
Homoscédasticité dans l'apprentissage automatique : détection, effets et traitement
Publié: 2021-01-06À la fin de ce didacticiel, vous aurez les connaissances suivantes :
- Qu'est-ce que l'homoscédasticité et l'hétéroscédasticité ?
- Comment savoir si l'hétéroscédasticité est présente.
- Effets de l'hétéroscédasticité dans l'apprentissage automatique.
- Traiter l'hétéroscédasticité.
Table des matières
Qu'est-ce que l'homoscédasticité et l'hétéroscédasticité ?
L'homoscédasticité signifie être de "la même variance". Dans la régression linéaire, l'une des principales hypothèses est qu'il existe une homocédasticité présente dans les erreurs ou les termes résiduels (Y_Pred - Y_actual).
En d'autres termes, la régression linéaire suppose que pour toutes les instances, les termes d'erreur seront les mêmes et de très peu de variance.
Comprenons-le à l'aide d'un exemple. Considérons que nous avons deux variables - la surface de la moquette de la maison et le prix de la maison. À mesure que la surface de tapis augmente, les prix augmentent également.
Nous ajustons donc un modèle de régression linéaire et voyons que les erreurs sont de la même variance partout. Le graphique dans l'image ci-dessous a la surface de tapis sur l'axe X et le prix sur l'axe Y.
Comme vous pouvez le voir, les prédictions sont presque le long de la ligne de régression linéaire et avec une variance similaire partout.

De plus, si nous traçons ces résidus sur l'axe X, nous le verrons le long d'une ligne droite parallèle à l'axe X. Ceci est un signe clair d'homoscédasticité

Source des images
Lorsque cette condition est violée, cela signifie qu'il y a hétéroscédasticité dans le modèle. Considérant le même exemple que ci-dessus, disons que pour les maisons avec moins de surface de tapis, les erreurs ou les résidus ou très petits. Et à mesure que la surface du tapis augmente, la variance des prédictions augmente, ce qui entraîne une augmentation de la valeur de l'erreur ou des termes résiduels. Lorsque nous traçons à nouveau les valeurs, nous voyons la courbe de cône typique qui indique fortement la présence d'hétéroscédsticité dans le modèle.
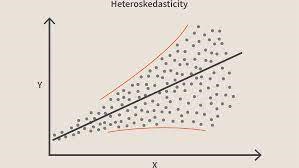
Source des imagesPlus précisément, l'hétéroscédasticité est une augmentation ou une diminution systématique de la variance des résidus sur la plage de variables indépendantes. C'est un problème car l'homoscédasticité est une hypothèse de régression linéaire et toutes les erreurs doivent avoir la même variance. En savoir plus sur la régression linéaire
Rejoignez le cours d'apprentissage automatique en ligne des meilleures universités du monde - Masters, programmes de troisième cycle pour cadres et programme de certificat avancé en ML et IA pour accélérer votre carrière.
Comment savoir si l'hétéroscédasticité est présente ?
Dans les termes les plus simples, le moyen le plus simple de savoir si l'hétéroscédasticité est présente est de tracer le graphique des résidus. Si vous voyez un motif présent, il y a hétéroscédasticité. Généralement, les valeurs augmentent à mesure que la valeur ajustée augmente, créant ainsi une courbe en forme de cône.
Lire : Idées de projets d'apprentissage automatique
Raisons habituelles de l'hétéroscédasticité
- Lorsqu'il y a une grande variance dans une variable. En d'autres termes, lorsque les valeurs les plus petites et les plus grandes d'une variable sont trop extrêmes. Ceux-ci peuvent également être des valeurs aberrantes.
- Lorsque vous adaptez le mauvais modèle. Si vous adaptez un modèle de régression linéaire à des données non linéaires, cela conduira à l'hétéroscédasticité.
- Lorsque l'échelle des valeurs d'une variable n'est pas la même.
- Lorsqu'une mauvaise transformation sur les données est utilisée pour la régression.
- Lorsqu'une asymétrie gauche/droite est présente dans les données.
Hétéroscédasticité pure vs impure
Maintenant, avec les raisons ci-dessus, l'hétéroscédasticité peut être pure ou impure. Lorsque nous ajustons le bon modèle (linéaire ou non linéaire) et s'il existe encore un motif visible dans les résidus, cela s'appelle l'hétéroscédasticité pure.
Cependant, si nous ajustons le mauvais modèle et observons ensuite un modèle dans les résidus, il s'agit alors d'un cas d'hétéroscédasticité impure. Selon le type d'hétéroscédasticité, des mesures doivent être prises pour la surmonter. Cela dépend également du domaine dans lequel vous travaillez et varie d'un domaine à l'autre.
Effets de l'hétéroscédasticité dans l'apprentissage automatique
Comme nous l'avons vu précédemment, le modèle de régression linéaire suppose que l'homoscédasticité est présente dans les données. Si cette hypothèse est brisée, nous ne pourrons pas faire confiance aux résultats que nous obtenons.
Si l'hétéroscédasticité est présente, les instances à forte variance auront un impact plus important sur la prédiction, ce que nous ne voulons pas.
- La présence d'hétéroscédasticité rend les coefficients moins précis et, par conséquent, les coefficients corrects sont plus éloignés de la valeur de la population.
- L'hétéroscédasticité est également susceptible de produire des valeurs de p inférieures aux valeurs réelles. Cela est dû au fait que la variance des estimations des coefficients a augmenté mais que le modèle standard OLS (Ordinary Least Squares) ne l'a pas détecté. Par conséquent, le modèle OLS calcule les valeurs de p en utilisant une variance sous-estimée. Cela peut nous amener à conclure à tort que les coefficients de régression sont significatifs alors qu'ils ne le sont en réalité pas.
- Les erreurs types produites seront également biaisées. Les erreurs standard sont cruciales dans le calcul des tests significatifs et des intervalles de confiance. Si les erreurs standard sont biaisées, cela signifie que les tests sont incorrects et que les estimations des coefficients de régression seront incorrectes.
Comment traiter l'hétéroscédasticité ?
Si vous détectez la présence d'hétéroscédasticité, il existe plusieurs façons de s'y attaquer. Considérons d'abord un exemple où nous avons 2 variables : Population de la ville et Nombre d'infections de COVID-19.

