
Arquitetura básica da CNN: explicando 5 camadas de rede neural convolucional
Publicados: 2020-12-07Índice
Introdução
Nos últimos anos do setor de TI, houve uma enorme demanda por um conjunto de habilidades específico conhecido como Deep Learning. Deep Learning é um subconjunto de Machine Learning que consiste em algoritmos inspirados no funcionamento do cérebro humano ou nas redes neurais.
Essas estruturas são chamadas de Redes Neurais. Ele ensina o computador a fazer o que é natural para os humanos. Deep Learning, existem vários tipos de modelos como as Redes Neurais Artificiais (RNA), Autoencoders, Redes Neurais Recorrentes (RNN) e Aprendizado por Reforço. Mas houve um modelo em particular que contribuiu muito no campo da visão computacional e análise de imagens que são as Redes Neurais Convolucionais (CNN) ou as ConvNets.
CNNs são uma classe de redes neurais profundas que podem reconhecer e classificar características particulares de imagens e são amplamente utilizadas para analisar imagens visuais. Suas aplicações vão desde reconhecimento de imagem e vídeo, classificação de imagem, análise de imagem médica, visão computacional e processamento de linguagem natural.
O termo 'convolução' na CNN denota a função matemática de convolução que é um tipo especial de operação linear em que duas funções são multiplicadas para produzir uma terceira função que expressa como a forma de uma função é modificada pela outra. Em termos simples, duas imagens que podem ser representadas como matrizes são multiplicadas para dar uma saída que é usada para extrair características da imagem.
Aprenda Machine Learning on-line nas principais universidades do mundo - mestrados, programas de pós-graduação executiva e programa de certificação avançada em ML e IA para acelerar sua carreira.
Aprenda: Introdução ao Deep Learning e Redes Neurais

Arquitetura Básica
Há duas partes principais em uma arquitetura CNN
- Uma ferramenta de convolução que separa e identifica os vários recursos da imagem para análise em um processo chamado de Extração de Recursos
- Uma camada totalmente conectada que utiliza a saída do processo de convolução e prevê a classe da imagem com base nos recursos extraídos nas etapas anteriores.
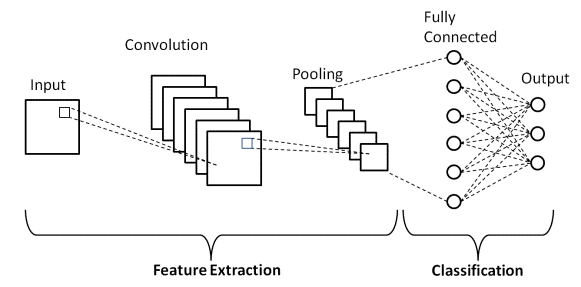
Fonte
Camadas de Convolução
Existem três tipos de camadas que compõem a CNN, que são as camadas convolucionais, camadas de pool e camadas totalmente conectadas (FC). Quando essas camadas são empilhadas, uma arquitetura CNN será formada. Além dessas três camadas, existem dois parâmetros mais importantes que são a camada dropout e a função de ativação que são definidas abaixo.
1. Camada Convolucional
Essa camada é a primeira camada usada para extrair os vários recursos das imagens de entrada. Nesta camada, a operação matemática de convolução é realizada entre a imagem de entrada e um filtro de um determinado tamanho MxM. Ao deslizar o filtro sobre a imagem de entrada, o produto escalar é obtido entre o filtro e as partes da imagem de entrada em relação ao tamanho do filtro (MxM).
A saída é denominada como mapa de recursos que nos fornece informações sobre a imagem, como cantos e bordas. Mais tarde, esse mapa de recursos é alimentado para outras camadas para aprender vários outros recursos da imagem de entrada.
2. Camada de Agrupamento
Na maioria dos casos, uma Camada Convolucional é seguida por uma Camada de Pooling. O objetivo principal desta camada é diminuir o tamanho do mapa de feições convoluído para reduzir os custos computacionais. Isso é realizado diminuindo as conexões entre as camadas e opera independentemente em cada mapa de recursos. Dependendo do método usado, existem vários tipos de operações de pooling.
