
Podstawowa architektura CNN: wyjaśnienie 5 warstw splotowych sieci neuronowych
Opublikowany: 2020-12-07Spis treści
Wstęp
W ciągu ostatnich kilku lat w branży IT pojawiło się ogromne zapotrzebowanie na niegdyś określony zestaw umiejętności znany jako Deep Learning. Głębokie uczenie podzbiór uczenia maszynowego, który składa się z algorytmów inspirowanych funkcjonowaniem ludzkiego mózgu lub sieci neuronowych.
Struktury te nazywane są sieciami neuronowymi. Uczy komputer robić to, co naturalnie przychodzi ludziom. Głębokie uczenie, istnieje kilka rodzajów modeli, takich jak sztuczne sieci neuronowe (ANN), autokodery, rekurencyjne sieci neuronowe (RNN) i uczenie ze wzmacnianiem. Ale istnieje jeden konkretny model, który wniósł duży wkład w polu widzenia komputerowego i analizy obrazu, a mianowicie Convolutional Neural Networks (CNN) lub ConvNets.
CNN to klasa głębokich sieci neuronowych, które mogą rozpoznawać i klasyfikować określone cechy obrazów i są szeroko stosowane do analizy obrazów wizualnych. Ich zastosowania obejmują rozpoznawanie obrazu i wideo, klasyfikację obrazu, analizę obrazu medycznego, widzenie komputerowe i przetwarzanie języka naturalnego.
Termin „splot” w CNN oznacza matematyczną funkcję splotu, która jest specjalnym rodzajem operacji liniowej, w której dwie funkcje są mnożone w celu uzyskania trzeciej funkcji, która wyraża, w jaki sposób kształt jednej funkcji jest modyfikowany przez drugą. Mówiąc prościej, dwa obrazy, które mogą być reprezentowane jako macierze, są mnożone w celu uzyskania wyniku używanego do wyodrębnienia cech z obrazu.
Ucz się uczenia maszynowego online z najlepszych światowych uniwersytetów — studiów magisterskich, programów podyplomowych dla kadry kierowniczej oraz zaawansowanego programu certyfikacji w zakresie uczenia maszynowego i sztucznej inteligencji, aby przyspieszyć swoją karierę.
Dowiedz się: Wprowadzenie do głębokiego uczenia i sieci neuronowych

Podstawowa architektura
Istnieją dwie główne części architektury CNN
- Narzędzie konwolucji, które oddziela i identyfikuje różne cechy obrazu do analizy w procesie zwanym wyodrębnianiem cech
- W pełni połączona warstwa, która wykorzystuje dane wyjściowe z procesu splotu i przewiduje klasę obrazu na podstawie cech wyodrębnionych na poprzednich etapach.
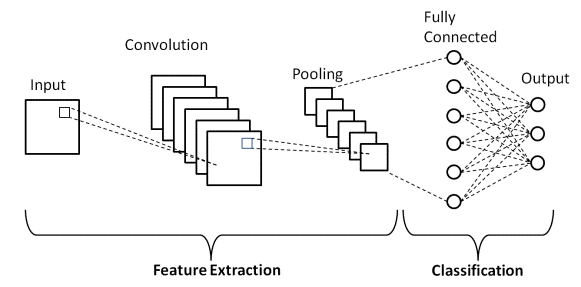
Źródło
Warstwy konwolucji
Istnieją trzy typy warstw, które składają się na CNN, które są warstwami splotowymi, warstwami puli i warstwami w pełni połączonymi (FC). Kiedy te warstwy są ułożone w stos, zostanie utworzona architektura CNN. Oprócz tych trzech warstw istnieją jeszcze dwa ważne parametry, które są zdefiniowane poniżej, czyli warstwa dropout i funkcja aktywacji.
1. Warstwa konwolucyjna
Ta warstwa jest pierwszą warstwą używaną do wyodrębniania różnych funkcji z obrazów wejściowych. W warstwie tej następuje matematyczne działanie splotu pomiędzy obrazem wejściowym a filtrem o określonej wielkości MxM. Przesuwając filtr nad obrazem wejściowym, iloczyn skalarny jest pobierany między filtrem a częściami obrazu wejściowego z uwzględnieniem rozmiaru filtra (MxM).
Wynik jest określany jako mapa funkcji, która dostarcza nam informacji o obrazie, takich jak rogi i krawędzie. Później ta mapa cech jest przesyłana do innych warstw, aby poznać kilka innych cech obrazu wejściowego.
2. Warstwa puli
W większości przypadków po warstwie splotowej następuje warstwa puli. Głównym celem tej warstwy jest zmniejszenie rozmiaru splątanej mapy obiektów w celu zmniejszenia kosztów obliczeniowych. Odbywa się to poprzez zmniejszenie połączeń między warstwami i niezależnie działa na każdej mapie obiektów. W zależności od zastosowanej metody istnieje kilka rodzajów operacji łączenia.