Maintenant, dans cet exemple, il y aura une énorme différence dans le nombre d'infections dans les grandes villes métropolitaines par rapport aux petites villes de niveau 3. La variable Nombre d'infections sera indépendante et Population de la ville sera une variable dépendante.
Considérez que vous ajustez un modèle de régression à ces données et observez l'hétéroscédasticité similaire à l'image ci-dessus. Nous savons donc maintenant qu'il existe une hétéroscédasticité dans le modèle et qu'elle doit être corrigée.
Maintenant, la première étape serait d'identifier la source de l'hétéroscédasticité. Dans notre cas, il s'agit de la variable à grande variance.
Il peut y avoir plusieurs façons de gérer l'hétéroscédasticité, mais nous examinerons trois de ces méthodes.
Manipuler les variables
Nous pouvons apporter quelques modifications aux variables/caractéristiques dont nous disposons pour réduire l'impact de cette grande variance sur les prédictions du modèle. Une façon de le faire en modifiant les caractéristiques en taux et pourcentages plutôt qu'en valeurs réelles.
Cela rendrait les fonctionnalités véhiculant des informations un peu différentes, mais cela vaut la peine d'essayer. Cela dépendra également du problème et des données si ce type d'approche peut être mis en œuvre ou non.
Cette méthode implique le moins de modifications avec les fonctionnalités et aide souvent à résoudre le problème et même à améliorer les performances du modèle dans certains cas.
Donc, dans notre cas, nous pouvons changer la fonctionnalité "Nombre d'infections" en "Taux d'infections". Cela aidera à réduire la variance car, de toute évidence, le nombre d'infections dans les villes à forte population sera important.
Régression pondérée
La régression pondérée est une modification de la régression normale dans laquelle les points de données se voient attribuer certains poids en fonction de leur variance. Ceux qui ont une grande variance reçoivent de petits poids et ceux qui ont moins de variance reçoivent des poids plus grands.
Ainsi, lorsque ces poids sont élevés au carré, le carré des petits poids sous-estime l'effet d'une variance élevée.
Lorsque les poids corrects sont utilisés, l'hétéroscédasticité est remplacée par l'homoscédasticité. Mais comment trouver les poids corrects ? Un moyen rapide consiste à utiliser l'inverse de cette variable comme poids.
Ainsi, dans notre cas, le poids sera l'inverse de la population de la ville.
Transformations
Transformer les données est le dernier recours, car ce faisant, vous perdez l'interprétabilité de la fonctionnalité.
Cela signifie que vous ne pouvez plus expliquer facilement ce que la fonctionnalité affiche.
Une façon pourrait être d'utiliser les transformations Box-Cox et les transformations log.
Avant que tu partes
Il peut y avoir plusieurs raisons à l'hétéroscédasticité dans vos données. Elle est également très variable d'un domaine à l'autre.
Il est donc essentiel d'en avoir connaissance avant de commencer les processus ci-dessus pour supprimer l'hétéroscédasticité.
Dans ce blog, nous avons discuté de l'homoscédasticité et de l'hétéroscédasticité et de la manière dont elles peuvent être utilisées pour implémenter plusieurs algorithmes d'apprentissage automatique.
Si vous souhaitez en savoir plus sur l'apprentissage automatique, consultez le programme Executive PG d'IIIT-B & upGrad en apprentissage automatique et IA , conçu pour les professionnels en activité et offrant plus de 450 heures de formation rigoureuse, plus de 30 études de cas et missions, IIIT -B Statut d'anciens élèves, 5+ projets de synthèse pratiques et aide à l'emploi avec les meilleures entreprises.
Qu'entend-on par régression pondérée localement dans l'apprentissage automatique ?
Quel est le test blanc d'hétéroscédasticité ?
Si vous avez besoin que votre variable indépendante ait un effet interactif et non linéaire sur la variance, l'utilisation d'un test blanc est préférable pour vérifier l'hétéroscédasticité. Cependant, le test blanc, étant un test asymptotique, est préféré uniquement dans le cas de grands échantillons. Le processus d'hétéroscédasticité peut être une fonction d'une ou plusieurs de vos variables indépendantes à l'aide du test de White. Il est comparable au test de Breusch-Pagan, la seule différence étant que le test de White permet une influence non linéaire et interactive de la variable indépendante sur la variance d'erreur.
Quelle est exactement l'hypothèse nulle d'hétéroscédasticité ?
L'existence d'une valeur aberrante dans les données entraîne une hétéroscédasticité. L'hétéroscédasticité peut également se produire lorsque des variables sont omises du modèle. L'hétéroscédasticité n'implique que deux hypothèses : l'hypothèse nulle et l'hypothèse alternative. Lors de l'application du test de White, des tests de Breusch-Pagan ou de Cook-Weisberg pour vérifier l'hétéroscédasticité, l'hypothèse nulle est vraie si les variances des erreurs sont égales. Une hypothèse alternative se produit lorsque les variances des erreurs ne sont pas identiques.