
Homoskedastisitas Dalam Pembelajaran Mesin: Deteksi, Efek & Cara Mengobati
Diterbitkan: 2021-01-06Pada akhir tutorial ini, Anda akan memiliki pengetahuan tentang hal-hal berikut:
- Apa itu Homoskedastisitas & Heteroskedastisitas?
- Bagaimana mengetahui adanya Heteroskedastisitas.
- Pengaruh Heteroskedastisitas dalam Pembelajaran Mesin.
- Mengobati Heteroskedastisitas.
Daftar isi
Apa Itu Homoskedastisitas & Heteroskedastisitas?
Homoskedastisitas berarti menjadi "Varians yang sama". Dalam Regresi Linier, salah satu asumsi utama adalah adanya Homoskedastisitas dalam galat atau suku sisa (Y_Pred – Y_aktual).
Dengan kata lain, Regresi Linier mengasumsikan bahwa untuk semua contoh, istilah kesalahan akan sama dan varians yang sangat kecil.
Mari kita memahaminya dengan bantuan sebuah contoh. Pertimbangkan kita memiliki dua variabel – Luas karpet rumah dan harga rumah. Karena luas karpet meningkat, harganya juga meningkat.
Jadi kami cocok dengan model regresi linier dan melihat bahwa kesalahan memiliki varians yang sama di seluruh. Grafik pada gambar di bawah ini memiliki Area Karpet pada sumbu X dan Harga pada sumbu Y.
Seperti yang Anda lihat, prediksi hampir sepanjang garis regresi linier dan dengan varians serupa di seluruh.

Juga, jika kita memplot residual ini pada sumbu X, kita akan melihatnya dalam garis lurus yang sejajar dengan sumbu X. Ini adalah tanda yang jelas dari Homoskedastisitas

Sumber Gambar
Bila kondisi ini dilanggar, berarti terjadi Heteroskedastisitas pada model. Mempertimbangkan contoh yang sama seperti di atas, katakanlah untuk rumah dengan area karpet yang lebih kecil kesalahan atau residu atau sangat kecil. Dan seiring bertambahnya luas karpet, varians dalam prediksi meningkat yang menghasilkan peningkatan nilai kesalahan atau suku sisa. Ketika kita memplot nilai lagi kita melihat kurva Kerucut khas yang sangat menunjukkan adanya Heteroskedastisitas dalam model.
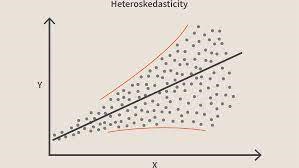
Sumber GambarSecara khusus, Heteroskedastisitas adalah peningkatan atau penurunan sistematis dalam varians residual selama rentang variabel independen. Ini adalah masalah karena Homoskedastisitas adalah asumsi regresi linier dan semua kesalahan harus memiliki varian yang sama. Pelajari lebih lanjut tentang Regresi linier
Bergabunglah dengan Kursus Pembelajaran Mesin online dari Universitas top dunia – Magister, Program Pascasarjana Eksekutif, dan Program Sertifikat Tingkat Lanjut di ML & AI untuk mempercepat karier Anda.
Bagaimana Mengetahui Jika Heteroskedastisitas Ada?
Secara sederhana, cara termudah untuk mengetahui adanya Heteroskedastisitas adalah dengan memplot grafik residual. Jika Anda melihat ada pola yang ada maka ada Heteroskedastisitas. Biasanya nilai meningkat saat nilai pas meningkat, sehingga membuat kurva berbentuk kerucut.
Baca: Ide Proyek Pembelajaran Mesin
Alasan Biasa Untuk Heteroskedastisitas
- Ketika ada varians yang besar dalam suatu variabel. Dengan kata lain, ketika nilai terkecil dan terbesar dalam suatu variabel terlalu ekstrim. Ini juga bisa menjadi outlier.
- Ketika Anda memasang model yang salah. Jika model regresi linier dicocokkan dengan data yang tidak linier, maka akan terjadi Heteroskedastisitas.
