
Homoskedastyczność w uczeniu maszynowym: wykrywanie, efekty i sposób leczenia
Opublikowany: 2021-01-06Pod koniec tego samouczka zdobędziesz wiedzę na następujące tematy:
- Co to jest homoskedastyczność i heteroskedastyczność?
- Jak sprawdzić, czy występuje heteroskedastyczność.
- Skutki heteroskedastyczności w uczeniu maszynowym.
- Leczenie heteroskedastyczności.
Spis treści
Co to jest homoskedastyczność i heteroskedastyczność?
Homoskedastyczność oznacza bycie „tej samej wariancji”. W regresji liniowej jednym z głównych założeń jest to, że w błędach lub składnikach resztowych występuje homoskedastyczność (Y_Pred – Y_actual).
Innymi słowy, regresja liniowa zakłada, że we wszystkich przypadkach warunki błędu będą takie same i będą miały bardzo małą wariancję.
Zrozummy to na przykładzie. Rozważmy dwie zmienne – powierzchnia dywanu w domu i cena domu. Wraz ze wzrostem powierzchni dywanów rosną również ceny.
Dopasowujemy więc model regresji liniowej i widzimy, że wszystkie błędy mają tę samą wariancję. Wykres na poniższym obrazku przedstawia obszar dywanu na osi X i cenę na osi Y.
Jak widać, przewidywania są prawie wzdłuż linii regresji liniowej i mają podobną wariancję w całym tekście.

Ponadto, jeśli wykreślimy te reszty na osi X, zobaczymy je wzdłuż linii prostej równoległej do osi X. To wyraźny znak homoskedastyczności

Źródło obrazu
Naruszenie tego warunku oznacza, że w modelu występuje heteroskedastyczność. Rozważając ten sam przykład co powyżej, załóżmy, że w przypadku domów o mniejszej powierzchni dywanu błędy lub pozostałości są bardzo małe. Wraz ze wzrostem powierzchni dywanu zwiększa się wariancja przewidywań, co skutkuje wzrostem wartości błędu lub wartości resztowych. Kiedy ponownie wykreślimy wartości, widzimy typową krzywą stożkową, która silnie wskazuje na obecność heteroscedstyczności w modelu.
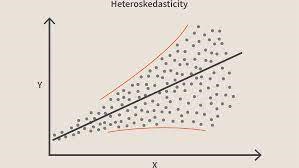
Źródło obrazuMówiąc konkretnie, heteroskedastyczność to systematyczny wzrost lub spadek wariancji reszt w zakresie zmiennych niezależnych. Jest to problem, ponieważ homoskedastyczność jest założeniem regresji liniowej i wszystkie błędy powinny mieć tę samą wariancję. Dowiedz się więcej o regresji liniowej
Dołącz do kursu uczenia maszynowego online z najlepszych uniwersytetów na świecie — studiów magisterskich, programów podyplomowych dla kadry kierowniczej i zaawansowanego programu certyfikacji w zakresie uczenia maszynowego i sztucznej inteligencji, aby przyspieszyć swoją karierę.
Jak się dowiedzieć, czy występuje heteroskedastyczność?
Mówiąc najprościej, najłatwiejszym sposobem sprawdzenia, czy występuje heteroskedastyczność, jest wykreślenie wykresu reszt. Jeśli zauważysz jakiś wzór, oznacza to, że istnieje heteroskedastyczność. Zazwyczaj wartości rosną wraz ze wzrostem wartości dopasowanej, tworząc w ten sposób krzywą w kształcie stożka.
Przeczytaj: Pomysły na projekty uczenia maszynowego
Zwykłe powody heteroskedastyczności
- Gdy w zmiennej występuje duża wariancja. Innymi słowy, gdy najmniejsza i największa wartość w zmiennej są zbyt ekstremalne. Mogą to być również wartości odstające.
- Kiedy dopasowujesz niewłaściwy model. Jeśli dopasujesz model regresji liniowej do danych, które są nieliniowe, doprowadzi to do heteroskedastyczności.