No Max Pooling, o maior elemento é retirado do mapa de recursos. Average Pooling calcula a média dos elementos em uma seção de imagem de tamanho predefinido. A soma total dos elementos na seção predefinida é calculada em Sum Pooling. A camada de pool geralmente serve como uma ponte entre a camada convolucional e a camada FC
Leitura obrigatória: ideias de projetos de rede neural
3. Camada Totalmente Conectada
A camada Totalmente Conectada (FC) consiste nos pesos e tendências junto com os neurônios e é usada para conectar os neurônios entre duas camadas diferentes. Essas camadas geralmente são colocadas antes da camada de saída e formam as últimas camadas de uma Arquitetura CNN.
Neste, a imagem de entrada das camadas anteriores é achatada e alimentada na camada FC. O vetor achatado passa então por mais algumas camadas FC onde geralmente ocorrem as operações das funções matemáticas. Nesta etapa, o processo de classificação começa a ocorrer.
4. Desistência
Normalmente, quando todos os recursos estão conectados à camada FC, isso pode causar overfitting no conjunto de dados de treinamento. O overfitting ocorre quando um modelo específico funciona tão bem nos dados de treinamento, causando um impacto negativo no desempenho do modelo quando usado em novos dados.
Para superar esse problema, uma camada de dropout é utilizada, na qual alguns neurônios são descartados da rede neural durante o processo de treinamento, resultando em tamanho reduzido do modelo. Ao passar um dropout de 0,3, 30% dos nós são descartados aleatoriamente da rede neural.
5. Funções de ativação
Finalmente, um dos parâmetros mais importantes do modelo CNN é a função de ativação. Eles são usados para aprender e aproximar qualquer tipo de relação contínua e complexa entre variáveis da rede. Em palavras simples, ele decide quais informações do modelo devem disparar na direção direta e quais não devem ser disparadas no final da rede.

Acrescenta não linearidade à rede. Existem várias funções de ativação comumente usadas, como as funções ReLU, Softmax, tanH e Sigmoid. Cada uma dessas funções tem um uso específico. Para um modelo CNN de classificação binária, as funções sigmoid e softmax são preferidas e para uma classificação multiclasse, geralmente são usadas softmax us.
Arquitetura LeNet-5 CNN
Em 1998, a arquitetura LeNet-5 foi introduzida em um trabalho de pesquisa intitulado “Gradient-Based Learning Applied to Document Recognition” por Yann LeCun, Leon Bottou, Yoshua Bengio e Patrick Haffner. É uma das primeiras e mais básicas arquiteturas da CNN.
É composto por 7 camadas. A primeira camada consiste em uma imagem de entrada com dimensões de 32×32. É convoluído com 6 filtros de tamanho 5×5 resultando em dimensão de 28x28x6. A segunda camada é uma operação de Pooling que filtra tamanho 2×2 e passo de 2. Portanto, a dimensão da imagem resultante será 14x14x6.
Da mesma forma, a terceira camada também envolve uma operação de convolução com 16 filtros de tamanho 5×5 seguido de uma quarta camada de agrupamento com tamanho de filtro semelhante de 2×2 e passo de 2. Assim, a dimensão da imagem resultante será reduzida para 5x5x16.
Uma vez que a dimensão da imagem é reduzida, a quinta camada é uma camada convolucional totalmente conectada com 120 filtros cada um de tamanho 5×5. Nesta camada, cada uma das 120 unidades desta camada será conectada às 400 (5x5x16) unidades das camadas anteriores. A sexta camada também é uma camada totalmente conectada com 84 unidades.
A sétima camada final será uma camada de saída softmax com 'n' classes possíveis dependendo do número de classes no conjunto de dados.
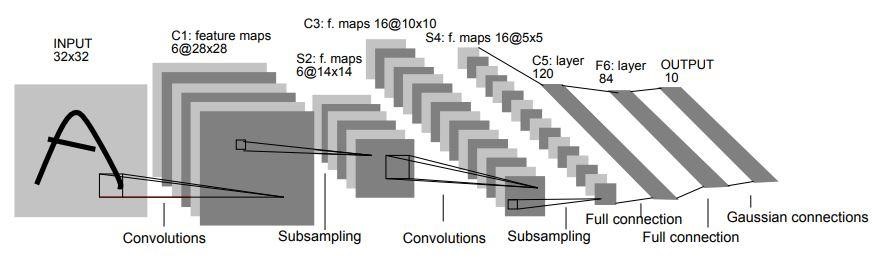
Fonte
O diagrama acima é uma representação das 7 camadas da Arquitetura LeNet-5 CNN.
