As empresas precisam de programadores que tenham um bom conhecimento do básico, o que é fundamental para programar independentemente da linguagem de codificação.
O upGrad se concentra em fornecer aulas perspicazes e informativas, cobrindo todas as necessidades básicas para se tornar um cientista de dados. Programa PG Executivo de 12 meses do upGrad em Ciência de Dados. , oferecido pelo IIIT Bangalore, é o primeiro curso certificado NASSCOM da Índia, que vem com orientação personalizada 1:1 de especialistas da indústria de ciência de dados, cobrindo todas as linguagens de programação, ferramentas e bibliotecas essenciais. Ele fornece a melhor base para iniciar seu trabalho de ciência de dados bem remunerado.
O que são Estruturas de Dados?
As estruturas de dados são usadas para organizar os dados na memória. Existem vários métodos para organizar dados na memória, incluindo arrays, listas, pilhas, filas e muitos outros. A estrutura de dados não é uma linguagem de programação como C, C++ ou Java. Em vez disso, é um conjunto de técnicas que estão sendo usadas para organizar dados na memória em qualquer linguagem de programação. Uma estrutura de dados é um método eficiente de organizar, manipular e armazenar dados. Os itens de dados podem ser simplesmente percorridos com a ajuda da estrutura de dados. É crucial para melhorar a velocidade de um programa, pois o principal trabalho do programa é salvar e recuperar os dados do usuário o mais rápido possível.
Quais são os usos reais da análise de dados?
O processo de transformar dados de um formato para outro é conhecido como análise de dados. Eles são amplamente usados em compiladores para analisar código de computador e gerar código de máquina. O processo de conversão de dados de um formato para outro é conhecido como análise de dados. Como o HTML bruto que recebemos é difícil de entender, os analisadores geralmente são empregados na extração online. Exigimos que os dados sejam convertidos em um formato legível por humanos. Isso pode implicar na criação de relatórios usando strings ou tabelas HTML para fornecer as informações mais relevantes.
Como a Associatividade e a Precedência ajudam na estruturação de dados?
A ordem de avaliação das expressões é determinada por duas propriedades dos operadores: precedência e associatividade. A precedência ajuda a estabelecer como os termos de uma expressão devem ser agrupados e como uma expressão deve ser avaliada. Como a maioria das expressões usa a estrutura BODMAS, alguns operadores têm precedência sobre outros. Quando dois operadores têm a mesma precedência em uma expressão, a regra de associatividade é aplicada. De acordo com a preferência do compilador, a associatividade pode ser da esquerda para a direita ou da direita para a esquerda.