- Gdy skala wartości w zmiennej nie jest taka sama.
- Gdy do regresji używana jest błędna transformacja danych.
- Kiedy w danych występuje skośność lewa/prawa.
Czysta i nieczysta heteroskedastyczność
Teraz z powyższych powodów, heteroskedastyczność może być czysta lub nieczysta. Kiedy dopasujemy odpowiedni model (liniowy lub nieliniowy) i jeśli w resztach jest jeszcze widoczny wzór, nazywa się to czystą heteroskedastycznością.
Jeśli jednak dopasujemy niewłaściwy model, a następnie zaobserwujemy wzorzec w resztach, to mamy do czynienia z nieczystą heteroskedastycznością. W zależności od rodzaju heteroskedastyczności należy podjąć środki w celu jej przezwyciężenia. Zależy to również od domeny, w której pracujesz, i różni się w zależności od domeny.
Skutki heteroskedastyczności w uczeniu maszynowym
Jak omówiliśmy wcześniej, model regresji liniowej zakłada istnienie homoskedastyczności w danych. Jeśli to założenie zostanie złamane, nie będziemy mogli ufać otrzymanym wynikom.
Jeśli występuje heteroskedastyczność, instancje o dużej wariancji będą miały większy wpływ na przewidywanie, którego nie chcemy.
- Obecność heteroskedastyczności sprawia, że współczynniki są mniej precyzyjne, a co za tym idzie prawidłowe współczynniki są dalej od wartości populacji.
- Heteroskedastyczność może również dawać wartości p mniejsze niż wartości rzeczywiste. Wynika to z faktu, że wariancja oszacowań współczynników wzrosła, ale standardowy model OLS (Ordinary Least Squares) jej nie wykrył. Dlatego model OLS oblicza wartości p przy użyciu niedoszacowanej wariancji. Może to prowadzić nas do błędnego wniosku, że współczynniki regresji są istotne, gdy w rzeczywistości nie są istotne.
- Wygenerowane błędy standardowe również będą stronnicze. Błędy standardowe mają kluczowe znaczenie przy obliczaniu istotnych testów i przedziałów ufności. Jeżeli błędy standardowe są obciążone, będzie to oznaczać, że testy są niepoprawne, a oszacowania współczynnika regresji będą niepoprawne.
Jak leczyć heteroskedastyczność?
Jeśli wykryjesz obecność heteroskedastyczności, istnieje wiele sposobów na jej rozwiązanie. Najpierw rozważmy przykład, w którym mamy 2 zmienne: populację miasta i liczbę infekcji COVID-19.

Teraz w tym przykładzie będzie ogromna różnica w liczbie infekcji w dużych miastach w porównaniu z małymi miastami trzeciego poziomu. Zmienna Liczba infekcji będzie niezależna, a Populacja miasta będzie zmienną zależną.
Zastanów się, czy dopasuj model regresji do tych danych i zaobserwuj heteroskedastyczność podobną do powyższego obrazu. Teraz wiemy, że w modelu występuje heteroskedastyczność i należy ją naprawić.
Teraz pierwszym krokiem byłoby zidentyfikowanie źródła heteroskedastyczności. W naszym przypadku jest to zmienna o dużej wariancji.
Istnieje wiele sposobów radzenia sobie z heteroskedastycznością, ale przyjrzymy się trzem takim metodom.
Manipulowanie zmiennymi
Możemy dokonać pewnych modyfikacji zmiennych/cech, które musimy zmniejszyć, aby zmniejszyć wpływ tej dużej wariancji na przewidywania modelu. Jednym ze sposobów, aby to zrobić, jest zmodyfikowanie funkcji na stawki i wartości procentowe, a nie na rzeczywiste wartości.
Sprawiłoby to, że funkcje przekazywałyby nieco inne informacje, ale warto spróbować. Od problemu i danych będzie również zależeć, czy tego typu podejście można wdrożyć, czy nie.