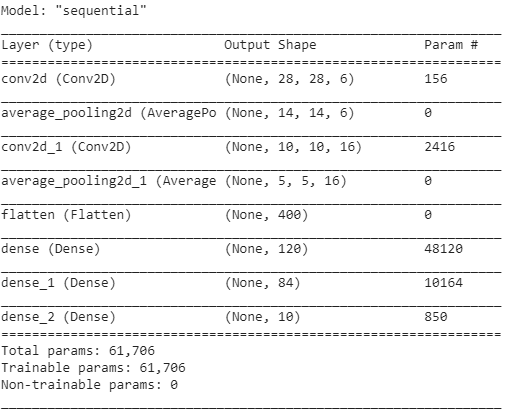
Abaixo estão os instantâneos do código Python para construir uma arquitetura LeNet-5 CNN usando a biblioteca keras com o framework TensorFlow

Na Programação Python, o tipo de modelo mais comumente usado é o tipo Sequencial. É a maneira mais fácil de construir um modelo CNN em keras. Ele nos permite construir um modelo camada por camada. A função 'add()' é usada para adicionar camadas ao modelo. Como explicado acima, para a arquitetura LeNet-5, existem dois pares Convolution e Pooling seguidos por uma camada Flatten que geralmente é usada como uma conexão entre as camadas Convolution e Dense.
As camadas Densas são as mais usadas para as camadas de saída. A ativação utilizada é a 'Softmax' que dá uma probabilidade para cada classe e elas somam totalmente 1. O modelo fará sua previsão com base na classe com maior probabilidade.
O resumo do modelo é exibido como abaixo.
Conclusão
Assim, neste artigo entendemos a estrutura básica da CNN, sua arquitetura e as várias camadas que compõem o modelo CNN. Além disso, vimos um exemplo de arquitetura de um modelo LeNet-5 muito famoso e tradicional com seu programa Python.
Se você estiver interessado em saber mais sobre os cursos de aprendizado de máquina, confira o Programa PG Executivo do IIIT-B e do upGrad em aprendizado de máquina e IA , projetado para profissionais que trabalham e oferece mais de 450 horas de treinamento rigoroso, mais de 30 estudos de caso e atribuições, Status de ex-aluno do IIIT-B, mais de 5 projetos práticos práticos e assistência de trabalho com as principais empresas.
O que são funções de ativação na CNN?
A função de ativação é um dos componentes mais vitais no modelo CNN. Eles são utilizados para aprender e aproximar qualquer forma de associação de variável para variável de rede que seja contínua e complexa. Em termos simples, determina quais informações do modelo devem fluir na direção direta e quais não devem fluir no final da rede. Dá a não-linearidade da rede. As funções ReLU, Softmax, tanH e Sigmoid são algumas das funções de ativação mais utilizadas. Todas essas funções têm usos distintos. Para um modelo CNN de 2 classes, as funções sigmoid e softmax são favorecidas, enquanto softmax é normalmente empregado para classificação multiclasse.
Quais são os componentes básicos da arquitetura de rede neural convolucional?
Uma camada de entrada, uma camada de saída e várias camadas ocultas compõem as redes convolucionais. Os neurônios nas camadas de uma rede convolucional são organizados em três dimensões, diferentemente daqueles em uma rede neural padrão (dimensões de largura, altura e profundidade). Isso permite que a CNN converta um volume de entrada tridimensional em um volume de saída. Convolução, agrupamento, normalização e camadas totalmente conectadas compõem as camadas ocultas. Múltiplas camadas conv são usadas em CNNs para filtrar volumes de entrada para níveis mais altos de abstração.
Qual é o benefício das arquiteturas padrão da CNN?
Enquanto as arquiteturas de rede tradicionais consistiam apenas em camadas convolucionais empilhadas, as arquiteturas mais recentes buscam maneiras novas e inovadoras de construir camadas convolucionais para melhorar a eficiência do aprendizado. Essas arquiteturas fornecem recomendações gerais de arquitetura para os praticantes de aprendizado de máquina se adaptarem para lidar com uma variedade de problemas de visão computacional. Essas arquiteturas podem ser utilizadas como extratores de recursos avançados para classificação de imagens, identificação de objetos, segmentação de imagens e uma variedade de outras tarefas avançadas.