- Ketika skala nilai dalam suatu variabel tidak sama.
- Ketika transformasi yang salah pada data digunakan untuk regresi.
- Ketika ada kemiringan kiri/kanan dalam data.
Heteroskedastisitas Murni Vs Tidak Murni
Sekarang dengan alasan di atas, Heteroskedastisitas bisa Murni atau Tidak Murni. Ketika kita cocok dengan model yang tepat (linier atau non-linier) dan jika masih ada pola yang terlihat di residual maka itu disebut Heteroskedastisitas Murni.
Namun, jika kita memasukkan model yang salah dan kemudian mengamati pola pada residual maka itu adalah kasus Heteroskedastisitas Tidak Murni. Tergantung pada jenis Heteroskedastisitas, tindakan perlu diambil untuk mengatasinya. Itu juga tergantung pada domain tempat Anda bekerja dan bervariasi dari domain ke domain.
Pengaruh Heteroskedastisitas Dalam Pembelajaran Mesin
Seperti yang telah kita bahas sebelumnya, model regresi linier membuat asumsi tentang Homoskedastisitas yang ada dalam data. Jika asumsi itu dipatahkan maka kita tidak akan bisa mempercayai hasil yang kita dapatkan.
Jika terdapat Heteroskedastisitas maka kejadian dengan varians yang tinggi akan berdampak lebih besar pada prediksi yang tidak kita inginkan.
- Adanya Heteroskedastisitas membuat koefisien menjadi kurang tepat dan karenanya koefisien yang benar semakin jauh dari nilai populasi.
- Heteroskedastisitas juga cenderung menghasilkan nilai p yang lebih kecil dari nilai sebenarnya. Hal ini disebabkan varians dari estimasi koefisien telah meningkat tetapi model standar OLS (Ordinary Least Squares) tidak mendeteksinya. Oleh karena itu model OLS menghitung nilai-p menggunakan varians yang diremehkan. Hal ini dapat menyebabkan kita salah membuat kesimpulan bahwa koefisien regresi signifikan padahal sebenarnya tidak signifikan.
- Standar error yang dihasilkan juga akan bias. Kesalahan standar sangat penting dalam menghitung tes signifikan dan interval kepercayaan. Jika kesalahan Standar bias, itu berarti bahwa tes tidak benar dan perkiraan koefisien regresi akan salah.
Bagaimana Mengobati Heteroskedastisitas?
Jika Anda mendeteksi adanya Heteroskedastisitas, maka ada beberapa cara untuk mengatasinya. Pertama, mari kita perhatikan contoh di mana kita memiliki 2 variabel: Populasi Kota dan Jumlah Infeksi COVID-19.

Sekarang dalam contoh ini, akan ada perbedaan besar dalam jumlah infeksi di kota metro besar vs kota kecil tingkat-3. Variabel Jumlah Infeksi akan menjadi variabel independen dan Jumlah Penduduk Kota akan menjadi variabel dependen.
Pertimbangkan bahwa cocokkan model regresi untuk data ini dan amati Heteroskedastisitas yang mirip dengan gambar di atas. Jadi sekarang kita tahu bahwa ada Heteroskedastisitas yang ada dalam model dan perlu diperbaiki.
Sekarang langkah pertama adalah mengidentifikasi sumber Heteroskedastisitas. Dalam kasus kami, itu adalah variabel dengan varians yang besar.
Ada beberapa cara untuk menangani Heteroskedastisitas, tetapi kita akan melihat tiga metode tersebut.
Memanipulasi Variabel
Kita dapat membuat beberapa modifikasi pada variabel/fitur yang kita miliki untuk mengurangi dampak varians yang besar ini pada prediksi model. Salah satu cara untuk melakukan ini dengan memodifikasi fitur ke tarif dan persentase daripada nilai sebenarnya.
Ini akan membuat fitur menyampaikan informasi yang sedikit berbeda tetapi patut dicoba. Itu juga akan tergantung pada masalah dan data apakah pendekatan semacam ini dapat diterapkan atau tidak.