Ta metoda wymaga najmniejszej modyfikacji funkcji i często pomaga rozwiązać problem, a w niektórych przypadkach nawet poprawić wydajność modelu.
Tak więc w naszym przypadku możemy zmienić funkcję „Liczba infekcji” na „Współczynnik infekcji”. Pomoże to zmniejszyć wariancję, ponieważ oczywiście liczba infekcji w miastach o dużej populacji będzie duża.
Regresja ważona
Regresja ważona to modyfikacja normalnej regresji, w której punktom danych przypisuje się określone wagi zgodnie z ich wariancją. Te z dużą wariancją otrzymują małe wagi, a te z mniejszą wariancją otrzymują większe wagi.
Więc kiedy te wagi są podnoszone do kwadratu, kwadrat małych wag nie docenia efektu dużej wariancji.
Gdy stosowane są prawidłowe wagi, heteroskedastyczność zastępuje się homoskedastycznością. Ale jak znaleźć prawidłowe wagi? Jednym szybkim sposobem jest użycie odwrotności tej zmiennej jako wagi.
Tak więc w naszym przypadku wagą będzie odwrotność populacji miasta.
Transformacje
Przekształcenie danych jest ostatecznością, ponieważ w ten sposób traci się możliwość interpretacji funkcji.
Oznacza to, że nie możesz już łatwo wyjaśnić, co pokazuje funkcja.
Jednym ze sposobów może być użycie przekształceń Boxa-Coxa i przekształceń logów.
Zanim pójdziesz
Przyczyn heteroskedastyczności w Twoich danych może być wiele. Różni się również bardzo od jednej domeny do drugiej.
Dlatego ważne jest, aby mieć wiedzę o tym również przed rozpoczęciem powyższych procesów w celu usunięcia heteroskedastyczności.
W tym blogu omówiliśmy homoskedastyczność i heteroskedastyczność oraz to, jak można je wykorzystać do zaimplementowania kilku algorytmów uczenia maszynowego.
Jeśli chcesz dowiedzieć się więcej o uczeniu maszynowym, zapoznaj się z programem IIIT-B i upGrad Executive PG w zakresie uczenia maszynowego i sztucznej inteligencji , który jest przeznaczony dla pracujących profesjonalistów i oferuje ponad 450 godzin rygorystycznych szkoleń, ponad 30 studiów przypadków i zadań, IIIT Status -B Alumni, ponad 5 praktycznych praktycznych projektów zwieńczenia i pomoc w pracy z najlepszymi firmami.
Co oznacza regresja ważona lokalnie w uczeniu maszynowym?
Jaki jest biały test na heteroskedastyczność?
Jeśli chcesz, aby zmienna niezależna miała interaktywny, nieliniowy wpływ na wariancję, do sprawdzenia heteroskedastyczności preferowane jest użycie białego testu. Jednak biały test, będący testem asymptotycznym, jest preferowany tylko w przypadku dużych próbek. Proces heteroskedastyczności może być funkcją jednej lub więcej zmiennych niezależnych przy użyciu testu White'a. Jest porównywalny z testem Breuscha-Pagana, jedyną różnicą jest to, że test White'a pozwala na nieliniowy i interaktywny wpływ zmiennej niezależnej na wariancję błędu.
Jaka dokładnie jest hipoteza zerowa dotycząca heteroskedastyczności?
Istnienie wartości odstających w danych powoduje heteroskedastyczność. Heteroskedastyczność można również uzyskać, gdy w modelu pominięto zmienne. Heteroskedastyczność implikuje tylko dwie hipotezy: hipotezę zerową i hipotezę alternatywną. Przy stosowaniu testu White'a, Breuscha-Pagana lub Cooka-Weisberga do sprawdzenia heteroskedastyczności hipoteza zerowa jest prawdziwa, jeśli wariancje błędów są równe. Hipoteza alternatywna występuje, gdy wariancje błędów nie są identyczne.