W Max Pooling największy element jest pobierany z mapy funkcji. Average Pooling oblicza średnią elementów w wstępnie zdefiniowanej sekcji obrazu. Całkowita suma elementów w predefiniowanej sekcji jest obliczana w Sum Pooling. Warstwa puli zwykle służy jako pomost między warstwą splotową a warstwą FC
Trzeba przeczytać: Pomysły na projekty sieci neuronowych
3. W pełni połączona warstwa
Warstwa Fully Connected (FC) składa się z wag i odchyleń wraz z neuronami i służy do łączenia neuronów między dwiema różnymi warstwami. Warstwy te są zwykle umieszczane przed warstwą wyjściową i tworzą kilka ostatnich warstw architektury CNN.
W tym przypadku obraz wejściowy z poprzednich warstw jest spłaszczany i podawany do warstwy FC. Spłaszczony wektor przechodzi następnie kilka kolejnych warstw FC, w których zwykle odbywają się operacje na funkcjach matematycznych. Na tym etapie rozpoczyna się proces klasyfikacji.
4. Wycofanie się
Zwykle, gdy wszystkie funkcje są połączone z warstwą FC, może to spowodować nadmierne dopasowanie w uczącym zbiorze danych. Nadmierne dopasowanie występuje, gdy określony model działa tak dobrze na danych uczących, co ma negatywny wpływ na wydajność modelu, gdy jest używany na nowych danych.
Aby rozwiązać ten problem, wykorzystywana jest warstwa dropout, w której kilka neuronów jest usuwanych z sieci neuronowej podczas procesu uczenia, co powoduje zmniejszenie rozmiaru modelu. Po przejściu odrzucenia 0,3, 30% węzłów jest losowo odrzucanych z sieci neuronowej.
5. Funkcje aktywacji
Wreszcie jednym z najważniejszych parametrów modelu CNN jest funkcja aktywacji. Służą do uczenia się i przybliżania wszelkiego rodzaju ciągłych i złożonych relacji między zmiennymi sieci. Mówiąc prościej, decyduje, które informacje z modelu powinny być wysyłane w kierunku do przodu, a które nie powinny być wysyłane na końcu sieci.

Dodaje nieliniowości do sieci. Istnieje kilka powszechnie używanych funkcji aktywacji, takich jak funkcje ReLU, Softmax, tanH i Sigmoid. Każda z tych funkcji ma określone zastosowanie. W przypadku binarnego modelu CNN z klasyfikacją binarną preferowane są funkcje sigmoidalne i softmax, aw przypadku klasyfikacji wieloklasowej zwykle używa się funkcji softmax.
Architektura LeNet-5 CNN
W 1998 roku architektura LeNet-5 została przedstawiona w artykule badawczym zatytułowanym „Uczenie się oparte na gradientach stosowane do rozpoznawania dokumentów” autorstwa Yanna LeCuna, Leona Bottou, Yoshua Bengio i Patricka Haffnera. Jest to jedna z najwcześniejszych i najbardziej podstawowych architektur CNN.
Składa się z 7 warstw. Pierwsza warstwa składa się z obrazu wejściowego o wymiarach 32×32. Jest on połączony z 6 filtrami o rozmiarze 5×5, co daje wymiar 28x28x6. Druga warstwa to operacja łączenia, która filtruje rozmiar 2×2 i krok 2. Stąd wynikowy wymiar obrazu będzie 14x14x6.
Podobnie, trzecia warstwa również obejmuje operację splatania z 16 filtrami o rozmiarze 5x5, po której następuje czwarta warstwa zbiorcza o podobnym rozmiarze filtra 2x2 i kroku 2. W ten sposób wynikowy wymiar obrazu zostanie zmniejszony do 5x5x16.
Po zmniejszeniu wymiaru obrazu piąta warstwa jest w pełni połączoną warstwą splotową z 120 filtrami każdy o rozmiarze 5×5. W tej warstwie każda ze 120 jednostek w tej warstwie zostanie połączona z 400 (5x5x16) jednostkami z poprzednich warstw. Szósta warstwa jest również warstwą w pełni połączoną z 84 jednostkami.
Ostatnia siódma warstwa będzie warstwą wyjściową softmax z „n” możliwymi klasami w zależności od liczby klas w zbiorze danych.
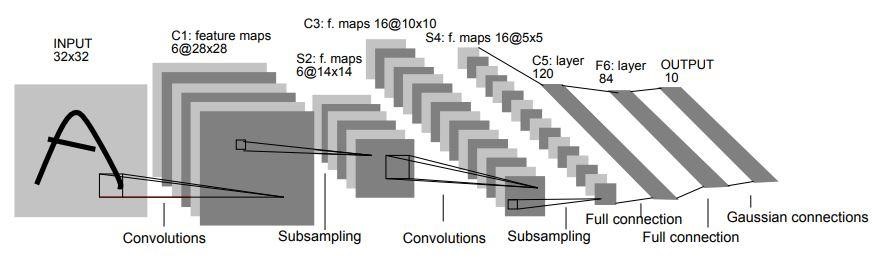
Źródło
Powyższy diagram przedstawia 7 warstw architektury LeNet-5 CNN.