Metode ini melibatkan sedikit modifikasi dengan fitur dan sering membantu memecahkan masalah dan bahkan membuat kinerja model lebih baik dalam beberapa kasus.
Jadi dalam kasus kami, kami dapat mengubah fitur "Jumlah Infeksi" menjadi "Tingkat infeksi". Ini akan membantu mengurangi varians karena cukup jelas jumlah infeksi di kota-kota dengan populasi besar akan besar.
Regresi Tertimbang
Regresi berbobot adalah modifikasi dari regresi normal di mana titik-titik data diberi bobot tertentu sesuai dengan variansnya. Varians yang besar diberi bobot yang kecil dan yang variansnya lebih kecil diberi bobot yang lebih besar.
Jadi ketika bobot ini dikuadratkan, kuadrat bobot kecil meremehkan efek varians tinggi.
Ketika bobot yang benar digunakan, Heteroskedastisitas digantikan oleh Homoskedastisitas. Tapi bagaimana menemukan bobot yang benar? Salah satu cara cepat adalah dengan menggunakan kebalikan dari variabel itu sebagai bobot.
Jadi dalam kasus kami, bobotnya adalah Invers of City Population.
Transformasi
Mengubah data adalah pilihan terakhir karena dengan melakukan itu Anda kehilangan kemampuan interpretasi fitur.
Artinya, Anda tidak lagi dapat dengan mudah menjelaskan apa yang ditampilkan fitur tersebut.
Salah satu caranya adalah dengan menggunakan transformasi Box-Cox dan transformasi log.
Sebelum kamu pergi
Ada banyak alasan untuk Heteroskedastisitas dalam data Anda. Ini juga sangat bervariasi dari satu domain ke domain lainnya.
Jadi, penting untuk memiliki pengetahuan tentang itu juga sebelum Anda memulai dengan proses di atas untuk menghilangkan Heteroskedastisitas.
Di blog ini, kami membahas Homoskedastisitas dan Heteroskedastisitas dan bagaimana itu dapat digunakan untuk mengimplementasikan beberapa algoritma pembelajaran mesin.
Jika Anda tertarik untuk mempelajari lebih lanjut tentang pembelajaran mesin, lihat Program PG Eksekutif IIIT-B & upGrad dalam Pembelajaran Mesin & AI yang dirancang untuk para profesional yang bekerja dan menawarkan 450+ jam pelatihan ketat, 30+ studi kasus & tugas, IIIT -B Status Alumni, 5+ proyek batu penjuru praktis & bantuan pekerjaan dengan perusahaan-perusahaan top.
Apa yang dimaksud dengan regresi berbobot lokal dalam pembelajaran mesin?
Apa tes putih untuk heteroskedastisitas?
Jika Anda membutuhkan variabel independen Anda untuk memiliki efek non-linier interaktif pada varians, maka penggunaan tes putih lebih disukai untuk memeriksa heteroskedastisitas. Namun, tes putih, sebagai tes asimtotik, lebih disukai dalam kasus sampel besar saja. Proses heteroskedastisitas dapat menjadi fungsi dari satu atau lebih variabel independen Anda menggunakan uji White. Ini sebanding dengan tes Breusch-Pagan, satu-satunya perbedaan adalah bahwa tes Putih memungkinkan pengaruh nonlinier dan interaktif dari variabel independen pada varians kesalahan.
Apa sebenarnya hipotesis nol untuk heteroskedastisitas?
Adanya outlier pada data menyebabkan terjadinya heteroskedastisitas. Heteroskedastisitas juga dapat dihasilkan ketika variabel dihilangkan dari model. Heteroskedastisitas menyiratkan hanya dua hipotesis: hipotesis nol dan hipotesis alternatif. Ketika menerapkan tes White, Breusch-Pagan, atau tes Cook-Weisberg untuk memeriksa heteroskedastisitas, hipotesis nol benar jika varians kesalahannya sama. Hipotesis alternatif terjadi ketika varians kesalahan tidak identik.