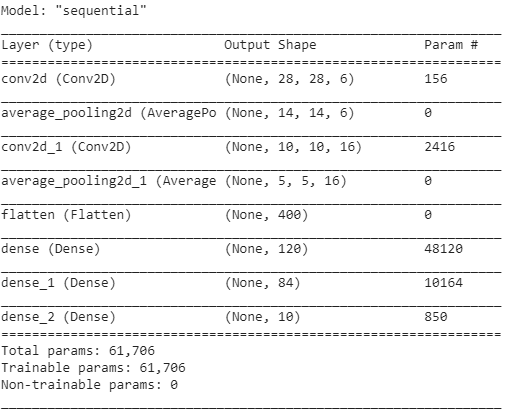
Poniżej znajdują się migawki kodu Pythona do zbudowania architektury LeNet-5 CNN przy użyciu biblioteki keras z frameworkiem TensorFlow

W programowaniu w języku Python najczęściej używanym typem modelu jest typ sekwencyjny. Jest to najłatwiejszy sposób na zbudowanie modelu CNN w Kerasie. Pozwala nam na budowanie modelu warstwa po warstwie. Funkcja „add()” służy do dodawania warstw do modelu. Jak wyjaśniono powyżej, w przypadku architektury LeNet-5 istnieją dwie pary Convolution i Pooling, po których następuje warstwa Flatten, która jest zwykle używana jako połączenie między warstwami Convolution i Dense.
Warstwy gęste to te, które są najczęściej używane jako warstwy wyjściowe. Użyta aktywacja to 'Softmax', która daje prawdopodobieństwo dla każdej klasy i sumują się one w całości do 1. Model wykona swoją predykcję w oparciu o klasę o największym prawdopodobieństwie.
Podsumowanie modelu jest wyświetlane jak poniżej.
Wniosek
Dlatego w tym artykule zrozumieliśmy podstawową strukturę CNN, jej architekturę i różne warstwy składające się na model CNN. Widzieliśmy również architektoniczny przykład bardzo znanego i tradycyjnego modelu LeNet-5 z programem Python.
Jeśli chcesz dowiedzieć się więcej o kursach uczenia maszynowego, sprawdź program Executive PG w zakresie uczenia maszynowego i sztucznej inteligencji IIIT-B i upGrad, który jest przeznaczony dla pracujących profesjonalistów i oferuje ponad 450 godzin rygorystycznych szkoleń, ponad 30 studiów przypadków i zadań, Status absolwentów IIIT-B, ponad 5 praktycznych praktycznych projektów zwieńczenia i pomoc w pracy z najlepszymi firmami.
Czym są funkcje aktywacji w CNN?
Funkcja aktywacji jest jednym z najważniejszych elementów modelu CNN. Służą do uczenia się i przybliżania dowolnej formy powiązania zmiennej sieciowej ze zmienną, która jest zarówno ciągła, jak i złożona. Mówiąc prościej, określa, które informacje o modelu powinny płynąć w kierunku do przodu, a które nie powinny płynąć na końcu sieci. Daje nieliniowość sieci. Funkcje ReLU, Softmax, tanH i Sigmoid to jedne z najczęściej wykorzystywanych funkcji aktywacji. Wszystkie te funkcje mają różne zastosowania. W przypadku dwuklasowego modelu CNN preferowane są funkcje sigmoidalne i softmax, podczas gdy softmax jest zwykle używany do klasyfikacji wieloklasowej.
Jakie są podstawowe elementy architektury konwolucyjnej sieci neuronowej?
Warstwa wejściowa, warstwa wyjściowa i wiele warstw ukrytych tworzą sieci splotowe. Neurony w warstwach sieci splotowej są ułożone w trzech wymiarach, w przeciwieństwie do standardowych sieci neuronowych (wymiary szerokości, wysokości i głębokości). Umożliwia to CNN przekształcenie trójwymiarowej objętości wejściowej w objętość wyjściową. Warstwy ukryte tworzą warstwy splotu, puli, normalizacji i w pełni połączone. Wiele warstw konwersji jest używanych w sieciach CNN do filtrowania objętości wejściowych do wyższych poziomów abstrakcji.
Jakie są korzyści ze standardowych architektur CNN?
Podczas gdy tradycyjne architektury sieciowe składały się wyłącznie z ułożonych w stos warstw splotowych, nowsze architektury analizują nowe i nowatorskie sposoby konstruowania warstw splotowych w celu poprawy wydajności uczenia się. Architektury te zapewniają ogólne zalecenia dotyczące architektury dla praktyków uczenia maszynowego w celu dostosowania się do różnych problemów z widzeniem komputerowym. Architektury te można wykorzystać jako bogate ekstraktory funkcji do klasyfikacji obrazów, identyfikacji obiektów, segmentacji obrazu i wielu innych zaawansowanych zadań.